

python基础
切片:
name[起始位置:终止位置:每取一个后加的步子的长度]
name[::-1] 表示逆序
name[-1:0:-1] 会取不到第一个数
name[-1::-1] = name[::-1] 都会逆序
列表添加三种方式:
name = []
1.name.append('')添加一个元素
2.name = name1 + name2 两个列表相加
3 name.extend(name1) 在原来的列表的基础上加上name1, name1和name的类型相同
删除元素
1 name.pop() 删除最后一个
2 remove() 根据内容删除
3 del name[0] 根据下表删除
删除字典:
del info['QQ']
info.get(' ') 如果没有的时候会返回空,不至于让程序崩溃
for num in nums: print(num) else: print('end') #else等for循环执行完才会执行, end一定会打印,除非print(num)后面加一个break
元组
不能修改里面的内容。
python 2.7从控制台输入用
message = raw_input("input:")
函数:
不定长函数 *args
#a,b是需要要有值得,args是后面的所有,最后是一个元组
def test(a, b, *args):
pass
test(1,2,3,4)
test(1,2)
不定长函数 **kwargs
#当调用函数时,以变量名+值得形式当参数来调用时,会将所有的内容都传给kwargs,最后的结果是字典的形式 def test(a, b, *args, **kwargs): print(a) print(b) print(args) print(kwargs) test(1,2,3,4,task=89,done=20) 最后结果: 1 2 (3,4) {‘task':89, 'done':20}
#拆包
c=(1,2,3,4)
dict = {'task':89, 'done':20}
test(1,2,c,dict) #会将c和dict里面的内容拆开,分别赋给args, kwargs
关于 * 和 **
1、如上例所述,定义函数作为函数的参数,参数为*args,传入的args将是一个tuple, 参数为**kwargs, 传入的kwargs是一个字典
2、当调用函数时作为参数时,也会args也是一个tuple,只不过,是将传入的数组一个一个的放到tuple,而不是将数组当初tuple的一个元素,**kwargs时,要求输入内容为字典,key为函数形参,value为参数值
def sum(*args): print args val = (1,2) sum(val) //作为一个整体 sum(*val) //一个一个 ----------output------------ ((1, 2),) (1, 2)
python引用
a = 1 b = a #此时表示a 和 b同时纸箱某个内存的位置 #打印出a,b值会发现此时的内存地址是相同的 id(a) id(b)
a = 2 #此时a又指向另一个内存的位置
变量名:
实例变量:以_开头,其他和普通变量一样
私有实例变量(外部访问会报错):
以__开头(2个下划线),其他和普通变量一样
__private_var
字符串的操作:
1.find
2.join
3.split()不加值时按照不可见字符删除
collections
1、Counter
>>> c = Counter('gallahad') # 从一个可iterable对象(list、tuple、dict、字符串等)创建
更新: c.update()
删除: c.substract()
第九章类
在python中,如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线__,在Python中,实例的变量名如果以__开头,就变成了一个私有变量(private),只有内部可以访问,外部不能访问
class Student(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
第十章文件和异常
1、从文件中读取
三种方式:read, readline, readlines
read: 全部读取形成一个str
readline(): 每次读取一行,比readlines()慢得多;readline()返回的是一个字符串对象,保存当前行的内容
readlines():一次读取全部文件,自动将文件内容形成一个行的内容
with open('pi_digits.txt') as file_object: """读取整个文件 contents = file_object.read() print(contents.rstrip()) 逐行读取 for line in file_object: print(line.rstrip()) 创建一个包含文件各行内容的列表 """ lines = file_object.readlines() for line in lines: print(line.rstrip())
