

机器学习之逻辑回归与最大熵模型
一、逻辑回归
逻辑回归是由线性回归演变过来,线性回归是将X映射到一个实数域,而逻辑回归是将X映射到一个离散集合,因为只是一个分类问题。
1、逻辑回归模型
- 01分类问题
对于01分类问题,在线性回归后加入一个逻辑函数,即sigmoid函数
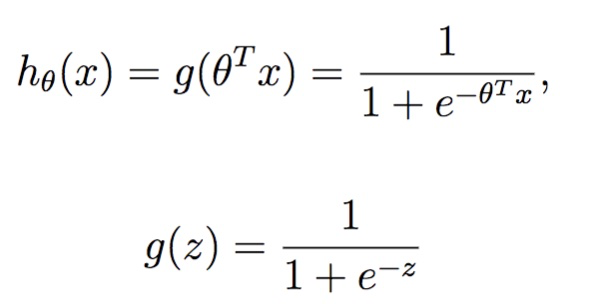
逻辑回归是通过最大似然估计来求解参数的,一个样本01的概率分别可以如下表示:
![]()
整理下得到:
![]()
似然函数可以写成如下形式:
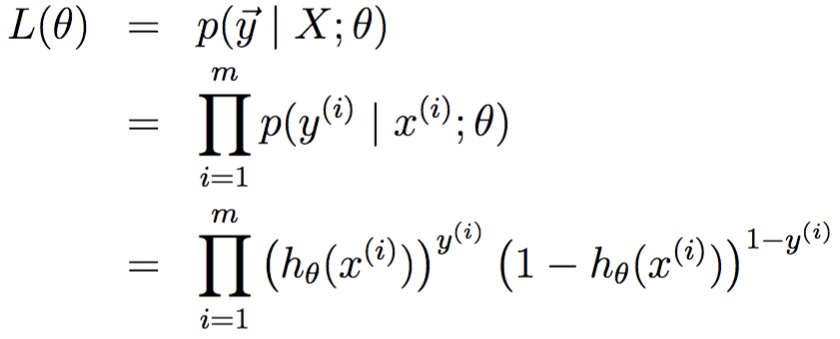
对上式取log操作得:
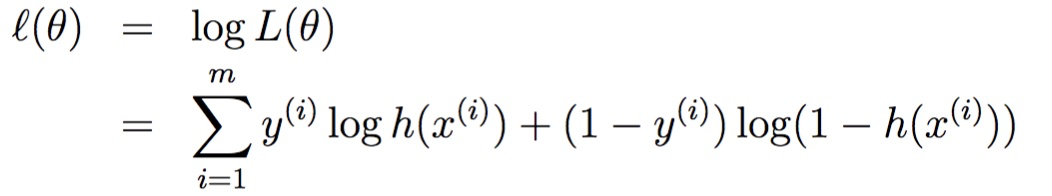
使上式最大的Θ,即为最后的参数。
方法:梯度下降法(准确来说这里指的梯度上升),牛顿法
梯度下降法:
对于一个样本进行求导
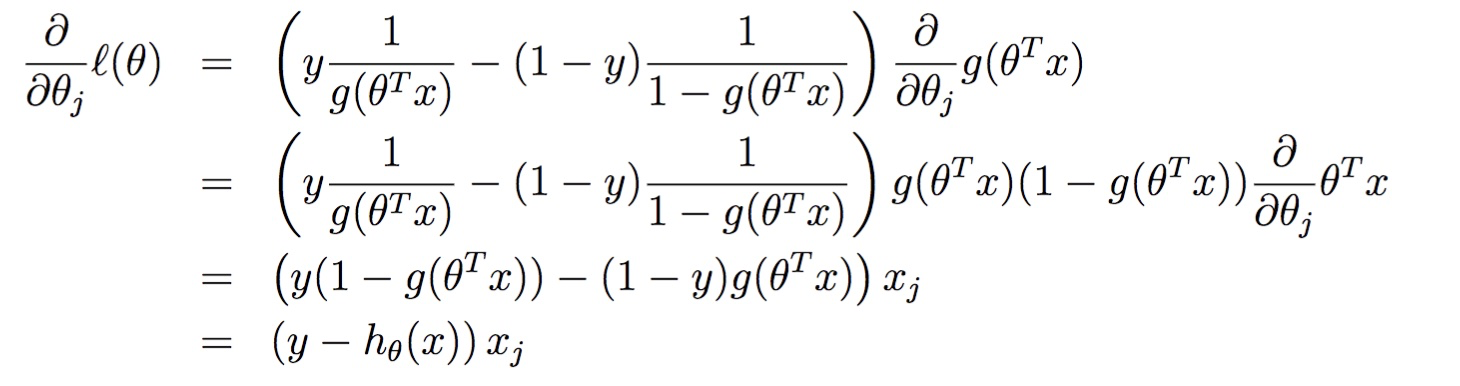
随机梯度下降更新公式为:
![]()
为什么要以1类样本的概率进行拟合呢,为什么可以这样拟合呢?
首先,logstic 函数的本质说起。若要直接通过回归的方法去预测二分类问题, y 到底是0类还是1类,最好的函数是单位阶跃函数。然而单位阶跃函数不连续(GLM 的必要条件),而 logsitic 函数恰好接近于单位阶跃函数,且单调可微。
一个事件的几率是指该事件发生的概率与该事件不发生的概率的比值,如果事件发生概率为p,那么该事件的几率为 p/(1-p), 该事件的对数几率是 $logit(P) = \log \frac{p}{1-p}$,对于逻辑回归而言,有![]()
当$\theta ^{T}X$ > 0, 为正类,当$\theta ^{T}X$ < 0, 为负类
在线性回归中$\theta ^{T}X$是拟和函数,而在逻辑回归中$\theta ^{T}X$ = 0是决策边界。
-
多项逻辑回归
由二分类推广到多分类问题,原理差不多,也可由二项逻辑回归参数估计法推广到多项逻辑回归。
2、逻辑函数
对于1和-1的分类问题来说,我们根据最后函数值的符号进行分类

