
01-GAN
生成对抗网络(Generative Adversarial Networks,简称GAN)是当前人工智能学界最为重要的研究热点之一。其突出的生成能力不仅可用于生成各类图像和自然语言数据,还启发和推动了各类半监督学习和无监督学习任务的发展。
2014年,还在蒙特利尔读博士的Ian Goodfellow发表了论文《Generative Adversarial Networks》 (网址:https://arxiv.org/abs/1406.2661),将生成对抗网络引入深度学习领域。 2016年, GAN热潮席卷AI领域顶级会议,从ICLR到NIPS,大量高质量论文被发表和探讨。 Yann LeCun曾评价GAN是“20年来机器学习领域最酷的想法”。
机器学习的模型可大体分为两类,生成模型(Generative Model)和判别模型(Discriminative Model)。判别模型需要输入变量 ,通过某种模型来预测 。生成模型是给定某种隐含信息,来随机产生观测数据。
GAN是一种深度神经网络架构,由一个生成网络和一个判别网络组成。生成网络产生“假”数据,并试图欺骗判别网络;判别网络对生成数据进行真伪鉴别,试图正确识别所有“假”数据。在训练迭代的过程中,两个网络持续地进化和对抗,直到达到平衡状态(参考纳什均衡),判别网络无法再识别“假”数据,训练结束。
GAN模型主要包括了两个部分: 生成模型(Generative Model)和判别模型(Discriminative Model), 也常叫做生成器(generator)与判别器(discriminator)。
生成器主要用来学习真实图像分布从而让自身生成的图像更加真实,以骗过判别器。 判别器则需要对接收的图片进行真假判别。 在训练过程中,生成器努力地让生成的图像更加真实,而判别器则努力地去识别出图像的真假,这个过程相当于一个二人博弈,随着时间的推移,生成器和判别器在不断地进行对抗。 最终两个网络达到了一个动态均衡:生成器生成的图像接近于真实图像分布,而判别器识别不出真假图像,对于给定图像的预测为真的概率基本接近 0.5(相当于随机猜测类别)。
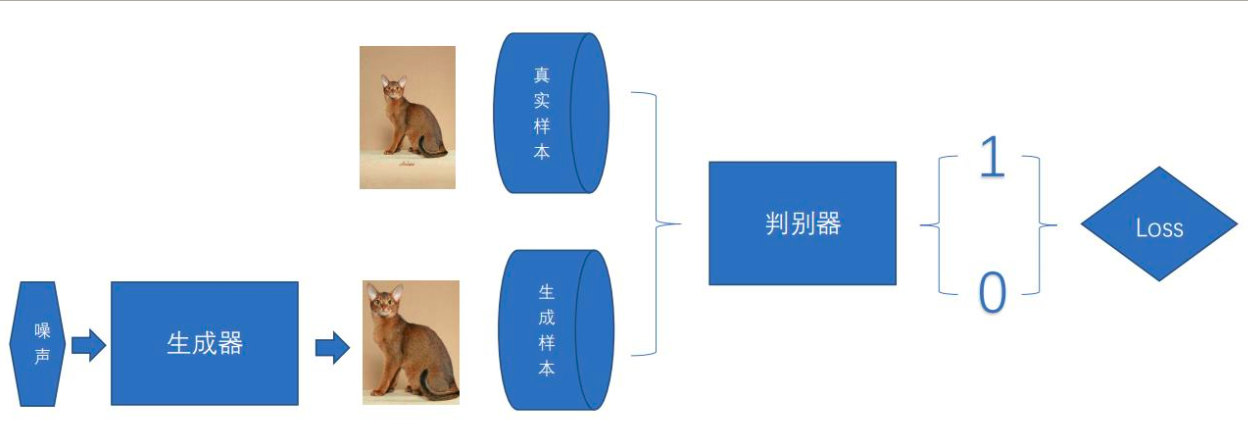
GAN原理:
GAN设计的关键在于损失函数的处理。对于判别模型,损失函数是容易定义的,判别器主要用来判断一张图片是真实的还是生成的,显然这是一个二分类问题,在Pytorch深度学习入门与实战课程已经演示过如果创建一个分类模型. 对于生成模型,损失函数的定义就不是那么容易。我们希望生成器可以生成接近真实的图片,对于生成的图片是否像真实的,我们人类肉眼容易判断,但具体到代码中,往往是一个抽象的,难以数学公理化定义的范式.针对这个问题,我们不妨把生成模型的输出,交给判别模型处理,让判别器来判断这是一个真实的图像还是假的图像,因为深度学习模型很适合做图片的分类。这样就将生成对抗网络中的两大类模型生成器generator与判别器discriminator紧密地联合在了一起
GAN的算法流程:
GAN这个结构的最精妙之处在于对生成模型损失函数的处理,这里以生成图片为例,说明其整个算法流程。假设我们有两个网络:
G(Generator)和 D(Discriminator)。
- G 是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
- D 是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x, x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
在训练过程中,将随机噪声输入生成网络G,得到生成的图片;判别器接收生成的图片和真实的图片,并尽量将两者区分开来。在这个计算过程中,能否正确区分生成的图片和真实的图片将作为判别器的损失,而能否生成近似真实的图片并使得判别器将生成的图片判定为真将作为生成器的损失。
生成器的损失是通过判别器的输出来计算的,而判别器的输出是一个概率值,我们可以通过交叉熵计算
。
GAN公式:
Goodfellow从理论上证明了GAN算法的收敛性以及在模型收敛时生成数据具有和真实数据相同的分布。GAN的公式如图:
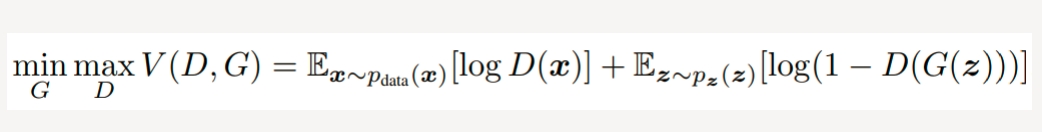
公式中x表示真实图片,z表示输入G网络的噪声,G(z)表示G网络生成的图片,D(*)表示D网络判断图片是否真实的概率。
GAN公式的理解:
对于判别器 D , 我们希望它可以正确识别真实数据,这便是GAN公式的前半部分
:
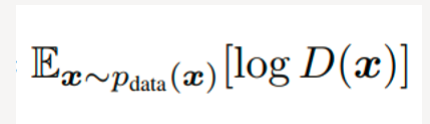
其中 表示期望 Ex ~pdata(x)从 Pdata中获取。 x 表示真实的数据(图片),p_data 表示真实数据的分布。 所以,这一部分 Ex ~pdata(x)[logD(x)]的涵义就是 :判别器判别出真实数据的概率。我们的优化目标是希望这个概率越大越好。也就是说 对于服从 Pdata分布的图片 x ,判别器应该给出预测结果 D(x)=1.
了解了GAN公式的前半部分,来看后半部分:
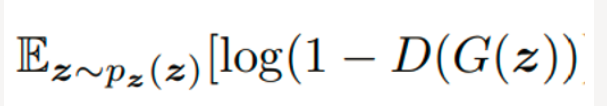
这里 EZ~Pz(z)表示期望 z 是从 Pz (z) 分布中获取 ,z 表示随机的噪声,PZ(z) 表示生成随机噪声的分布.
对于 判别器 D 来说,如果其输入的是生成的数据,也即是 D(G(z))判别器的目标是最小化 D(G(z)), 希望它被判定为 0 ,也就是希望log(1-D(G(z)))越大越好。这里 对数函数 在其定义域内是单调递增函数,数据取对数不改变数据间的相对关系,使用log后,可放大损失,便于计算和优化。
对于 生成器 G 来说,它希望生成的数据被判别器识别为真,也就希望是 D(G(z)) = 1,也就是希望
log(1-D(G(z)))越小越好,希望这部分最小化。
可以看到 判别器D 和 生成器 G 对
log(1-D(G(z)))优化目标是相反的,这就体现在公式中的:
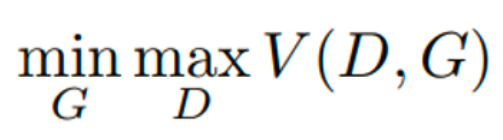
总结起来,对于 判别器 D,我们希望最大化
log(D(x))和log(1-D(G(z)))从而达到最大化
V(D,G).
