

celery的使用
Celery的定义
Celery(芹菜)是一个简单、灵活且可靠的,处理大量消息的分布式系统,并且提供维护这样一个系统的必需工具。
我比较喜欢的一点是:Celery支持使用任务队列的方式在分布的机器、进程、线程上执行任务调度。然后我接着去理解什么是任务队列。
任务队列
任务队列是一种在线程或机器间分发任务的机制。
消息队列
消息队列的输入是工作的一个单元,称为任务,独立的职程(Worker)进程持续监视队列中是否有需要处理的新任务。
Celery 用消息通信,通常使用中间人(Broker)在客户端和职程间斡旋。这个过程从客户端向队列添加消息开始,之后中间人把消息派送给职程,职程对消息进行处理。如下图所示:
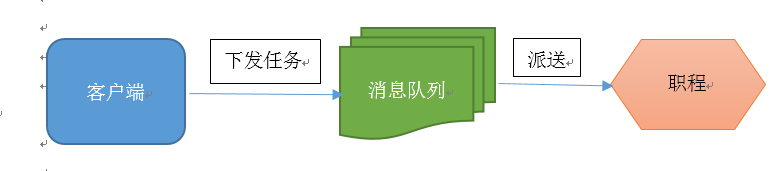
Celery 系统可包含多个职程和中间人,以此获得高可用性和横向扩展能力。
Celery的架构
Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
消息中间件
Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成,包括,RabbitMQ,Redis,MongoDB等,这里我先去了解RabbitMQ,Redis。
任务执行单元
Worker是Celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中
任务结果存储
Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括Redis,MongoDB,Django ORM,AMQP等
celery的简单示例
首先安装Celery
pip install celery
因为涉及到消息中间件,所以需要选择一个broker安装
RabbitMQ安装:
参考:http://www.cnblogs.com/cwp-bg/p/8397529.html
redis安装:
pip install redis
为了测试Celery能否工作,我运行了一个最简单的任务,编写tasks.py,如下:
import time from celery import Celery app = Celery('tasks', broker='redis://192.168.10.48:6379', backend='redis://192.168.10.48:6379') @app.task def add(x, y): time.sleep(10) return x + y
记住:当有多个装饰器的时候,celery.task一定要在最外层;
编辑保存退出后,我在当前目录下运行如下命令:
$ celery -A tasks worker --loglevel=info
#查询文档,了解到该命令中-A参数表示的是Celery APP的名称,这个实例中指的就是tasks.py,后面的tasks就是APP的名称,worker是一个执行任务角色,后面的loglevel=info记录日志类型默认是info,这个命令启动了一个worker,用来执行程序中add这个加法任务(task)。
发送任务,添加任务到broker
#!/usr/bin/env python # -*- coding:utf-8 -*- from s1 import add # 立即告知celery去执行add任务,并传入两个参数 result = add.delay(4, 4) print(result.id)
备注: 每个任务都会有一个对应该任务的唯一ID,可以通过 result.id 获取到
查看任务执行状态以及结果
from celery.result import AsyncResult from s1 import app async = AsyncResult(id="f0b41e83-99cf-469f-9eff-74c8dd600002", app=app) if async.successful(): result = async.get() print(result) # result.forget() # 将结果删除 elif async.failed(): print('执行失败') elif async.status == 'PENDING': print('任务等待中被执行') elif async.status == 'RETRY': print('任务异常后正在重试') elif async.status == 'STARTED': print('任务已经开始被执行')
整个celery执行的步骤如下图:

扩展
-
如果使用redis作为任务队列中间人,在redis中存在两个键 celery 和 _kombu.binding.celery , _kombu.binding.celery 表示有一名为 celery 的任务队列(Celery 默认),而 celery为默认队列中的任务列表,使用list类型,可以看看添加进去的任务数据。
-
开启worker
在项目目录下执行:
celery -A app.celery_tasks.celery worker -Q queue --loglevel=info-
A参数指定celery对象的位置,该app.celery_tasks.celery指的是app包下面的celery_tasks.py模块的celery实例,注意一定是初始化后的实例,
-
Q参数指的是该worker接收指定的队列的任务,这是为了当多个队列有不同的任务时可以独立;如果不设会接收所有的队列的任务;