如果预测正确,则有$y\theta ^{T}X$ > 0,在数值上,如果$y\theta ^{T}X$越大说明准确率越高,所以我们希望$y\theta ^{T}X$ 越大越好。
我们找一个φ函数作为损失函数,并希望J(Θ)能够最小,如何选取φ
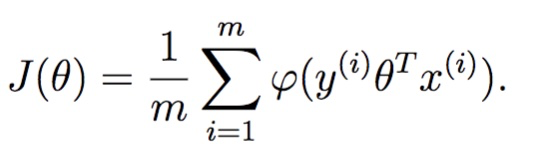

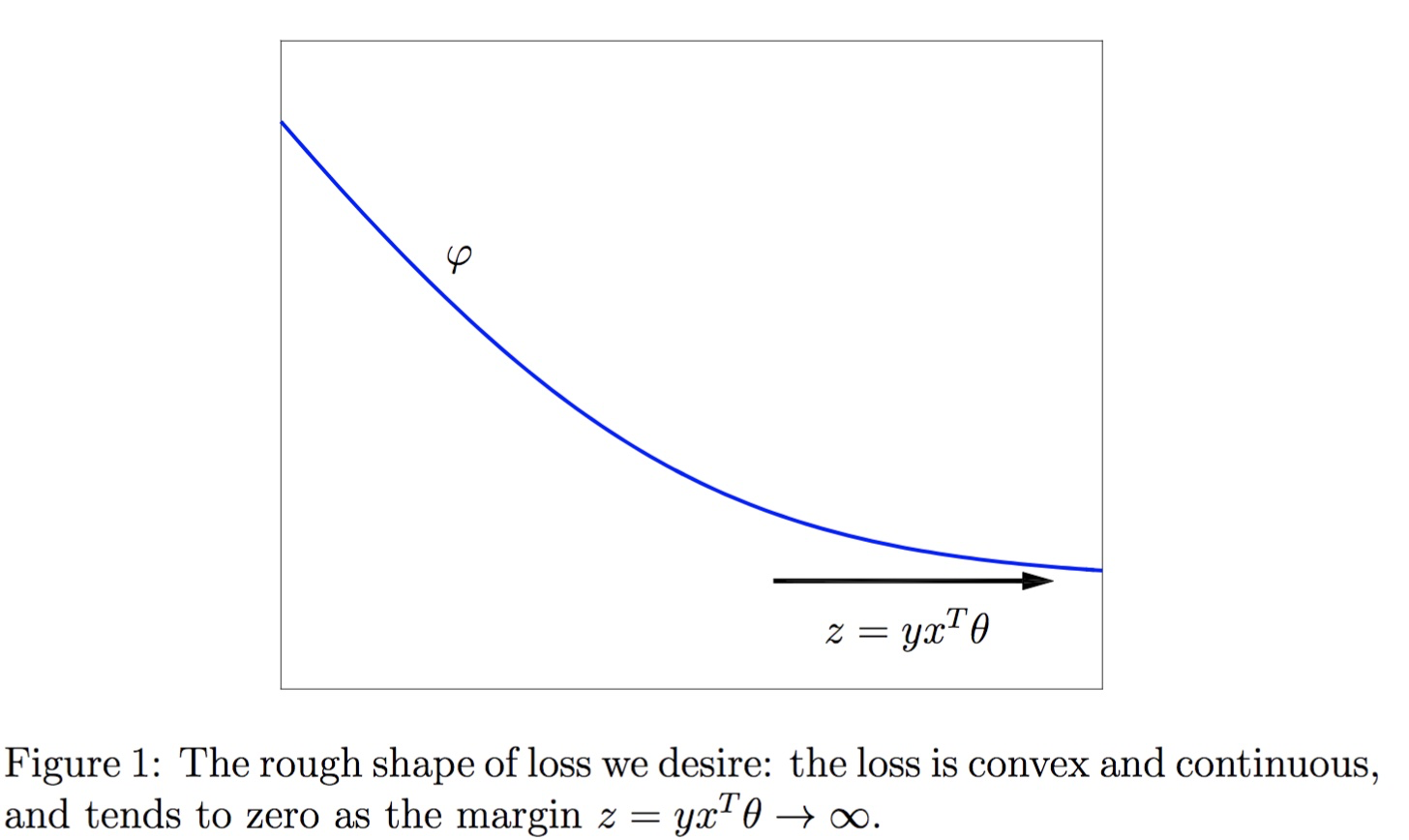
损失函数最后变成:
![]()
求导:
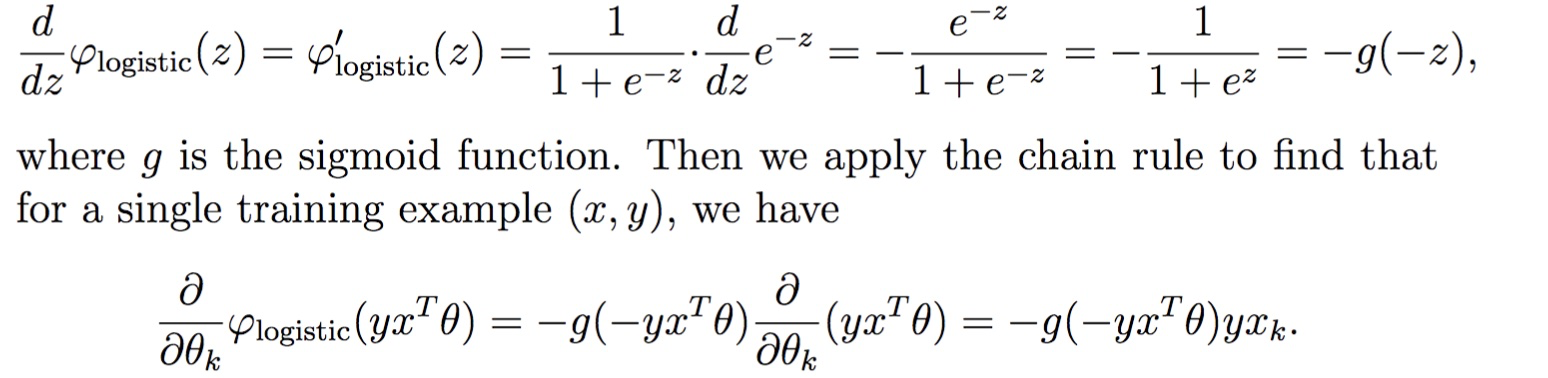

