
bert论文笔记
https://zhuanlan.zhihu.com/p/74547224
摘要
BERT是“Bidirectional Encoder Representations from Transformers"的简称,顾名思义,它使用transformer联合上下文学习文本的双向表示。在这个表示的基础上,只需要一个额外的输出层,就可以根据特定的任务对预训练的bert进行微调,无需再对特定任务进行大量模型结构的修改。
本文提出使用bert对fine-tuning方法进行改进。受完形填空任务启发,BERT提出一个新的训练任务解决单向语言模型约束,即“masked language model“,该任务是从输入中随机遮蔽一些单词,根据遮蔽单词上下文来预测遮蔽词原始id,与从左到右的单向语言模型预训练不同,MLM任务能学习到单词的上下文信息。除MLM外,论文还提出一个联合训练文本对来进行“下一个句子预测"任务。
论文贡献:
1、论证了双向预训练对语言表征的重要性。BERT使用遮蔽语言模型来实现预训练的深层双向表示,ELMO则是使用一个由左到右和由右到左的独立训练语言模型的浅层连接。
2、预训练的表示消除了许多特定于任务的高度工程化的模型结构的需求,bert是第一个采用fine-tuning模式,优于许多特定于任务的结构的模型。
3、在消融研究中证明,模型的双向特征是重要的贡献。
2.相关工作
基于特征的方法(feature-based)
Feature-based指利用语言模型结果,将其作为额外的特征,引入到原任务模型中。
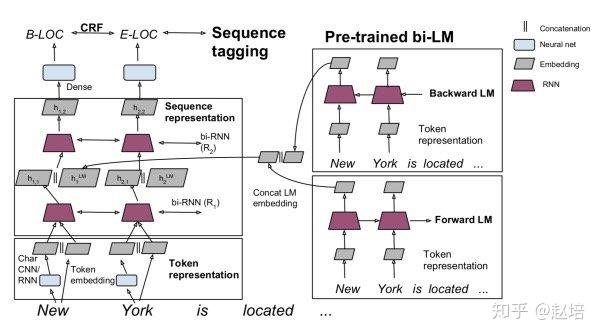
如图所示:左边是序列标注模型,即task-specific model,右边是双向的语言模型,并将语言模型结果与第一层rnn的输出进行concate操作,即特征增强。
feature-based方法分为两步:
1、先在大的语料上进行无监督的训练语言模型,得到语言模型
2、然后构造特定任务模型,如序列标注模型,使用任务语料训练任务模型,将语言模型的参数固定,任务语料经过语言模型得到的LM Embedding作为任务模型的额外特征。
基于微调的方法(fine-tuning)
Fine-tuning就是在已经训练好的语言模型基础上,加入少量具体任务的参数,例如对于分类问题在语言模型基础上增加一层softmax网络,然后在新的语料上重新进行训练,从而fine-tuning参数。
fine-tuning方法步骤:
1、先在大的语料上进行无监督的训练语言模型,得到语言模型
2、在语言模型基础上增加少量神经网络层来完成具体任务,如序列标注,分类,然后使用有标记的任务语料有监督的训练模型,这个过程语言模型的参数并不固定,依然是可以训练的。
从有监督的数据中迁移学习
迁移学习:当前任务的数据很少,如何利于预训练的模型来完成该任务。
方法有许多种:如可以直接使用最后的输出来做下游任务,也可以直接使用某一层网络,或者使用fine-tuning方式。 总之,迁移学习关心的问题是:什么是“知识”以及如何更好的运用之前得到的“知识”。方法和手段就很多,fine-tuning只是其中的一种手段。----迁移学习与fine-tuning有什么区别?