-
l参数指定worker的日志级别;
执行完毕后结果存储在redis中,查看redis中的数据,发现存在一个string类型的键值对:
celery-task-meta-064e4262-e1ba-4e87-b4a1-52dd1418188f:data该键值对的失效时间为24小时。
分析消息
- 这是添加到任务队列中的消息数据。
{"body": "gAJ9cQAoWAQAAAB0YXNrcQFYGAAAAHRlc3RfY2VsZXJ5LmFkZF90b2dldGhlcnECWAIAAABpZHEDWCQAAAA2NmQ1YTg2Yi0xZDM5LTRjODgtYmM5OC0yYzE4YjJjOThhMjFxBFgEAAAAYXJnc3EFSwlLKoZxBlgGAAAAa3dhcmdzcQd9cQhYBwAAAHJldHJpZXNxCUsAWAMAAABldGFxCk5YBwAAAGV4cGlyZXNxC05YAwAAAHV0Y3EMiFgJAAAAY2FsbGJhY2tzcQ1OWAgAAABlcnJiYWNrc3EOTlgJAAAAdGltZWxpbWl0cQ9OToZxEFgHAAAAdGFza3NldHERTlgFAAAAY2hvcmRxEk51Lg==", # body是序列化后使用base64编码的信息,包括具体的任务参数,其中包括了需要执行的方法、参数和一些任务基本信息
"content-encoding": "binary", # 序列化数据的编码方式
"content-type": "application/x-python-serialize", # 任务数据的序列化方式,默认使用python内置的序列化模块pickle
"headers": {},
"properties":
{"reply_to": "b7580727-07e5-307b-b1d0-4b731a796652", # 结果的唯一id
"correlation_id": "66d5a86b-1d39-4c88-bc98-2c18b2c98a21", # 任务的唯一id
"delivery_mode": 2,
"delivery_info": {"priority": 0, "exchange": "celery", "routing_key": "celery"}, # 指定交换机名称,路由键,属性
"body_encoding": "base64", # body的编码方式
"delivery_tag": "bfcfe35d-b65b-4088-bcb5-7a1bb8c9afd9"}}
- 将序列化消息反序列化
import pickle import base64 result = base64.b64decode('gAJ9cQAoWAQAAAB0YXNrcQFYGAAAAHRlc3RfY2VsZXJ5LmFkZF90b2dldGhlcnECWAIAAABpZHEDWCQAAAA2NmQ1YTg2Yi0xZDM5LTRjODgtYmM5OC0yYzE4YjJjOThhMjFxBFgEAAAAYXJnc3EFSwlLKoZxBlgGAAAAa3dhcmdzcQd9cQhYBwAAAHJldHJpZXNxCUsAWAMAAABldGFxCk5YBwAAAGV4cGlyZXNxC05YAwAAAHV0Y3EMiFgJAAAAY2FsbGJhY2tzcQ1OWAgAAABlcnJiYWNrc3EOTlgJAAAAdGltZWxpbWl0cQ9OToZxEFgHAAAAdGFza3NldHERTlgFAAAAY2hvcmRxEk51Lg==') print(pickle.loads(result)) # 结果 { 'task': 'test_celery.add_together', # 需要执行的任务 'id': '66d5a86b-1d39-4c88-bc98-2c18b2c98a21', # 任务的唯一id 'args': (9, 42), # 任务的参数 'kwargs': {}, 'retries': 0, 'eta': None, 'expires': None, # 任务失效时间 'utc': True, 'callbacks': None, # 完成后的回调 'errbacks': None, # 任务失败后的回调 'timelimit': (None, None), # 超时时间 'taskset': None, 'chord': None }
- 常见的数据序列化方式
binary: 二进制序列化方式;python的pickle默认的序列化方法;
json:json 支持多种语言, 可用于跨语言方案,但好像不支持自定义的类对象;
XML:类似标签语言;
msgpack:二进制的类 json 序列化方案, 但比 json 的数据结构更小, 更快;
yaml:yaml 表达能力更强, 支持的数据类型较 json 多, 但是 python 客户端的性能不如 json- 经过比较,为了保持跨语言的兼容性和速度,采用msgpack或json方式;
celery配置
- celery的性能和许多因素有关,比如序列化的方式,连接rabbitmq的方式,多进程、单线程等等;
基本配置项
CELERY_DEFAULT_QUEUE:默认队列
BROKER_URL : 代理人的网址
CELERY_RESULT_BACKEND:结果存储地址
CELERY_TASK_SERIALIZER:任务序列化方式
CELERY_RESULT_SERIALIZER:任务执行结果序列化方式