f = open('xxxxxx.txt', 'r+') f.read() 'hahahaha\n' #read(n) 表示每次读取 n 个字节
f.read(1) '' #seek用来调整当前的指针,0表示文件开头,2表示文件末尾
f.seek(0,0) #返回文件开头 f.read(1) 'h' f.read(1) 'a' f.read(1) 'h' f.seek(0,2) f.read(1) '' f.write('jjjjjjjjjjj') f.read() '' f.seek(0, 0) f.read() 'hahahaha\njjjjjjjjjjj'
2、写入文件
open(),两个实参,第一个实参是打开文件的名称,第二个实参是打开的模式。 r (默认),w, a
with open(filename, 'a') as file_object: file_object.write("l also love finding meaning in large datasets.\n") file_object.write("l love creating apps that can run in a browser.\n")
3批量对文件命名(os)
import os #1get all folder folder_name = input('input folder:') #2get all file file_names = os.listdir(folder_name) #2rename #os.chdir(folder_name) for file_name in file_names: #print(file_name) old_file_name = './' + folder_name + '/' + file_name new_file_name = './' + folder_name + '/[h]' + file_name os.rename(old_file_name, new_file_name)
1、map 和 reduce,fliter
#map是对列表里的每一个数进行映射 ret = map(lambda x : x * x , [1, 2, 3]) ret [1, 4, 9] #fileter是第一个条件满足的则会留下来 In [9]: ret = filter(lambda x: x % 2, [1, 2, 3, 4]) In [10]: ret Out[10]: [1, 3] #如果改成map则只会取值 In [11]: ret = map(lambda x: x % 2, [1, 2, 3, 4]) In [12]: ret Out[12]: [1, 0, 1, 0] #reduce会对每一个元素进行累加 In [14]: reduce(lambda x,y: x + y, ['aa', 'bb', 'cc'], 'dd') Out[14]: 'ddaabbcc'
2、匿名函数 lambda
f = lambda x: x * x 匿名函数默认带有return, f(3) 会打印出9
匿名函数的应用(一)
对字典的内容排序
In [2]: stu = [ { 'name':'zhongha', 'age':10}, { 'name':'aongha', 'age':13}, { '
...: name':'dongha', 'age':11} ]
In [3]: stu.sort(key=lambda info:info['name'])
In [4]: stu
Out[4]:
[{'age': 13, 'name': 'aongha'},
{'age': 11, 'name': 'dongha'},
{'age': 10, 'name': 'zhongha'}]
匿名函数的应用二
>>> def test(a, b, func):
... result = func(a, b)
... print(result)
...
>>> test(11, 22, lambda x, y: x + y)
33
匿名函数应用三
def test(a, b, func):
result = func(a, b)
print(result)
func_new = input("input a function:")
func_new = eval(func_new) #python 3需要该函数,将字符串的引号去掉
test(11, 22, func_new)
补充知识1 全局变量
a = 100 #整数型的全局变量不可变,所以在test函数中会重现创建要给值 b = [100]#列表的全局变量是可变的,所以test函数中会自动改便b的值 def test(num): num += num print (num) test(a) print(a) test(b) print(b)
补充知识2 交换
交换a,b的值
方法一
a = a + b
b = a - b
a = a - b
方法二
a,b = b,a

