

机器学习之支持向量机
函数间隔: yi(wx + b)
几何间隔:将函数间隔除以 || w ||
KKT约束条件:https://zhuanlan.zhihu.com/p/26514613
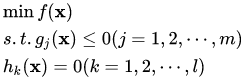
KKT条件给出了判断是否为最优解的必要条件,即:

拉格朗日对偶 https://blog.csdn.net/u011327333/article/details/51222605
SVM过程:
目的:几何间隔最大化,即 求 max r; st: yi ( w / ||w|| * x + b / ||w|| ) >= r
基于几何间隔和函数间隔之间的关系上面的问题可以转换成: max R / ||w|| , st : yi( wx + b ) >= R, 其中R是函数间隔,可以另R = 1, 因为, w,b是可以同时变化的
所以问题最后变成 max 1 / ||w|| ; s.t : yi ( wx + b) >= 1
又可以变换成: min 1/2 * ||w||^2; s.t:1-yi(wx+b) <= 0, 这个问题可以利用拉格朗日对偶问题求解
核函数的选择问题:https://blog.csdn.net/wenqiwenqi123/article/details/79377456
1、线性核函数,即无核函数
2、高斯函数
3、多项式核函数
4、字符串核函数
选择标准: n表示特征维数,m表示样本个数,
如果 n 很大, m 很小, 此时极有可能是线性可分的,所以选择 线性核函数,
如果 n 很小, m 很大, 用高斯核函数
其他核函数用的比较少
SVM 和 logistic regression
1、SVM和logistic regression不同:
1、损失函数:
svm 采用合页损失函数,logistic regression 采用对数损失函数
2、寻找最优超平面的方法不同
形象点说,Logistic模型找的那个超平面,是尽量让所有点都远离它,而SVM寻找的那个超平面,是只让最靠近中间分割线的那些点尽量远离,即只用到那些“支持向量”的样本——所以叫“支持向量机”。
3、SVM可以处理非线性的情况
比Logistic更强大的是,SVM还可以处理非线性的情况。
参考:https://blog.csdn.net/ybdesire/article/details/54143481
如何选择
既然SVM与Logistic非常相似,那是不是它们可以混合使用呢?结果是否定的,在不同的情况下,应该选择不同的算法。
用n表示Feature数量,m表示训练集个数。下面分情况讨论
n很大,m很小
n很大,一般指n=10000;m很小,一般m=10-1000。m很小,说明没有足够的训练集来拟合非常复杂的非线性模型,所以这种情况既可以选择线性kernel的SVM,也可以选择Logistic回归。
n很小,m中等
n很小,一般指n=1-1000;m很小,一般m=1000-10000。m中等,说明有足够的训练集来拟合非常复杂的非线性模型,此时适合选择非线性kernel的SVM,比如高斯核kernel的SVM。
n很小,m很大
n很小,一般指n=1-1000;m很大,一般m=50000-1000000。m很大,说明有足够的训练集来拟合非常复杂的非线性模型,但m很大的情况下,带核函数的SVM计算也非常慢。所以此时应该选线性kernel的SVM,也可以选择Logistic回归。n很小,说明Feature可能不足以表达模型,所以要添加更多Feature。
注意,一个结构合适的神经网络,可以适用以上提到的所有情况,但神经网络一般训练速度都很慢