3.BERT
这部分介绍bert的细节和实现,首先介绍BERT模型的结构和输入表示,接下来是论文核心创新-预训练任务,预训练和fine-tuning紧随其后,最后是BERT和GPT的区别。
3.1模型结构
BERT的结构基于多层双向的Transformer编码器。
表示层的数量(即Transformer块)为L, 隐藏尺寸为H,自注意头的个数为A,在所有例子中,将前馈/过滤器的大小设置为4H,即H=768时是3072,【为什么是4倍,H为什么是768】
bert两个模型大小结果为:
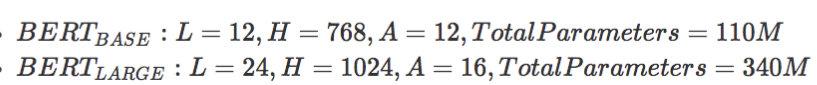
3.2输入表示
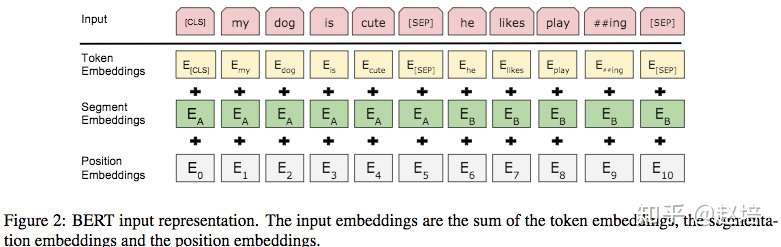
输入可以是单个文本句子或者一对句子,一个输入序列中,输入嵌入是词嵌入(token embedding)、句子嵌入(segment embedding)和位置嵌入(position embedding)的总和。
1、词嵌入使用WordPiece嵌入。一文读懂BERT中的WordPiece
2、使用学习到的位置嵌入,支持的序列长度最长可达512个标记。[预训练的?]
3、对于输入序列在开始加一个特殊的分类嵌入([CLS]),这个特殊的标记的最终的输出作为分类任务中的句向量,而对于非分类任务,这个标记的输出可以忽略。
4、 句子打包在一起形成输入序列,使用两种方法区分这些句子。方法一:两个句子之间使用特殊标记([SEP])将它们分开;方法二、给第一个句子的每个token添加一个可训练的句子A嵌入,给第二个句子的每个token添加可训练的句子B的嵌入。
5、对于单句的输入,使用句子A的嵌入。
3.3 预训练任务
预训练时使用Mask 语言模型和Next Sentence Prediction多任务训练方式。
3.3.1 Mask 语言模型
直观上,深层双向建模比单向或者双向的浅层连接效果好,但是,在标准的条件语言模型只能从左到右或者从右到左进行训练,因为在深层双向建模过程中会使得每个单词在多层上下文中间接的“看到自己”。
为了训练深层双向表示,作者按一定比例对输入单词随机Mask,然后预测这些被Mask的单词。 在实验中,每个序列随机Mask 15%单词, 并让模型预测这些被Mask的单词。
这里有两个缺点:
第一:预训练和微调之间造成不匹配,因为在微调时不会出现[MASK]标记。所以,并不能总是用[MASK]标记替换被选择的单词,而是在训练数据随机选择15%进行候选标记,在这15%的候选标记中,80%使用[MASK]替换被选择的单词,10%用一个随机单词替换被选择单词,10%保持被选择单词不变。这样做的效果就是Transformer不知道它将要预测哪些单词,或者哪些单词已经被随机替换,因此它被迫保持每个输入标记的上下文的表示。另外,因为随机替换只发生在1.5%的标记,这似乎不会损害模型的语言理解能力。

.
第二:使用Transformer的每批数据只有15%的标记被预测,这意味着模型需要更多的预训练步骤进行收敛。论文证明,Transformer比从左到右的模型稍微慢一些,但是效果远远超过了它增加的预训练模型的成本。
3.3.2 下一句预测
在许多重要的下游任务,如问答(QA)和自然语言推理(NLI),都是建立在理解两个文本句子之间的关系基础上,这不是语言建模直接可以捕获到的。为了训练一个理解句子关系的模型,作者预训练了一个「下一句预测」的二分类任务,这个任务要求bert的输入是两个句子,即句子A和句子B,50%的情况下B是A的下一个句子,50%的情况下B不是A的下一个句子,即随机从语料库中选择一个句子作为B。 这个任务的增加对句子级别的任务非常有益。