对于 生成器 G其训练目标是最小化log(1-D(G(z))),从而达到最小化V(D,G)的目标.
因此,公式中 表示:从判别器 D 的角度,希望最大化
V(D,G),从生成器 G 的角度, 希望最小化V(D,G);
表示:从判别器 D 的角度,希望最大化
V(D,G),从生成器 G 的角度, 希望最小化V(D,G);
GAN应用领域:
- 图像生成:生成一些假的数据,比如海报中的人脸
- 图像增强:从分割图生成假的真实街景,方便训练无人汽车。
- 风格化和艺术的图像创造:转换图像风格,修补图像
- 声音的转换:一个人的声音转为另一个人的声音;去除噪声。
GAN的代码(pytorch实现)


1 import torch 2 import torch.nn as nn 3 import torch.nn.functional as F 4 import torch.optim as optim 5 import numpy as np 6 import matplotlib.pyplot as plt 7 import torchvision 8 from torchvision import transforms 9 10 # 1.) 数据准备 11 # 对数据做归一化 (-1, 1) 12 transform = transforms.Compose([ 13 transforms.ToTensor(), # 0-1; channel, hight, width, 14 transforms.Normalize(0.5, 0.5) 15 ]) 16 17 train_ds = torchvision.datasets.MNIST('data', 18 train=True, 19 transform=transform, 20 download=True) 21 22 print(train_ds.class_to_idx) 23 print(train_ds.classes) 24 print() 25 26 dataloader = torch.utils.data.DataLoader(train_ds, batch_size=64, shuffle=True) 27 28 # len(dataloader) = 数据集的样本个数/ batch_size 29 # iter() 迭代器函数 30 # next() 以此遍历迭代器对象,并返回 31 32 print(iter(dataloader)) 33 print(next(iter(dataloader))) 34 imgs, _ = next(iter(dataloader)) 35 36 print(imgs.shape) 37 38 39 # 2.)定义生成器 40 # 输入是长度为 100 的 噪声(正态分布随机数) 41 # 输出为(1, 28, 28)的图片 42 # linear 1 : 100----256 43 # linear 2: 256----512 44 # linear 2: 512----28*28 45 # reshape: 28*28----(1, 28, 28) 46 class Generator(nn.Module): 47 def __init__(self): 48 super(Generator, self).__init__() 49 self.main = nn.Sequential( 50 nn.Linear(100, 256), 51 nn.ReLU(), 52 nn.Linear(256, 512), 53 nn.ReLU(), 54 nn.Linear(512, 28*28), 55 nn.Tanh() # -1, 1之间 56 ) 57 def forward(self, x): # x 表示长度为100 的noise输入 58 img = self.main(x) 59 img = img.view(-1, 28, 28) 60 return img 61 62 63 # 3.)定义判别器 64 ## 输入为(1, 28, 28)的图片 输出为二分类的概率值,输出使用sigmoid激活 0-1 65 # BCEloss计算交叉熵损失 66 67 # 问题1: 68 # 为什么生成器用激活函数Relu,判别器用LeakyRelu? 69 70 # 问题2: 71 # 为什么生成器最后的输出用激活函数tanh,判别器用Sigmoid函数? 72 73 # nn.LeakyReLU f(x) : x>0 输出 0, 如果x<0 ,输出 a*x a表示一个很小的斜率,比如0.1 74 # 判别器中一般推荐使用 LeakyReLU 75 class Discriminator(nn.Module): 76 def __init__(self): 77 super(Discriminator, self).__init__() 78 self.main = nn.Sequential( 79 nn.Linear(28*28, 512), 80 nn.LeakyReLU(), 81 nn.Linear(512, 256), 82 nn.LeakyReLU(), 83 nn.Linear(256, 1), 84 nn.Sigmoid() 85 ) 86 def forward(self, x): 87 x = x.view(-1, 28*28) 88 x = self.main(x) 89 return x 90 91 # 4.) 初始化模型、优化器及损失计算函数 92 # 设备 93 94 device = 'cuda' if torch.cuda.is_available() else 'cpu' 95 gen = Generator().to(device) 96 dis = Discriminator().to(device) 97 98 # 优化器 99 d_optim = torch.optim.Adam(dis.parameters(), lr=0.0001) 100 g_optim = torch.optim.Adam(gen.parameters(), lr=0.0001) 101 # 损失函数 102 loss_fn = torch.nn.BCELoss() 103 104 # 5. 