02-DCGAN
2016年, Alec Radford 等发表的论文 《深度卷积生成对抗网络》 (简称DCGAN, 论文网址:https://arxiv.org/abs/1511.06434)中,开创性地将卷积神经网络应用到生成对抗网络的模型算法设计当中,替代了全链接层,提高了图片场景里训练的稳定性。
DCGAN这篇论文展示了卷积层如何与GAN一起使用,并为此提供了一系列架构指南。这篇论文还讨论了 GAN 特征的可视化、潜在空间插值、利用判别器特征来训练分类器、评估结果等问题。在研究GAN过程中,推荐仔细阅读此论文
.
<<Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks>>DCGAN论文中对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度.
DCGAN的定义:
DCGAN就是将CNN和原始的GAN结合到了一起,生成模型和判别模型都运用了深度卷积神经网络的生成对抗网络。DCGAN将GAN与CNN相结合,奠定之后几乎所有GAN的基本网络架构。 DCGAN极大地提升了原始GAN训练的稳定性以及生成结果质量
。
DCGAN的改进:
DCGAN主要是在网络架构上改进了原始GAN,DCGAN的生成器与判别器都利用CNN架构替换了原始GAN的全连接网络,主要改进之处有如下4个方面:
- DCGAN的生成器和判别器都舍弃了CNN的池化层,判别器保留CNN的整体架构,生成器则是将卷积层替换成了反卷积层(ConvTranspose2d) ;
- 在判别器和生成器中使用了Batch Normalization(BN)层,这有助于处理初始化不良导致的训练问题,加速模型训练,提升了训练的稳定性 (要注意, 在生成器的输出层和判别器的输入层不使用BN层 );
- 在生成器中除输出层使用Tanh()激活函数,其余层全部使用ReLU激活函数;在判别器中,除输出层外所有层都使用LeakyReLU激活函数,防止梯度稀疏。这一点我们已在基础GAN中使用;
- 在生成器中除输出层使用Tanh()激活函数,其余层全部使用ReLU激活函数;在判别器中,除输出层外所有层都使用LeakyReLU激活函数,防止梯度稀疏。这一点我们已在基础GAN中使。
DCGAN的设计:
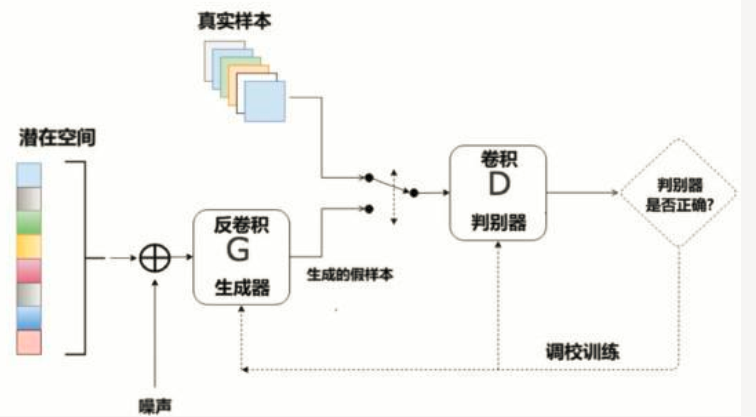
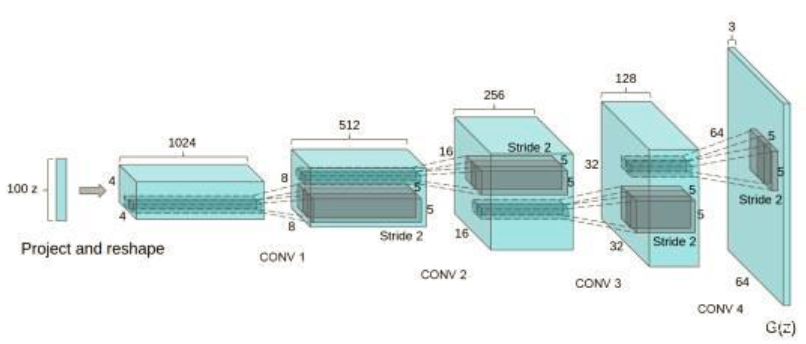
DCGAN的设计技巧:
- 取消所有pooling层:G网络中使用转置卷积(transposed convolutional layer)进行上采样, D网络中用加入stride的卷积代替pooling。
- 去掉FC层,使网络变为全卷积网络 ;
- G网络中使用ReLU作为激活函数,最后一层使用tanh
- D网络中使用LeakyReLU作为激活函数
DCGAN的代码(Pytorch实现)


1 import torch 2 import torch.nn as nn 3 import torch.nn.functional as F 4 import torch.optim as optim 5 import numpy as np 6 import matplotlib.pyplot as plt 7 import torchvision 8 from torchvision import transforms 9 10 import time 11 12 transform = transforms.Compose([ 13 transforms.ToTensor(), 14 transforms.Normalize(mean=0.5, std=0.5) 15 ]) 16 17 train_ds = torchvision.datasets.MNIST('data/', 18 train=True, 19 transform=transform, 20 download=True) 21 22 train_dl = torch.utils.data.DataLoader(train_ds, batch_size=64, shuffle=True) 23 24 #定义生成器 25 class Generator(nn.Module): 26 def __init__(self): 27 super(Generator, self).__init__() 28 self.linear1 = nn.Linear(100, 7*7*256) 29 self.bn1 = nn.BatchNorm1d(7*7*256) 30 self.deconv1 = nn.ConvTranspose2d(256, 128, kernel_size=(3, 3), padding=1) 31 self.bn2 = nn.BatchNorm2d(128) 32 self.deconv2 = nn.ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=2, padding=1) 33 self.bn3 = nn.BatchNorm2d(64) 34 self.deconv3 = nn.ConvTranspose2d(64, 1, kernel_size=(4, 4), stride=2, padding=1) 35 36 def forward(self, x): 37 38 x = F.relu(self.linear1(x)) # 64, 100 --> 64, 7*7*256 39 x = self.bn1(x) # 64, 7*7*256 --> 64, 7*7*256 40 x = x.view(-1, 256, 7, 7) # 64, 7*7*256 --> 64, 256, 7*7 41 x = F.relu(self.deconv1(x)) # 64, 256, 7*7 --> 64, 128, 7*7 42 x = self.bn2(x) # 64, 128, 7*7 --> 64, 128, 7*7 43 x = F.relu(self.deconv2(x)) # 64, 128, 7*7 --> 64, 64, 14*14 44 x = self.bn3(x) # 64, 64, 14*14 --> 64, 64, 14*14 45 x = torch.tanh(self.deconv3(x)) # 64, 64, 14*14 --> 64, 1, 28*28 46 return x 47 48 print(Generator) 49 50 # 定义判别器 51 class Discriminator(nn.Module): 52 def __init__(self): 53 super(Discriminator, self).