
知识蒸馏原理及BERT蒸馏实战
正文
------------恢复内容开始------------
------------恢复内容开始------------
前言
本文主要介绍知识蒸馏原理,并以BERT为例,介绍两篇BERT蒸馏论文及代码,第一篇论文是在下游任务中使用BiLSTM对BERT蒸馏,第二篇是对Transformer蒸馏,即TinyBert。
知识蒸馏
https://arxiv.org/pdf/1503.02531.pdf
由于大模型参数量巨大,线上部署不仅对机器资源要求比较高而且推理速度慢,因此需要对模型进行压缩加速,知识蒸馏便是模型压缩的一种形式。
知识蒸馏(Knowledge Distillation)基于“教师-学生网络”思想,将已经训练好的大模型(教师)中的知识迁移到小模型(学生)训练中。
知识蒸馏分为两步:
-
在数据集上训练大模型(教师)
-
在高温T下,对大模型进行蒸馏,将大模型学习到的知识迁移到小模型(学生)上
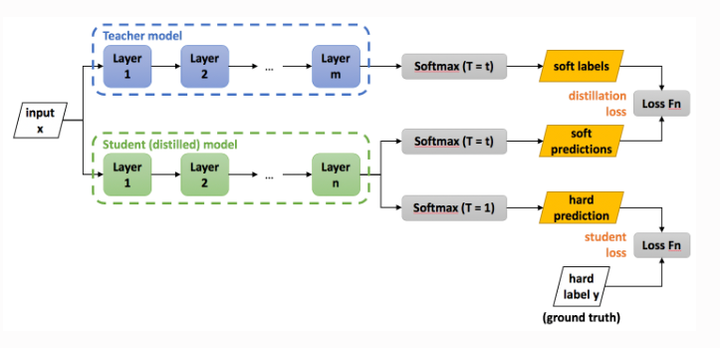
下面介绍知识蒸馏在分类任务中的做法:
一般分类任务处理逻辑是通过softmax层将输出层输出的logits转化成概率分类,然后计算预估概率与真实标签的交叉熵作为损失进行梯度更新。
知识蒸馏是希望让小模型能够学到大模型的输出,为什么是输出呢?
因为真实标签是one-hot形式表示,计算预估概率与真实标签的交叉熵时无法学习到其他类目的知识,通过让小模型拟合大模型的输出,比单纯拟合真实标签能学到更多的知识。
大模型的输出有两种,分别是logits和经softmax层后概率,下面将分别介绍蒸馏中这两种输出的拟合方式。
拟合softmax
softmax层后得到的是各类目的概率分布,由于使用指数函数会放大logits,使类目的概率差异变大,知识蒸馏时使用温度(T)对logits放缩,从而使softmax后的概率分布不要有太大的差异,即能学到原始类目间关系。
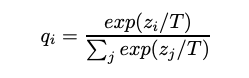
高温蒸馏的损失函数为  。
。
拟合logits
与拟合softmax层相比,这种方式较简单,最小化的目标函数是教师网络和学生网络输出logits的平方差,即 %5E%7B2%7D)
关于温度的理解
温度影响softmax层的输出,当T比较大时, 每个类的输出概率会比较接近,这样能学习到能过其他类目的信息。
温度高低代表对负标签的关注程度,温度越高,负标签的值相对较大,学生网络能学习到更多负标签信息。
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
背景
BERT模型在下游任务fine-tuning后,由于参数量巨大,计算比较耗时,很难真正上线使用,该论文提出使用简单神经网络(单层BiLSTM)对fine-tuned BERT进行蒸馏,蒸馏后的BiLSTM模型与ELMo效果相同,但是参数量减少100倍且推理时间减少15倍。
模型结构
以在训练集上fine-tune后的BERT模型作为teacher网络,BiLSTM作为student网络进行蒸馏训练,整体训练过程如下:
-
先用fine-tuning后的bert对训练数据进行预估,得到bert输出概率
-
然后使用BiLSTM网络对训练数据进行建模,得到BiLSTM输出概率
-
最后计算hard loss(BiLSTM输出概率分布与真实标签的交叉熵)和soft loss(BiLSTM与Bert输出logits的均方误差),加权作为损失
使用BiLSTM进行分类的结构如下,使用BiLSTM(b)对序列(a)进行学习,将前向(c)和后向(d)最后隐层向量拼接后连接带有relu激活函数的全连接层(efg)得到logit输出(h),再经softmax(i)得到概率分布(j)。