二、最大熵模型
最大熵模型就是根据最大熵原理进行分类
1、最大熵的定义

约束条件是:
对于每一个特征函数,经验期望与模型预测期望相等
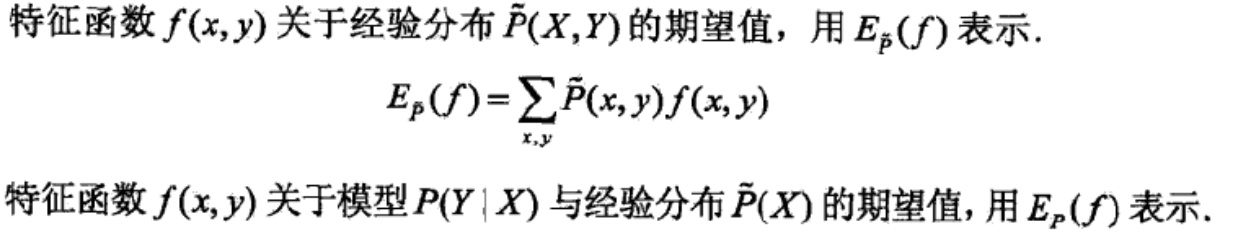
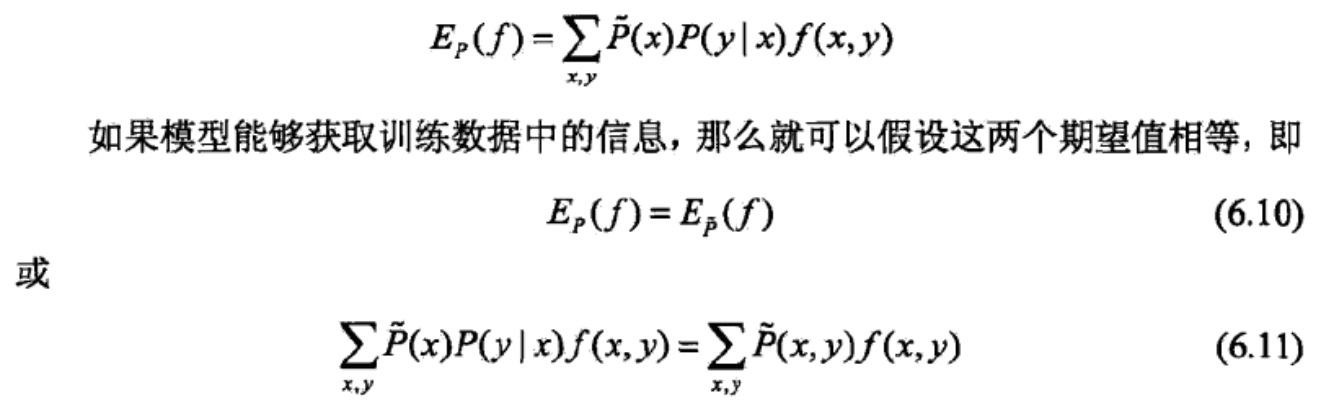
特征函数关于经验分布的期望值计算方法,这里f(x,y),x取值范围是X向量任意一维度的值,y的取值范围是Y向量任意一维度值,f表示的是一种关系,x与y的一种关系,可以有好多f
所以某一个特征函数关于经验分布的期望值就需要两层循环分别遍历x,y来乘积累加。
好像不太明白p(y|x)含义

条件熵不就是条件期望了吗?

这里是在保证H(P)最大情况下的求P(y|x),怎么感觉乖乖的,难道P(y|x)会变?





所以最大熵就变成了:

![]() 表示某一个特定的x生成一个某一个y的概率,x取值很多的,同样y的取值也是很多的。
表示某一个特定的x生成一个某一个y的概率,x取值很多的,同样y的取值也是很多的。

参考
http://blog.csdn.net/u010692239/article/details/52345754
https://blog.csdn.net/zjuPeco/article/details/77165974
https://blog.csdn.net/ligang_csdn/article/details/53838743
http://120.52.51.13/cs229.stanford.edu/extra-notes/loss-functions.pdf
http://120.52.51.14/cs229.stanford.edu/notes/cs229-notes1.pdf
http://www.hankcs.com/ml/the-logistic-regression-and-the-maximum-entropy-model.html#h3-16