__init__() 54 55 self.conv1 = nn.Conv2d(1, 64, 3, 2) 56 self.conv2 = nn.Conv2d(64, 128, 3, 2) 57 self.bn = nn.BatchNorm2d(128) 58 self.fc = nn.Linear(128*6*6, 1) 59 60 def forward(self, x): 61 # 判别器的损失加入了dropout,是为了防止判别器学习过强,导致生成器学习过弱,无法形成对抗学习 62 x = F.dropout2d(F.leaky_relu(self.conv1(x)), p=0.3) 63 x = F.dropout2d(F.leaky_relu(self.conv2(x)), p=0.3) 64 x = self.bn(x) 65 x = x.view(-1, 128*6*6) 66 x = torch.sigmoid(self.fc(x)) 67 return x 68 69 device = "cuda" if torch.cuda.is_available() else "cpu" 70 #device = "cpu" 71 gen = Generator().to(device) 72 dis = Discriminator().to(device) 73 74 loss_fn = torch.nn.BCELoss() # 损失函数 75 d_optimizer = torch.optim.Adam(dis.parameters(), lr=1e-5) 76 g_optimizer = torch.optim.Adam(gen.parameters(), lr=1e-4) 77 78 def generate_and_save_images(model, epoch, test_input): 79 predictions = np.squeeze(model(test_input).cpu().numpy()) 80 fig = plt.figure(figsize=(4, 4)) 81 for i in range(predictions.shape[0]): 82 plt.subplot(4, 4, i+1) 83 plt.imshow((predictions[i] + 1)/2, cmap='gray') 84 plt.axis('off') 85 plt.savefig('./DCGAN_Image/image_at_epoch_{:04d}.png'.format(epoch)) 86 plt.show() 87 plt.close() 88 89 # 绘制loss函数 90 def D_G_loss_plot(D_loss, G_loss, epotchs): 91 92 fig = plt.figure(figsize=(4, 4)) 93 94 plt.plot(epotchs, D_loss, label='D_loss') 95 plt.plot(epotchs, G_loss, label='G_loss') 96 plt.legend() 97 98 plt.title("D_G_Loss") 99 plt.savefig('./DCGAN_Image/loss_at_epoch_{:04d}.png'.format(epotchs[len(epotchs)-1])) 100 plt.close() 101 102 test_input = torch.randn(16, 100, device=device) 103 104 D_loss = [] 105 G_loss = [] 106 epochs = [] 107 108 #开始训练 109 for epoch in range(1000): 110 111 epoch_start = time.time() 112 113 D_epoch_loss=0 114 G_epoch_loss=0 115 count = len(train_dl.dataset) 116 for step, (img, _) in enumerate(train_dl): 117 img = img.to(device) 118 size=img.shape[0] 119 random_seed = torch.randn(size, 100, device=device) # 64*100 120 121 d_optimizer.zero_grad() 122 real_output = dis(img) 123 d_real_loss = loss_fn(real_output, torch.ones_like(real_output, device=device)) 124 d_real_loss.backward() 125 126 generated_img = gen(random_seed) 127 fake_output = dis(generated_img.detach()) 128 d_fake_loss = loss_fn(fake_output, torch.zeros_like(fake_output, device=device)) 129 d_fake_loss.backward() 130 131 disc_loss = d_real_loss + d_fake_loss 132 d_optimizer.step() 133 134 g_optimizer.zero_grad() 135 fake_output = dis(generated_img) 136 gen_loss = loss_fn(fake_output, torch.ones_like(fake_output, device=device)) 137 gen_loss.backward() 138 g_optimizer.step() 139 140 with torch.no_grad(): 141 D_epoch_loss += disc_loss.item() 142 G_epoch_loss += gen_loss.item() 143 144 epoch_finish = time.time() 145 # print("Time cost for every epoch: {:2f}s.".format(epoch_finish-epoch_start)) 146 147 with torch.no_grad(): 148 D_epoch_loss /= count 149 G_epoch_loss /= count 150 D_loss.append(D_epoch_loss) 151 G_loss.append(G_epoch_loss) 152 epochs.append(epoch) 153 154 print('Epoch: %d, D_loss: %.6f, G_loss: %.6f, Time: %.3fs' %(epoch, D_epoch_loss, G_epoch_loss, epoch_finish-epoch_start)) 155 156 generate_and_save_images(gen, epoch, test_input) 157 158 D_G_loss_plot(D_loss, G_loss, epochs)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号