3、装饰器,用来在函数调用前输出一些信息
def debug2(func): def wrapper(*args, **kwargs): #可以包含多个参数 print "[debug]:enter{}()".format(func.__name__) print "Prepare and say..." return func(*args, **kwargs) return wrapper
#装饰器原理 def w1(func): def inner(): print('----authorizing---') func() return inner def f1(): print('---f1----') def f2(): print('---f2----') f1 = w1(f1) f1()
装饰时,先倒着装饰,到执行的时候是从上往下依次执行

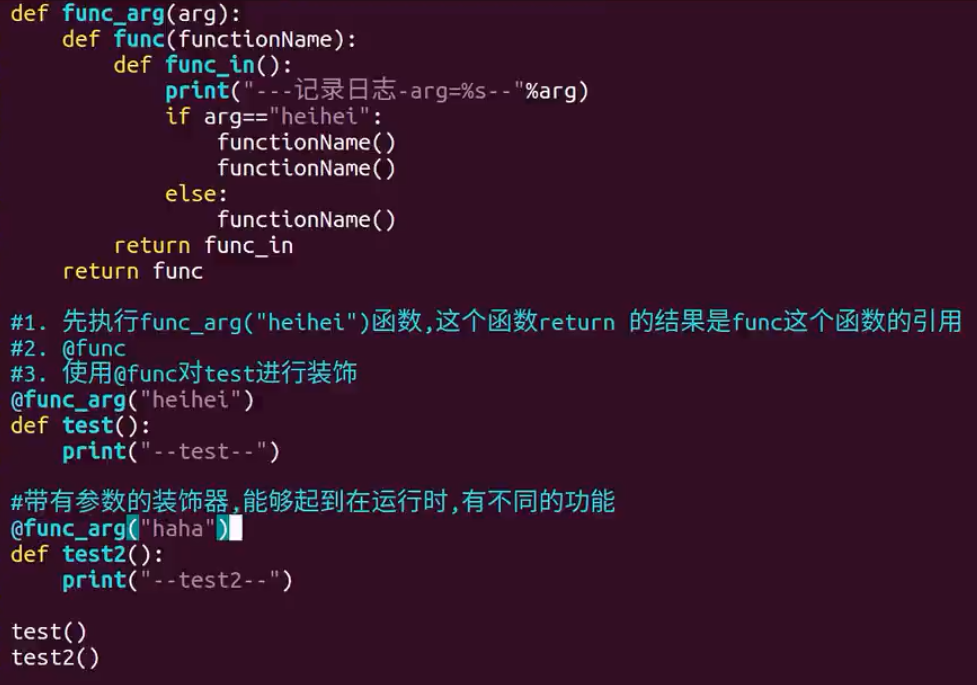
4、判断对象是否是某类的实例
isinstance('abc', str)
5、实例属性与类属性(java中的静态成员)
实例属性:在__init__里面定义的属性,
类属性:归类所有,在class中定义
class Game(object): num = 0 def __init__(self): self.name = 'laowang' #method 类方法需要加@classmethod, 参数需要添加cls @classmethod def add_num(cls): cls.num = 100 #static method, 静态方法不用加参数 def print_menu(): print('----------------') print('-----hello------') print('----------------') game = Game() Game.add_num() #可以通过类和实例来调用类方法 game.add_num() print(Game.num) Game.print_menu()
6、MethodType:
#!/usr/bin/env python
# encoding: utf-8
from types import MethodType
#创建一个方法
def set_age(self, age):
self.age = age
#创建一个类
class Student(object):
pass
s = Student()
s.name = 'Micle'
print(s.name)
from types import MethodType
s.set_age = MethodType(set_age, s) #给实例绑定了一个方法,对于其他的实例不起作用
s.set_age(10)
print(s.age)
Student.set_age = set_age #给类绑定了一个方法,所有的实例都会有该方法
new1 = Student()
new2 = Student()
new1.set_age(11)
new2.set_age(12)
print(new1.age, new2.age)
Python中调试技巧:
引用 pdb
import pdb 4 s = '0' 5 n = int(s) 6 pdb.set_trace() #断点 7 print(n / 0)
p 变量名 :查看变量值
c 继续执行
------------------------------------------
面向对象
1、方法一
__init__(self):
2、__str__(self):
打印对象时,也是自定义输出内容
3.__函数名(self):
私有方法
4、__del__(self):
对象删除时会自动调用
5. __call__():
调用对象(),会调用call方法
6. __new__(cls):
创建一个对象
5、在子类中重写父类的方法时,仍需在调用父类的方法
1、 Dog.bark(self)
2、super().bark()
class Dog(object): def __init__(self): print('---init---') def __del__(self): print('---del---') def __str__(self): print('---self---') return('str') def __new__(cls): print('---new---') return object.__new__(cls) xtq = Dog() 当执行Dog()时,相当于做了三件事 1.调用__new__方法来创建对象,然后找一个变量来接受__new__的返回值,这个返回值表示创建出来的对象的引用 2.__init__(刚刚创建出来的对象的引用) 3 返回对象的引用 --------------------------- C++和Java中的构造函数是指创建对象并初始化,pyhont不存在构造函数,__new__用来创建对象,__init__用来初始化
#单例模式,只创建一个对象 class Dog(object): __instance = None def __new__(cls): if cls.__instance == None: cls.__instance = object.__new__(cls) return cls.__instance else: return cls.__instance a = Dog() print(id(a)) b = Dog() print(id(b))
导入模块:
sys
imp中reload(模块名), 可以重新导入一个模块
== 和 is
== 表示两个值是否相等, is指的是内存地址是否相等
深拷贝和浅拷贝:
浅拷贝:a只是把地址给b

