
08-模型加速之轻量化模型(二) 深度可分离:MobileNet
SqueezeNet虽在一定程度上减少了卷积计算量,但仍然使用传统的卷积计算方式,而在其后的MobileNet利用了更为高效的深度可分离卷积的方式,进一步加速了卷积网络在移动端的应用。
为了更好地理解深度可分离卷积,在本节首先回顾标准的卷积计算过程,然后详细讲解深度可分离卷积过程,以及基于此结构的两个网络结构MobileNet v1与MobileNet v2。
1.)标准卷积
假设当前特征图大小为Ci×H×W,需要输出的特征图大小为Co ×H×W,卷积核大小为3×3,Padding为1,则标准卷积的计算过程如图7.5所示。
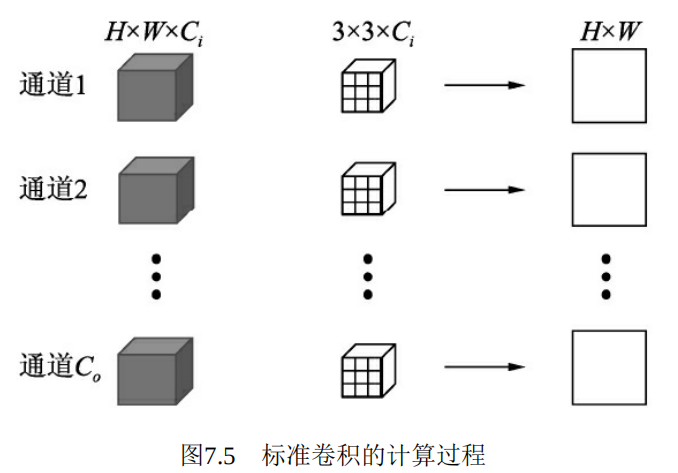
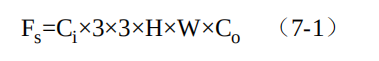
2.)深度可分离卷积
标准卷积在卷积时,同时考虑了图像的区域与通道信息,那么为什么不能分开考虑区域与通道呢?基于此想法,诞生了深度可分离卷积(Depthwise Separable Convolution),将卷积的过程分为逐通道卷积与逐点1×1卷积两步。虽然深度可分离卷积将一步卷积过程扩展为两步,但减少了冗余计算,因此总体上计算量有了大幅度降低。MobileNet也大量采用了深度可分离卷积作为基础单元。
逐通道卷积的计算过程如图7.6所示,对于一个通道的输入特征H×W,利用一个3×3卷积核进行点乘求和,得到一个通道的输出H×W。然后,对于所有的输入通道Ci,使用Ci个3×3卷积核即可得到Ci×H×W大小的输出。
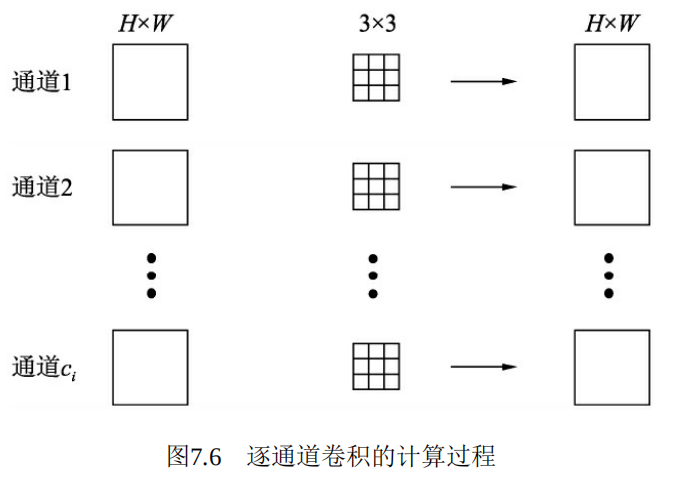
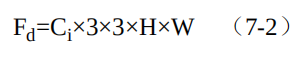
由于逐通道卷积通道间缺少特征的融合,并且通道数无法改变,因此后续还需要继续连接一个逐点的1×1的卷积,一方面可以融合不同通道间的特征,同时也可以改变特征图的通道数。由于这里1×1卷积的输入特征图大小为Ci×H×W,输出特征图大小为Co ×H×W,因此这一步的总计算量如式(7-3)所示。
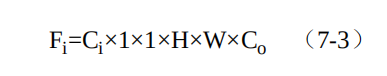
综合这两步,可以得到深度可分离卷积与标准卷积的计算量之比,如式(7-4)所示。
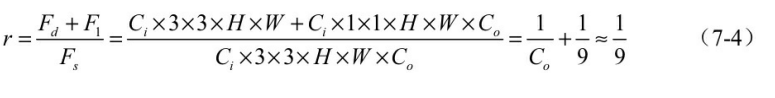
可以看到,虽然深度可分离卷积将卷积过程分为了两步,但凭借其轻量的卷积方式,总体计算量约等于标准卷积的1/9,极大地减少了卷积过程的计算量。
MobileNet v1使用的深度可分离模块的具体结构如图7.7所示。其中使用了BN层及ReLU的激活函数。值得注意的是,在此使用了ReLU6来替代原始的ReLU激活函数,将ReLU的最大输出限制在6以下。

使用ReLU6的原因主要是为了满足移动端部署的需求。移动端通常使用Float16或者Int8等较低精度的模型,如果不对激活函数的输出进行限制的话,激活值的分布范围会很大,而低精度的模型很难精确地覆盖如此大范围的输出,这样会带来精度的损失。
3.)MobileNet v1结构
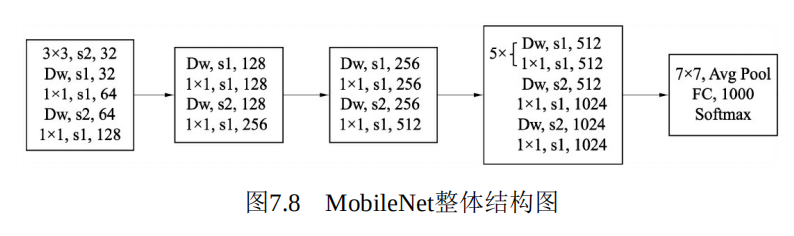
这里列出的是MobileNet v1用于物体分类的网络,可以看到网络最后利用一个全局平均池化层,送入到全连接与Softmax进行分类预测。如果用于物体检测,只需要在之前的特征图上进行特征提取即可。
在基本的结构之外,MobileNet v1还设置了两个超参数,用来控制模型的大小与计算量,具体如下:
宽度乘子:用于控制特征图的通道数,记做α,当α<1时,模型会变得更薄,可以将计算量减少为原来的α 2。


1 from torch import nn 2 3 class MobileNet(nn.Module): 4 5 def __init__(self): 6 7 super(MobileNet, self).__init__() 8 9 # 标准卷积 10 def conv_bn(dim_in, dim_out, stride): 11 12 return nn.Sequential( 13 nn.Conv2d(dim_in, dim_out, 3, stride, 1, bias=False), 14 nn.BatchNorm2d(dim_out), 15 nn.ReLU(inplace=True) 16 ) 17 18 # 深度分解卷积 19 def conv_dw(dim_in, dim_out, stride): 20 21 return nn.Sequential( 22 nn.Conv2d(dim_in, dim_in, 3, stride, 1, groups= dim_in, bias=False), # 注:参数groups的使用 23 nn.BatchNorm2d(dim_in), 24 nn.ReLU(inplace=True), 25 nn.Conv2d(dim_in, dim_out, 1, 1, 0, bias=False), 26 nn.BatchNorm2d(dim_out), 27 nn.ReLU(inplace=True), 28 ) 29 30 self.model = nn.Sequential( 31 32 conv_bn(3, 32, 2), 33 conv_dw(32, 64, 1), 34 conv_dw(64, 128, 2), 35 conv_dw(128, 128, 1), 36 conv_dw(128, 256, 2), 37 conv_dw(256, 256, 1), 38 conv_dw(256, 512, 2), 39 conv_dw(512, 512, 1), 40 conv_dw(512, 512, 1), 41 conv_dw(512, 512, 1), 42 conv_dw(512, 512, 1), 43 conv_dw(512, 512, 1), 44 conv_dw(512, 512, 1), 45 conv_dw(512, 1024, 2), 46 conv_dw(1024, 1024, 1), 47 nn.AvgPool2d(7) 48 ) 49 50 self.fc = nn.Linear(1024, 1000) 51 52 def forward(self, x): 53 54 x = self.model(x) 55 x = x.view(-1, 1024) 56 x = self.fc(x) 57 58 return x 59 60 61 62
test_v1.py
1 import torch 2 from mobilenet_v1 import MobileNet 3 4 mobilenet = MobileNet().cuda() 5 6 print(mobilenet) 7 8 input = torch.randn(1, 3, 224, 224).cuda() 9 output = mobilenet(input) 10 11 print(output.shape)