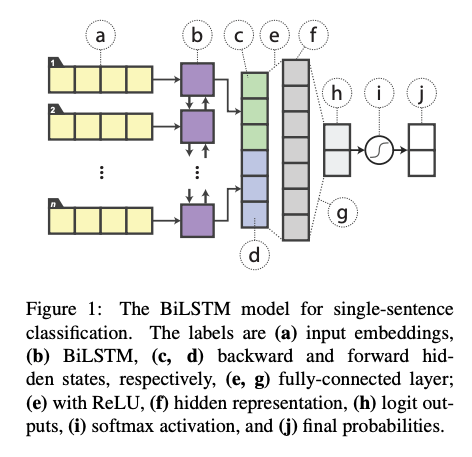
与原始BiLSTM相比,蒸馏bert是用fine-tuned Bert对文本(a)的输出logits与BiLSTM的学习的logits(h)做均方误差,使Bert能将知识转移给BiLSTM,也就是BiLSTM的输出与bert的输出接近,这便是teacher与student的含义。
损失函数如下: %20L_%7BMSE%7D%20%5C%5C%20%20%20%26%3D%20-%20%5Calpha%20%5Ctextstyle%5Csum_%7Bi%3D1%7D%5En%20t_%7Bi%7Dlog%7By_%7Bi%7D%5E%7B(S)%7D%7D%20%2B%20(1-%5Calpha)%20%7C%7Cz%5E%7B(T)%7D-z%5E%7B(S)%7D%7C%7C_%7B2%7D%5E%7B2%7D%20%5Cend%7Baligned%7D)
模型效果
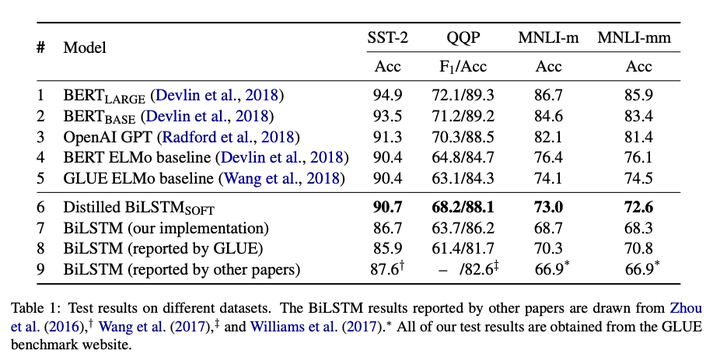
蒸馏后的BiLSTM在GLUE语料上的效果均优于普通的BiLSTM,在SST-2和QQP任务上效果与ELMo类似。
https://github.com/xiaopp123/knowledge_distillation
TinyBERT: Distilling BERT for Natural Language Understanding
背景
为提高bert的推理和计算性能,论文提出使用Transformer蒸馏方式将Bert蒸馏至TinyBert,另外,论文还提出两阶段的学习框架,即预训练阶段和fine-tuning阶段都对Bert蒸馏。蒸馏后的TinyBert在GLUE任务集上能达到原始Bert的96.8%,模型大小比原来减少到7.5倍,推理性能提高到9.4倍。
模型结构
Transformer包含两部分:MHA(多头注意力层)和FFN(前馈神经网络)。如图所示,Transformer蒸馏方式正是基于MHA和FFN隐藏状态进行蒸馏的。
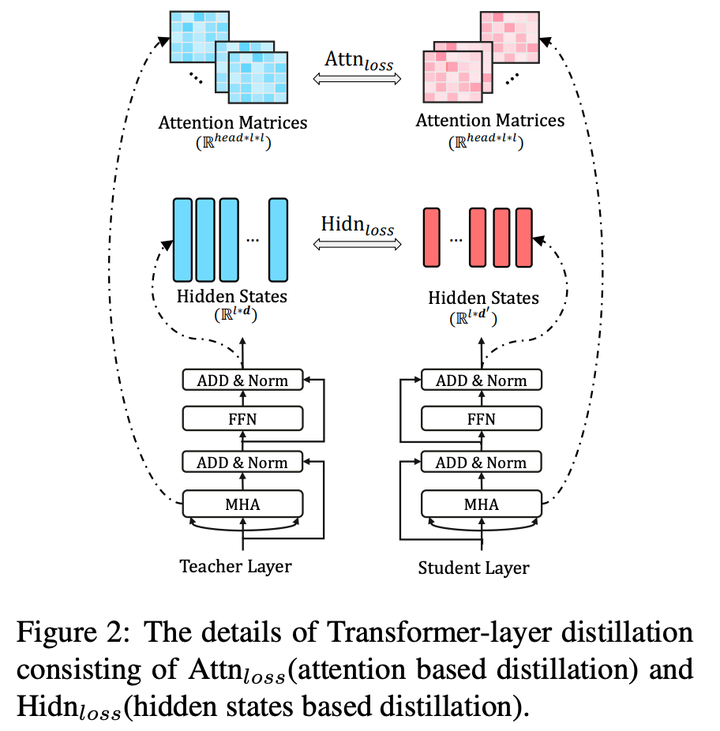
attention层蒸馏的损失函数如下,其中  表示head number,
表示head number, 表示第
表示第  i 个head的注意力矩阵,维度为
i 个head的注意力矩阵,维度为  ,
,  表示序列长度,这个损失函数的作用是使学生模型能学到教师模型中的注意力矩阵。
表示序列长度,这个损失函数的作用是使学生模型能学到教师模型中的注意力矩阵。
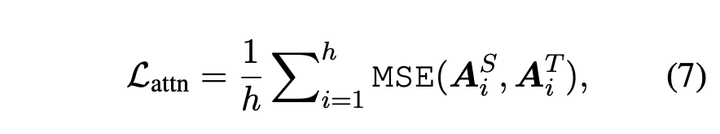
FNN隐藏蒸馏的损失函数如下,其中 表示教师模型FNN网络的输出,维度为
表示教师模型FNN网络的输出,维度为  ,
, 表示学生模型FNN网络的输出,维度为
表示学生模型FNN网络的输出,维度为  ,一般情况下,
,一般情况下,  ,
, 表示映射矩阵,维度为
表示映射矩阵,维度为  ,即将学生网络输出映射到教师网络输出向量维度上。
,即将学生网络输出映射到教师网络输出向量维度上。
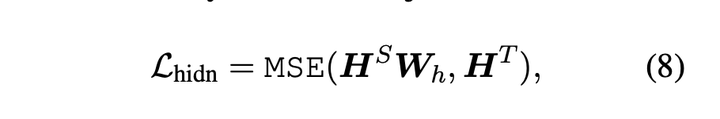
与FNN层蒸馏方式相同,论文对embedding层也进行蒸馏,损失函数如下所示:
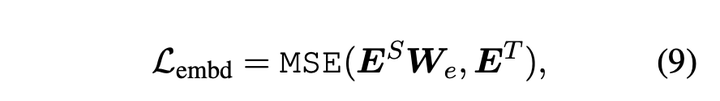
输出层蒸馏
论文计算教师网络和学生网络输出logits的交叉熵作为输出层蒸馏损失函数