CELERY_TASK_RESULT_EXPIRES:任务过期时间
CELERY_ACCEPT_CONTENT:指定任务接受的内容序列化类型(序列化),一个列表;
采用配置文件的方式执行celery
# main.py from celery import Celery import celeryconfig app = Celery(__name__, include=["task"]) # 引入配置文件 app.config_from_object(celeryconfig) if __name__ == '__main__': result = add.delay(30, 42) # task.py from main import app @app.task def add(x, y): return x + y # celeryconfig.py BROKER_URL = 'amqp://username:password@localhost:5672/yourvhost' CELERY_RESULT_BACKEND = 'redis://localhost:6379/0' CELERY_TASK_SERIALIZER = 'msgpack' CELERY_RESULT_SERIALIZER = 'msgpack' CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24 # 任务过期时间 CELERY_ACCEPT_CONTENT = ["msgpack"] # 指定任务接受的内容类型.
- 一些方法
r.ready() # 查看任务状态,返回布尔值, 任务执行完成, 返回 True, 否则返回 False.
r.wait() # 等待任务完成, 返回任务执行结果,很少使用;
r.get(timeout=1) # 获取任务执行结果,可以设置等待时间
r.result # 任务执行结果.
r.state # PENDING, START, SUCCESS,任务当前的状态
r.status # PENDING, START, SUCCESS,任务当前的状态
r.successful # 任务成功返回true
r.traceback # 如果任务抛出了一个异常,你也可以获取原始的回溯信息celery的装饰方法celery.task
@celery.task()
def name():
pass- task()方法将任务装饰成异步,参数:
name:可以显示指定任务的名字;
serializer:指定序列化的方法;
bind:一个bool值,设置是否绑定一个task的实例,如果把绑定,task实例会作为参数传递到任务方法中,可以访问task实例的所有的属性,即前面反序列化中那些属性
@task(bind=True) # 第一个参数是self,使用self.request访问相关的属性
def add(self, x, y):
logger.info(self.request.id)base:定义任务的基类,可以以此来定义回调函数
import celery class MyTask(celery.Task): # 任务失败时执行 def on_failure(self, exc, task_id, args, kwargs, einfo): print('{0!r} failed: {1!r}'.format(task_id, exc)) # 任务成功时执行 def on_success(self, retval, task_id, args, kwargs): pass # 任务重试时执行 def on_retry(self, exc, task_id, args, kwargs, einfo): pass @task(base=MyTask) def add(x, y): raise KeyError() exc:失败时的错误的类型; task_id:任务的id; args:任务函数的参数; kwargs:参数; einfo:失败时的异常详细信息; retval:任务成功执行的返回值;
- 另外还可以指定exchange信息等,不过一般不使用;
调用异步任务的方法
task.delay():这是apply_async方法的别名,但接受的参数较为简单; task.apply_async(args=[arg1, arg2], kwargs={key:value, key:value}) send_task():可以发送未被注册的异步任务,即没有被celery.task装饰的任务; # tasks.py from celery import Celery app = Celery() def add(x,y): return x+y app.send_task('tasks.add',args=[3,4]) # 参数基本和apply_async函数一样 # 但是send_task在发送的时候是不会检查tasks.add函数是否存在的,即使为空也会发送成功
备注:使用celery执行定时任务时,一定要当前时间转化为UTC时间,否则就会出问题。
- apply_async的参数:
countdown : 设置该任务等待一段时间再执行,单位为s;
eta : 定义任务的开始时间;eta=time.time()+10;
expires : 设置任务时间,任务在过期时间后还没有执行则被丢弃;
retry : 如果任务失败后, 是否重试;使用true或false,默认为true
shadow:重新指定任务的名字str,覆盖其在日志中使用的任务名称;
retry_policy : 重试策略.