1 MobileNet( 2 (model): Sequential( 3 (0): Sequential( 4 (0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) 5 (1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 6 (2): ReLU(inplace=True) 7 ) 8 (1): Sequential( 9 (0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias 10 (1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 11 (2): ReLU(inplace=True) 12 (3): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) 13 (4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 14 (5): ReLU(inplace=True) 15 ) 16 (2): Sequential( 17 (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=64, bias 18 (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 19 (2): ReLU(inplace=True) 20 (3): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) 21 (4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 22 (5): ReLU(inplace=True) 23 ) 24 (3): Sequential( 25 (0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, b 26 (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 27 (2): ReLU(inplace=True) 28 (3): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) 29 (4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 30 (5): ReLU(inplace=True) 31 ) 32 (4): Sequential( 33 (0): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=128, b 34 (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 35 (2): ReLU(inplace=True) 36 (3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) 37 (4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 38 (5): ReLU(inplace=True) 39 ) 40 (5): Sequential( 41 (0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, b 42 (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 43 (2): ReLU(inplace=True) 44 (3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) 45 (4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 46 (5): ReLU(inplace=True) 47 ) 48 (6): Sequential( 49 (0): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=256, b 50 (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 51 (2): ReLU(inplace=True) 52 (3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) 53 (4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 54 (5): ReLU(inplace=True) 55 ) 56 (7): Sequential( 57 (0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, b 58 (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 59 (2): ReLU(inplace=True) 60 (3): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) 61 (4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 62 (5): ReLU(inplace=True) 63 ) 64 (8): Sequential( 65 (0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, b 66 (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 67 (2): ReLU(inplace=True) 68 (3): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) 69 (4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 70 (5): ReLU(inplace=True) 71 ) 72 (9): Sequential( 73 (0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, b 74 (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 75 (2): ReLU(inplace=True) 76 (3): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) 77 (4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 78 (5): ReLU(inplace=True) 79 ) 80 (10): Sequential( 81 (0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, b 82 (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 83 (2): ReLU(inplace=True) 84 (3): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) 85 (4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 86 (5): ReLU(inplace=True) 87 ) 88 (11): Sequential( 89 (0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, b 90 (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 91 (2): ReLU(inplace=True) 92 (3): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) 93 (4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 94 (5): ReLU(inplace=True) 95 ) 96 (12): Sequential( 97 (0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, b 98 (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 99 (2): ReLU(inplace=True) 100 (3): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) 101 (4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 102 (5): ReLU(inplace=True) 103 ) 104 (13): Sequential( 105 (0): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=512, b 106 (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 107 (2): ReLU(inplace=True) 108 (3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) 109 (4): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 110 (5): ReLU(inplace=True) 111 ) 112 (14): Sequential( 113 (0): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1024 114 (1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 115 (2): ReLU(inplace=True) 116 (3): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) 117 (5): ReLU(inplace=True) 118 ) 119 (15): AvgPool2d(kernel_size=7, stride=7, padding=0) 120 ) 121 (fc): Linear(in_features=1024, out_features=1000, bias=True) 122 ) 123 torch.Size([1, 1000])
MobileNet v1总结
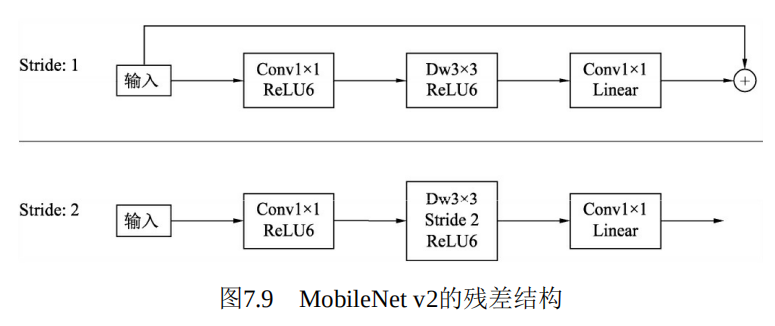
下面利用PyTorch构建MobileNet v2的残差模块,即图7.9中的stride为1的结构,新建一个mobilenet_v2_block.py文件。代码如下:
1 from torch import nn 2 3 class InvertedResidual(nn.Module): 4 5 def __init__(self, inp, oup, stride, expand_ratio): 6 7 super(InvertedResidual, self).__init__() 8 9 self.stride = stride 10 11 hidden_dim = round(inp*expand_ratio) 12 13 self.conv = nn.Sequential( 14 #1*1的逐点卷积进行升维 15 nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False), 16 nn.BatchNorm2d(hidden_dim), 17 nn.ReLU6(inplace=True), 18 19 #深度可分离模块 20 nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias= False), 21 nn.BatchNorm2d(hidden_dim), 22 nn.ReLU6(inplace=True), 23 24 # 1*1的逐点卷积进行降维 25 nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False), 26 nn.BatchNorm2d(oup) 27 ) 28 29 def forward(self, x): 30 return x +self.conv(x) 31
test.py
1 import torch 2 from mobilenet_v2_block import InvertedResidual 3 4 block = InvertedResidual(24, 24, 1, 6).cuda() 5 print(block) 6 7 8 input = torch.randn(1, 24, 56, 56).cuda() 9 output = block(input) 10 print(output.shape)
1 InvertedResidual( 2 (conv): Sequential( 3 (0): Conv2d(24, 144, kernel_size=(1, 1), stride=(1, 1), bias=False) 4 (1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 5 (2): ReLU6(inplace=True) 6 (3): Conv2d(144, 144, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=144, bias=False) 7 (4): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 8 (5): ReLU6(inplace=True) 9 (6): Conv2d(144, 24, kernel_size=(1, 1), stride=(1, 1), bias=False) 10 (7): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) 11 ) 12 ) 13 torch.Size([1, 24, 56, 56])
总体上,MobileNet v2在原结构的基础上进行了简单的修改,通过较少的计算量即可获得较高的精度,非常适合于移动端的部署。