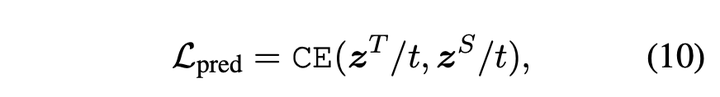
输出层蒸馏损失函数
综上,模型的蒸馏函数为:
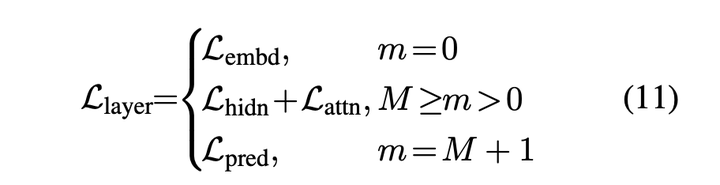
TinyBert学习过程分为两步:General Distillation和Task-specific Distillation。
Generation Distillation是指预训练阶段蒸馏,这部分使用的是通用数据集故称为General Distillation。
预训练阶段训练的TinyBert由于参数较少,与原始Bert相比在下游任务中的效果必然有损,因此论文提出针对下游任务的Task-specific Distillation,该过程以原始Bert作为教师模型,TinyBert作为学生模型在特定数据集上进行蒸馏学习。
实现代码
在下文fine-tuning任务,分两步进行训练,第一步是蒸馏Transformer,第二步是蒸馏下游任务输出层
Transormer蒸馏

# Transformer蒸馏 # 教师网络层数大于学生网络 teacher_layer_num = len(teacher_atts) student_layer_num = len(student_atts) assert teacher_layer_num % student_layer_num == 0 layers_per_block = int(teacher_layer_num / student_layer_num) # attention层蒸馏 # 学生网络第i层学习教师网络第i * layers_per_block + layers_per_block - 1层 # 若学生网络是3,教师网络为12,则第0层学习第3层,第1层学第7层 new_teacher_atts = [teacher_atts[i * layers_per_block + layers_per_block - 1] for i in range(student_layer_num)] for student_att, teacher_att in zip(student_atts, new_teacher_atts): student_att = torch.where(student_att <= -1e2, torch.zeros_like(student_att).to(device), student_att) teacher_att = torch.where(teacher_att <= -1e2, torch.zeros_like(teacher_att).to(device), teacher_att) # attention层蒸馏损失为均方误差 tmp_loss = loss_mse(student_att, teacher_att) att_loss += tmp_loss # 前馈神经网络层和Embedding层蒸馏 # 学生第0层学习教师第0层,第0层是embedding层输出 # 第i层学习第layers_per_block * i层 new_teacher_reps = [teacher_reps[i * layers_per_block] for i in range(student_layer_num + 1)] new_student_reps = student_reps # 前馈神经网络层和Embedding层蒸馏均方误差 for student_rep, teacher_rep in zip(new_student_reps, new_teacher_reps): tmp_loss = loss_mse(student_rep, teacher_rep) rep_loss += tmp_loss loss = rep_loss + att_loss
输出层蒸馏
