


数据结构
什么是数据结构?

栈

栈的实现

栈的应用


栈的应用
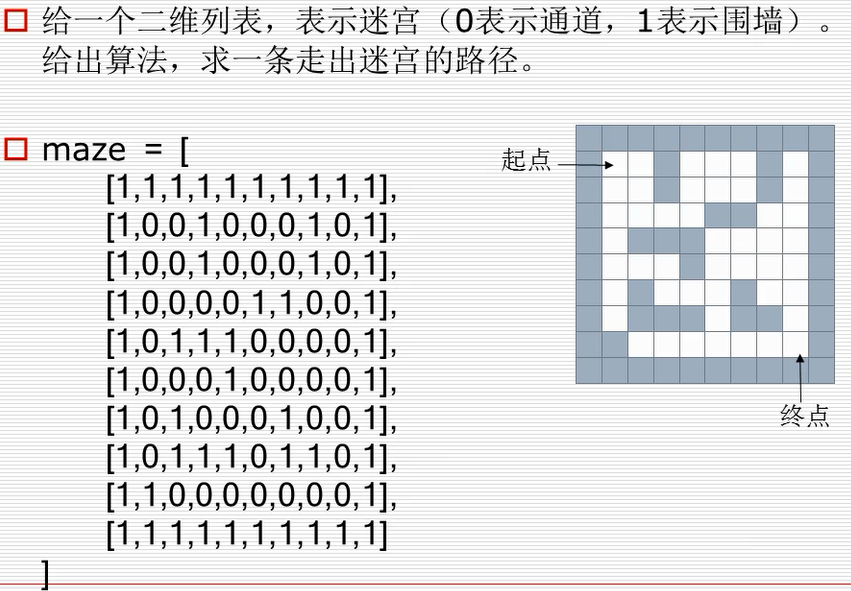

maze = [ # 迷宫
[1,1,1,1,1,1,1,1,1,1],
[1,0,0,1,0,0,0,1,0,1],
[1,0,0,1,0,0,0,1,0,1],
[1,0,0,0,0,1,1,0,0,1],
[1,0,1,1,1,0,0,0,0,1],
[1,0,0,0,1,0,0,0,0,1],
[1,0,1,0,0,0,1,0,0,1],
[1,0,1,1,1,0,1,1,0,1],
[1,1,0,0,0,0,0,0,0,1],
[1,1,1,1,1,1,1,1,1,1],
]
dirs = [ # 方向
lambda x,y:(x + 1,y), # 右
lambda x,y:(x - 1,y), # 左
lambda x,y:(x,y - 1), # 上
lambda x,y:(x,y + 1), # 下
]
def mpath(x1,y1,x2,y2):
stack = []
stack.append((x1,y1)) # 起点
while len(stack) > 0: # 栈的长度 > 0
curNode = stack[-1] # 当前节点就是栈顶元素
if curNode[0] == x2 and curNode[1] == y2: #如果当前位置就是终点了,就结束了
# 到达终点了
for p in stack:
print(p)
return True
for dir in dirs:
nextNode = dir(curNode[0],curNode[1]) # 找下一个
if maze[nextNode[0]][nextNode[1]] == 0: # maze 找到 0 可以走
# 找到了下一个位置
stack.append(nextNode) # 不管以后能不能走 也要把这步加入到栈中
maze[nextNode[0]][nextNode[1]] = -1 # 标记为已经走过,防止死循环
break
else: # 四个方向 都没有到找
maze[curNode[0]][curNode[1]] = -1 # 死路一条 ,下次别走了
stack.pop() # 回溯
print("没有路!")
return False
mpath(1,1,8,8)
效果显示:
(1, 1)
(2, 1)
(3, 1)
(4, 1)
(5, 1)
(5, 2)
(5, 3)
(6, 3)
(6, 4)
(6, 5)
(7, 5)
(8, 5)
(8, 6)
(8, 7)
(8, 8)
解决思路:

队列

队列的实现

单向队列
from collections import deque
queue = deque()
queue.append(1) # 进队
queue.append(2) # 进队
print(queue) # 打印此时的队列
print(queue.popleft()) # 打印出队 的 数
print(queue) # 打印剩下的队列
结果显示:
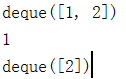
队列的实现原理
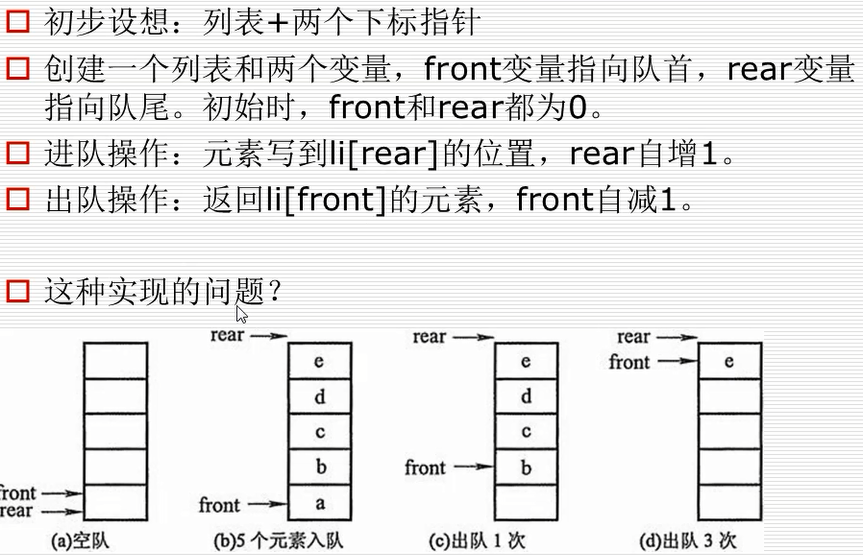
队列的实现原理----环形队列


链表
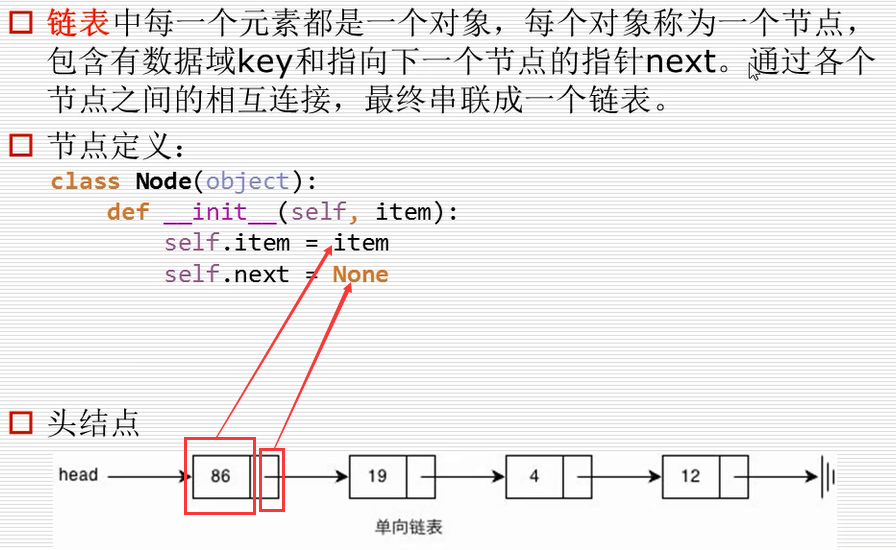
一个很不严谨的链表表示程序:
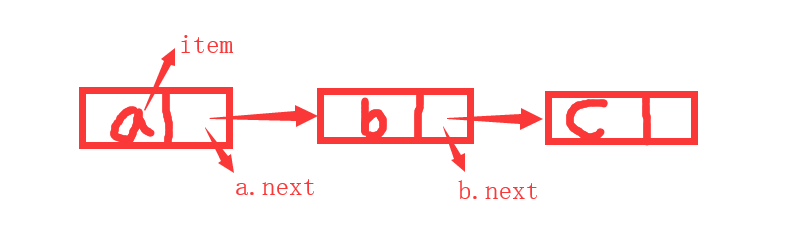
class Node(object):
def __init__(self,item):
self.item = item
self.next = None
a = Node(10)
b = Node(20)
c = Node(30)
a.next = b
b.next = c
print(a.next.item)
print(a.next.next.item)
链表的遍历
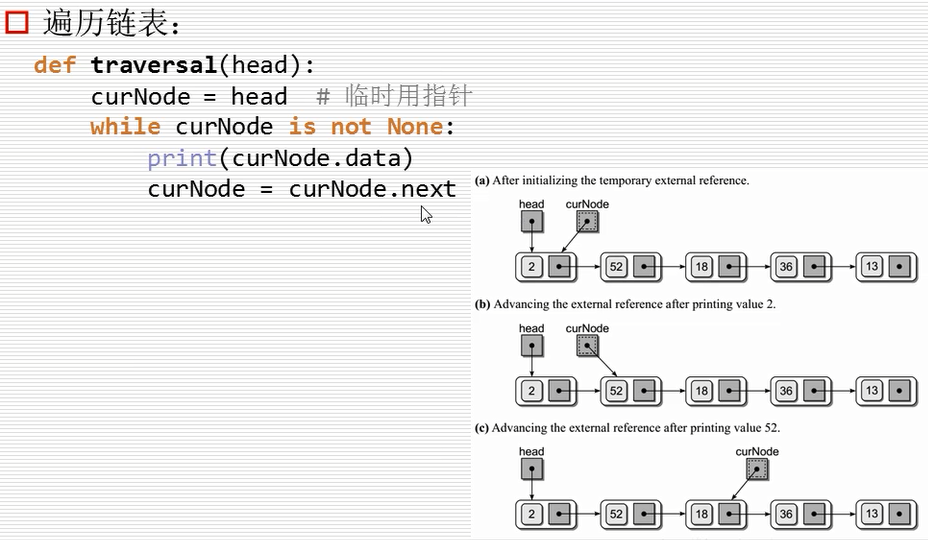
遍历的程序演示:
class Node(object):
def __init__(self,item):
self.item = item
self.next = None
head = Node(10)
head.next = Node(20)
head.next.next = Node(30)
def traversal(head):
curNode = head # 临时用指针
while curNode is not None:
print(curNode.item)
curNode = curNode.next # 指向下一个curNode
traversal(head)
演示的结果为:

链表的插入和删除
单链表
插入:


删除:


建立链表
头插法:
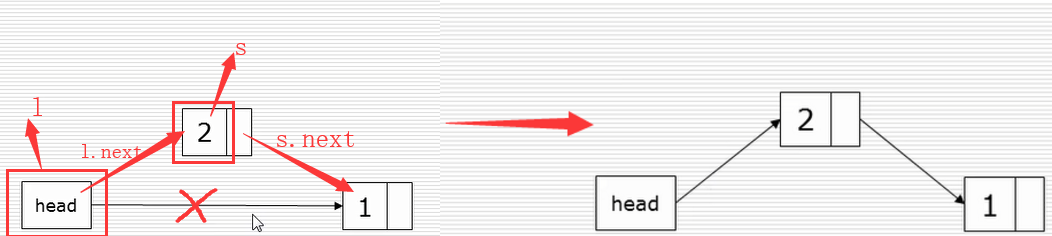

尾插法


双链表

双链表节点的插入和删除
插入



删除

尾插法

链表--分析

Python中的集合与字典(了解)


二叉树的实现


class BiTree(object): def __init__(self,data): self.data = data self.lchildren = None self.rchildren = None a = BiTree('A') b = BiTree('B') c = BiTree('C') d = BiTree('D') e = BiTree('E') f = BiTree('F') g = BiTree('G') e.lchildren = a e.rchildren = g a.rchildren = c c.lchildren = b c.rchildren = d g.rchildren = f root = e def pre_order(root): if root: print(root.data,end=' ') pre_order(root.lchildren) pre_order(root.rchildren) # pre_order(root) # 前序遍历是 先遍历左边的最遍历右边的 E A C B D G F def in_order(root): if root: in_order(root.lchildren) print(root.data,end=' ') in_order(root.rchildren) # in_order(root) # 中序遍历是 先遍历左边的,在遍历自己,在遍历右边 A B C D E G F # 中序的思路: (左边ABCD) E (右边GF) ---- (ABCD中以A为中,A的左边(为空),A的右边(BCD))E 依次类推 def post_order(root): if root: post_order(root.lchildren) post_order(root.rchildren) print(root.data,end=' ') post_order(root) # 后序遍历:先左后右,最后自己 B D C A F G E
作者:赵盼盼
出处:https://www.cnblogs.com/zhaopanpan/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
⇩ 关注或点个喜欢就行 ^_^
关注我