max_retries : 最大重试次数, 默认为 3 次.
interval_start : 重试等待的时间间隔秒数, 默认为 0 , 表示直接重试不等待.
interval_step : 每次重试让重试间隔增加的秒数, 可以是数字或浮点数, 默认为 0.2
interval_max : 重试间隔最大的秒数, 即 通过 interval_step 增大到多少秒之后, 就不在增加了, 可以是数字或者浮点数, 默认为 0.2 .add.apply_async((2, 2), retry=True, retry_policy={
'max_retries': 3,
'interval_start': 0,
'interval_step': 0.2,
'interval_max': 0.2,
})routing_key:自定义路由键;
queue:指定发送到哪个队列;
exchange:指定发送到哪个交换机;
priority:任务队列的优先级,0-9之间;
serializer:任务序列化方法;通常不设置;
compression:压缩方案,通常有zlib, bzip2
headers:为任务添加额外的消息;
link:任务成功执行后的回调方法;是一个signature对象;可以用作关联任务;
link_error: 任务失败后的回调方法,是一个signature对象;
- 自定义发布者,交换机,路由键, 队列, 优先级,序列方案和压缩方法:
task.apply_async((2,2),
compression='zlib',
serialize='json',
queue='priority.high',
routing_key='web.add',
priority=0,
exchange='web_exchange')一份比较常用的配置文件
# 注意,celery4版本后,CELERY_BROKER_URL改为BROKER_URL BROKER_URL = 'amqp://username:passwd@host:port/虚拟主机名' # 指定结果的接受地址 CELERY_RESULT_BACKEND = 'redis://username:passwd@host:port/db' # 指定任务序列化方式 CELERY_TASK_SERIALIZER = 'msgpack' # 指定结果序列化方式 CELERY_RESULT_SERIALIZER = 'msgpack' # 任务过期时间,celery任务执行结果的超时时间 CELERY_TASK_RESULT_EXPIRES = 60 * 20 # 指定任务接受的序列化类型. CELERY_ACCEPT_CONTENT = ["msgpack"] # 任务发送完成是否需要确认,这一项对性能有一点影响 CELERY_ACKS_LATE = True # 压缩方案选择,可以是zlib, bzip2,默认是发送没有压缩的数据 CELERY_MESSAGE_COMPRESSION = 'zlib' # 规定完成任务的时间 CELERYD_TASK_TIME_LIMIT = 5 # 在5s内完成任务,否则执行该任务的worker将被杀死,任务移交给父进程 # celery worker的并发数,默认是服务器的内核数目,也是命令行-c参数指定的数目 CELERYD_CONCURRENCY = 4 # celery worker 每次去rabbitmq预取任务的数量 CELERYD_PREFETCH_MULTIPLIER = 4 # 每个worker执行了多少任务就会死掉,默认是无限的 CELERYD_MAX_TASKS_PER_CHILD = 40 # 设置默认的队列名称,如果一个消息不符合其他的队列就会放在默认队列里面,如果什么都不设置的话,数据都会发送到默认的队列中 CELERY_DEFAULT_QUEUE = "default" # 设置详细的队列 CELERY_QUEUES = { "default": { # 这是上面指定的默认队列 "exchange": "default", "exchange_type": "direct", "routing_key": "default" }, "topicqueue": { # 这是一个topic队列 凡是topictest开头的routing key都会被放到这个队列 "routing_key": "topic.#", "exchange": "topic_exchange", "exchange_type": "topic", }, "task_eeg": { # 设置扇形交换机 "exchange": "tasks", "exchange_type": "fanout", "binding_key": "tasks", }, }
-参考:
-
http://www.cnblogs.com/cwp-bg/p/8759638.html
- https://www.cnblogs.com/wupeiqi/articles/8796552.html
作者:赵盼盼
出处:https://www.cnblogs.com/zhaopanpan/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
⇩ 关注或点个喜欢就行 ^_^
关注我