深拷贝:由开辟一块内存给c,此时a,b指向同一块内存,c自己指向一块内存
不管有什么内容都会重新拷贝


copy.deepcopy()全部都会拷贝,copy.copy() 仅仅拷贝第一层


在一个文件中,如果变量名包含下划线,改变了为私有属性
property:
num = property(getNum, setNum) 就可以通过 类名.num 来表示了

判断是否可以迭代:
from collections import Iterable isinstance([], Iterable)
判断是否是迭代对象,可以迭代不一定是迭代对象
from collections import Iterator
isinstance([], Iterator)
def test(number): print('---------1---------') def test_in(number2): print('--------2-------') print(number + number2) print('-----------3----------') return test_in ret = test(100) #返回一个函数的引用 print('-------------4----------') ret(1)
闭包的应用(输出一个直线的值,相比传三个参数闭包写法更简单,写完之后a,b都已确定,再次调用只用写x的值)
def test(a, b):
def test_in(x):
print(a * x + b)
return test_in
line1 = test(1, 1)
line1(0)
line2 = test(10, 4)
line2(0)
生成器:
如果需要枚举很大的数,可以用生成器(产生一个数的算法),边生成遍枚举
def create_num(): print('----start----') a, b = 0,1 for i in range(5): print('----1----') yield b print('----2----') a,b = b, a + b print('----3----') print('----end----') a = create_num() next(a) a.__next__() #当执行yield就会暂停一下,
#利用生成器模拟多任务
def test1(): while True: print('---1---') yield None def test2(): while True: print('---2---') yield None t1 = test1() t2 = test2() while True: t1.__next__() t2.__next__()
元类
def printNum(self): print("---num-%d---"%self.num) #type用来创建一个类,第一个参数是类名,第二个参数是父类,第三个参数是类属性 Test3 = type('Test3', (), {'printNum':printNum}) t1 = Test3() t1.num = 100 t1.printNum() class printNum2: def printNum(self): print('---num-%d---'%self.num) t2 = printNum2() t2.num = 100 t2.printNum()
def upper_attr(future_class_name, future_class_parents, future_class_attr): newAttr = {} for name, value in future_class_attr.items(): if not name.startswith('__'): newAttr[name.upper()] = value return type(future_class_name, future_class_parents, future_class_attr) #表示用upper_attr函数来创建一个类 class Foo(object, metaclass=upper_attr): bar = 'bar' print( hasattr(Foo, 'bar')) print( hasattr(Foo, 'BAR'))
python垃圾回收机制:
小整数池: [5, 257) 常驻内存,不会被删除,
简单的字符串,不包含空格的复杂字符的 也会在固定的内存位置
python垃圾回收机制 以引用计数为主,但是解决不了互相引用的问题, 隔代回收为辅
内建属性
python中通过对象调用方法或者变量时(t.num 或者 t.show()),总是会先调用__getattribute__方法,由该方法返回所调用内容的引用
class ITcast(object): def __init__(self, subject): self.subject1 = subject self.subject2 = 'cpp' def __getattribute__(self, obj): print('====1>%s'%obj) if obj == 'subject1': print('log subject1') return 'redirect python' else: temp = object.__getattribute__(self, obj) print('====2>%s'%str(temp)) return temp def show(self): print('this is Itcast') s = ITcast('python') print(s.subject1) print(s.subject2) s.show()