# 输出层蒸馏 # 分类任务是教师网络和学生网络输出logits交叉熵 if output_mode == "classification": cls_loss = soft_cross_entropy(student_logits / args.temperature, teacher_logits / args.temperature) elif output_mode == "regression": loss_mse = MSELoss() cls_loss = loss_mse(student_logits.view(-1), label_ids.view(-1)) loss = cls_loss
这里重点讲一下如何针对具体下游任务进行fine-tuning:
数据准备
这里可以是自己的数据集,也可以是GLUE任务。
预训练模型
需要下载Bert预训练模型和TinyBert预训练模型。
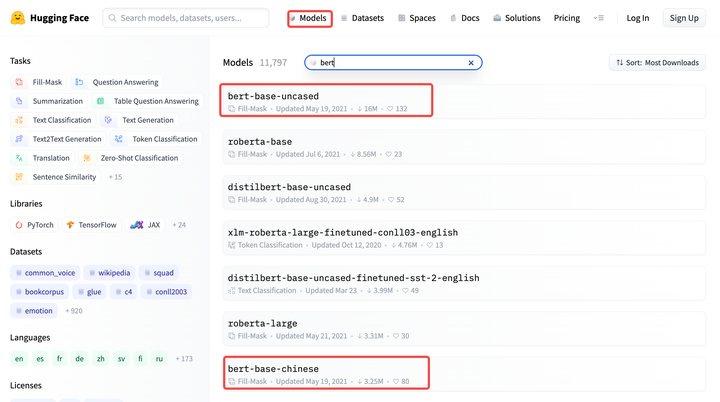
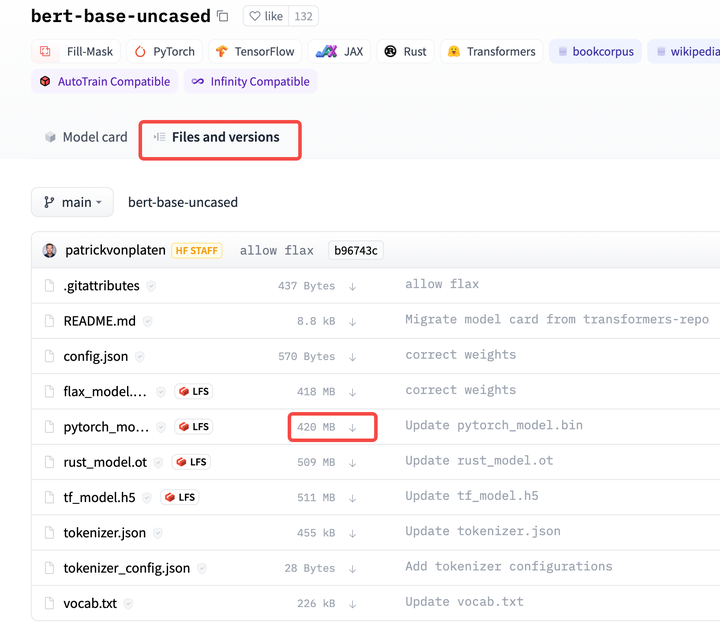
Bert预训练模型在HuggingFace官网“Model”模块输入bert,找到适合自己的bert预训练模型,在“Files and versions”选择自己需要模型和文件下载,目前好像只能一个一个文件下载。
TinyBert预训练模型:huawei-noah (HUAWEI Noah's Ark Lab)
Transformer蒸馏
python task_distill.py --teacher_model ${FT_BERT_BASE_DIR}$ \ --student_model ${GENERAL_TINYBERT_DIR}$ \ --data_dir ${TASK_DIR}$ \ --task_name ${TASK_NAME}$ \ --output_dir ${TMP_TINYBERT_DIR}$ \ --max_seq_length 128 \ --train_batch_size 32 \ --num_train_epochs 10 \ --aug_train \ --do_lower_case
输出层蒸馏
python task_distill.py --pred_distill \ --teacher_model ${FT_BERT_BASE_DIR}$ \ --student_model ${TMP_TINYBERT_DIR}$ \ --data_dir ${TASK_DIR}$ \ --task_name ${TASK_NAME}$ \ --output_dir ${TINYBERT_DIR}$ \ --aug_train \ --do_lower_case \ --learning_rate 3e-5 \ --num_train_epochs 3 \ --eval_step 100 \ --max_seq_length 128 \ --train_batch_size 32
参考
-
https://github.com/airaria/TextBrewer
-
https://github.com/qiangsiwei/bert_distill
-
https://towardsdatascience.com/simple-tutorial-for-distilling-bert-99883894e90a


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?