3.4预训练过程
为得到bert的输入序列,作者从语料库中采样两段文本,称其为“句子”。第一个句子添加A嵌入,第二个句子添加B嵌入,50%的情况下B是A后面的下一句,50%的情况下它是随机选取的一个句子,这是为“下一句预测"任务所做的。两句话合起来的长度要小于等于512。语言模型的Mask过程是在使用WordPiece序列化句子后,以均匀的15%的概率遮蔽标记,不考虑部分词片的影响。 论文中使用batch size为256(256 * 512 = 128000个标记)的批大小进行训练,使用Adam优化算法并设置学习率为1e-4,\beta1 = 0.9, \beta2 = 0.999, L2权重衰减是0.01,在训练前10000步学习率热身,然后线性衰减,drop值设置为0.1, 使用glue激活函数。 训练损失是Mask语言模型和下一句预测似然值的平均值。
3.5fine-tuning
对于分类任务,bert使用最后[CLS]的embedding作为整体的句向量,进行分类。
在fine-tuning过程中,除了训练次数、batch size和学习率外,大多数模型超参数与预训练相同。
另外大的数据集对超参数的选择敏感性远远低于小数据集。
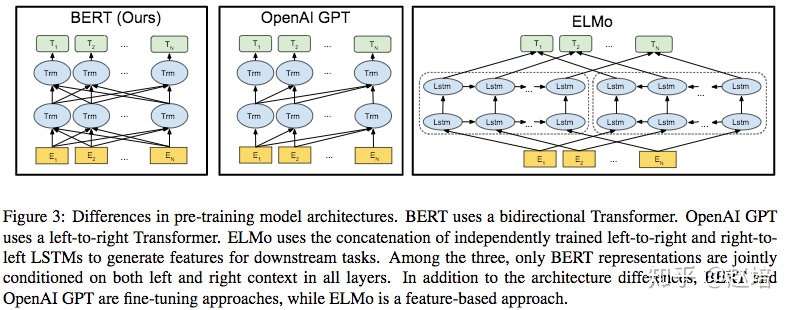
3.6bert与GPT的对比
主要的区别就是BERT使用了双向语言模型,并使用mask语言模型和下一句预测联合训练。
4、实验
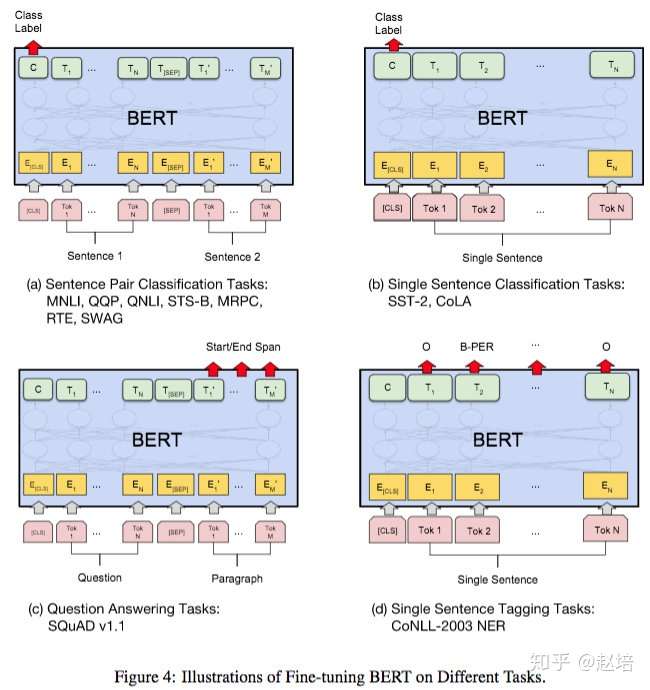
4 消融试验
4.1预训练任务的影响
bert中通过mask语言模型预训练的深层双向模型是最重要的改进。为了验证这个,论文做了两个模型:
1、No NSP:模型使用mask语言模型但是没有预测下一句话
2、LTR&No NSP:模型使用从左到右的语言模型,而不是mask语言模型,另外该模型也未经预测下一句话任务的预训练。
结果显示除去NSP任务对句级别任务造成了显著伤害。
在No NSP和LTR上,LTR在所有任务上都比No NSP表现的差,在MRPC和SQuAD上降的特别厉害,对于SQuAD来说,很明显LTR模型在区间和标记预测方面表现很差,因为标记级别的隐藏状态没有右侧上下文。 可以向ELMO那样独立训练LTR和RTL模型,并将每个标记表示为两个模型表示的连接,但是(a)这样训练成本比训练一个双向模型成本高(b)对像QA这样的任务来说不合理,因为RTL模型无法给出问题的答案(c)这比深层双向模型效果要弱得多,因为深层双向模型可以在每一层都学习上下文信息
4.2模型大小影响
模型大小将持续提升在大型任务上的表现,如果模型得到了足够预训练训练,那么将模型扩展到极端的规模也可以在非常小的任务上带来巨大的改进。
4.3使用bert基于特征的方法
与feature-based相比,fine-tuning方式效果更好。
参考
[1] ref="https://github.com/yuanxiaosc/BERT_Paper_Chinese_Translation">BERTPaperChinese_Translation.
[2] BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding.
[3] BERT模型及fine-tuning.
[4] 迁移学习与fine-tuning有什么区别?