绘图函数 105 def gen_img_plot(model, epoth, test_input): 106 prediction = np.squeeze(model(test_input).detach().cpu().numpy()) 107 fig = plt.figure(figsize=(4, 4)) 108 for i in range(16): 109 plt.subplot(4, 4, i+1) 110 plt.imshow((prediction[i] + 1)/2) 111 plt.axis('off') 112 113 plt.savefig('./Data_MNIST/image_at_epoch_{:04d}.png'.format(epoth)) 114 plt.show() 115 plt.close() 116 117 118 test_input = torch.randn(16, 100, device=device) 119 120 # 绘制loss函数 121 def D_G_loss_plot(D_loss, G_loss, epotchs): 122 123 fig = plt.figure(figsize=(4, 4)) 124 125 plt.plot(epotchs, D_loss, label='D_loss') 126 plt.plot(epotchs, G_loss, label='G_loss') 127 plt.legend() 128 129 plt.title("D_G_Loss") 130 plt.savefig('./Data_MNIST/loss_at_epoch_{:04d}.png'.format(epotchs[len(epotchs)-1])) 131 132 plt.close() 133 134 135 # 6. GAN的训练 136 D_loss = [] 137 G_loss = [] 138 epochs = [] 139 140 # 问题3:batch、epoch的含义及区别? 141 142 # 训练循环 143 for epoch in range(1000): 144 d_epoch_loss = 0 145 g_epoch_loss = 0 146 147 count = len(dataloader) # count = 数据集的样本个数/batch_size 148 149 for step, (img, _) in enumerate(dataloader): 150 img = img.to(device) 151 size = img.size(0) 152 random_noise = torch.randn(size, 100, device=device) 153 154 d_optim.zero_grad() #梯度清零 155 156 real_output = dis(img) # 判别器输入真实的图片,real_output对真实图片的预测结果 157 d_real_loss = loss_fn(real_output, 158 torch.ones_like(real_output)) # 得到判别器在真实图像上的损失 159 d_real_loss.backward() # 反向传播求解梯度 160 161 gen_img = gen(random_noise) 162 # 判别器输入生成的图片,fake_output对生成图片的预测 163 # 问题: 生成器的参数梯度为什么要截断,不参与训练呢? 164 fake_output = dis(gen_img.detach()) 165 d_fake_loss = loss_fn(fake_output, 166 torch.zeros_like(fake_output)) # 得到判别器在生成图像上的损失 167 d_fake_loss.backward() 168 169 d_loss = d_real_loss + d_fake_loss 170 d_optim.step() #更新权重参数 171 172 g_optim.zero_grad() 173 fake_output = dis(gen_img) 174 g_loss = loss_fn(fake_output, 175 torch.ones_like(fake_output)) # 生成器的损失 176 g_loss.backward() 177 g_optim.step() 178 179 with torch.no_grad(): 180 d_epoch_loss += d_loss 181 g_epoch_loss += g_loss 182 183 with torch.no_grad(): 184 d_epoch_loss /= count 185 g_epoch_loss /= count 186 D_loss.append(d_epoch_loss.item()) 187 G_loss.append(g_epoch_loss.item()) 188 epochs.append(epoch) 189 print('Epoch: %d, D_loss: %.6f, G_loss: %.6f' %(epoch, d_epoch_loss.item(), g_epoch_loss.item())) 190 gen_img_plot(gen, epoch, test_input) 191 192 193 D_G_loss_plot(D_loss, G_loss, epochs)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号