Transformer【Attention is all you need】
前言
Transfomer是一种encoder-decoder模型,在机器翻译领域主要就是通过encoder-decoder即seq2seq,将源语言(x1, x2 ... xn) 通过编码,再解码的方式映射成(y1, y2 ... ym), 之前的做法是用RNN进行encode-decoder,但是由于RNN在某一时间刻的输入是依赖于上一时间刻的输出,所以RNN不能并行处理,导致效率低效,而Transfomer就避开了RNN,因此encoder-decoder效率高。
Transformer
从一个高的角度来看Transformer,它就是将源语言 转换 成目标语言

打开Transformer单元,我们会发现有两个部分组成,分别是encoders单元和decoders单元
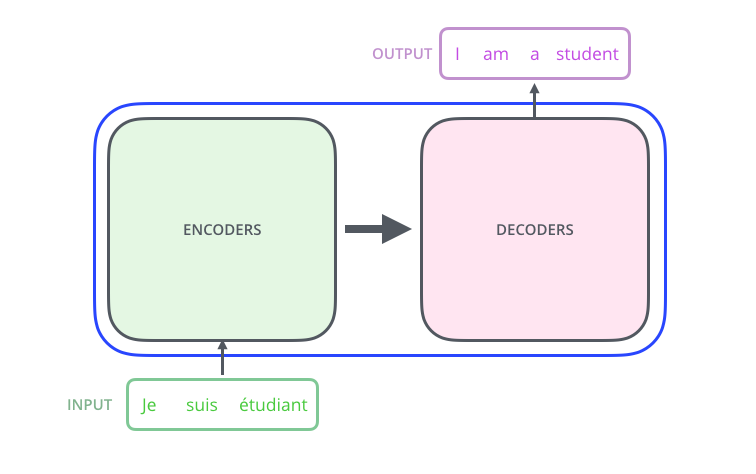
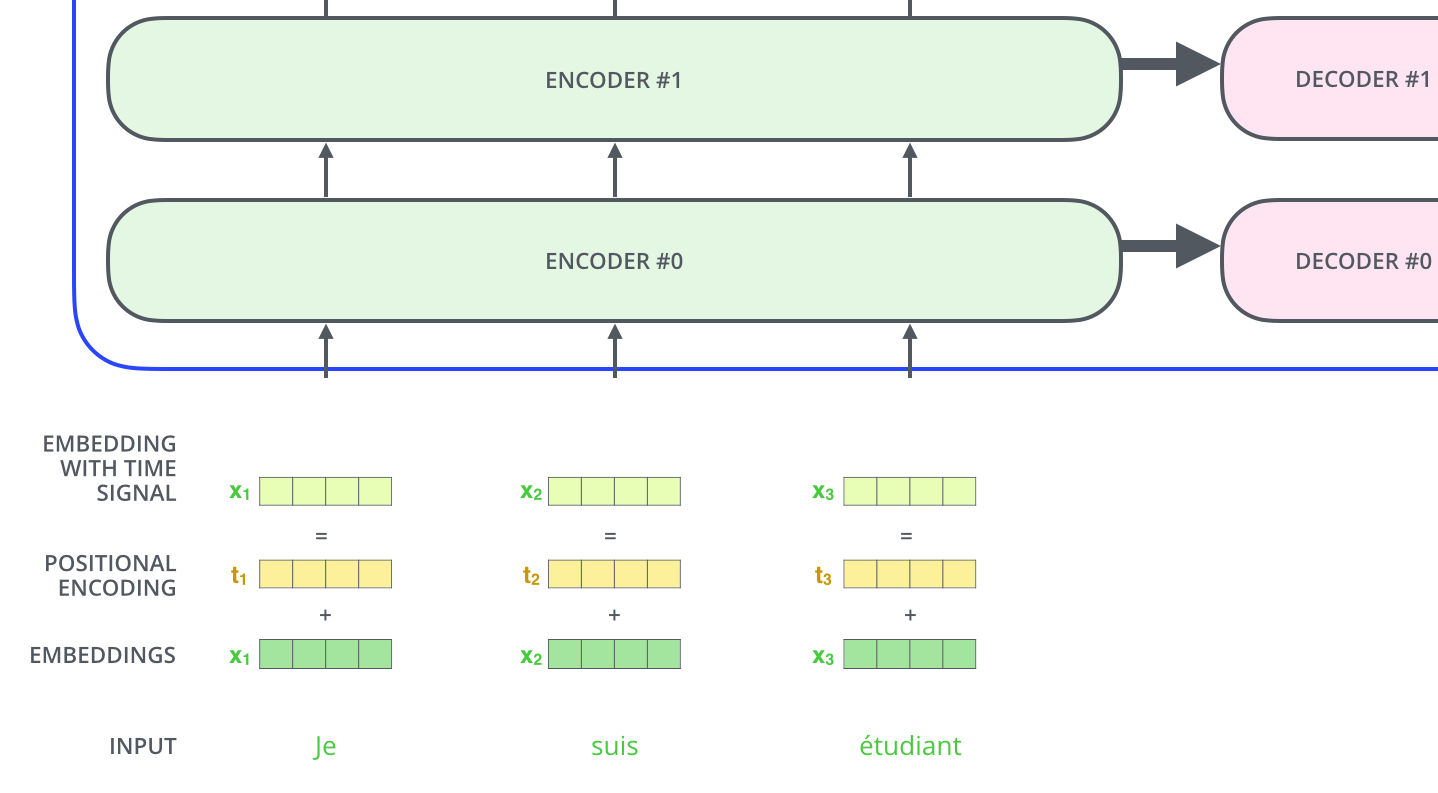
而对于encoders单元,它是由六个encoder组成的,同样decoders单元,它也是由六个decoders组成。

对于每一个encoder,它们结构都一样的,但是权重不共享,每一个encoder的结构都是由两部分组成,分别是self-attention和feed forward neural network。
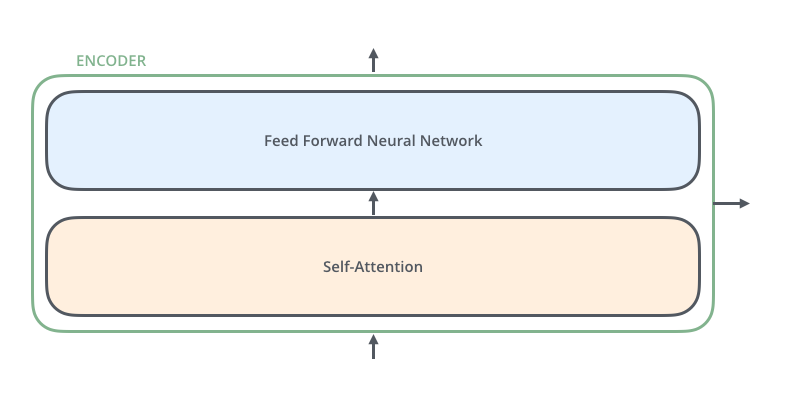
Transformer的处理流程是这样的:输入数据传给self-attention,然后selft-attention计算每一个位置的与其他位置的相关性,从而获得每一个位置的输出结果,该输出结果传给FFNN,得到第一个encoder的输出z1,z1作为第二个encoder的输入,步骤如上,直到最后一个encoder输出 ouput。
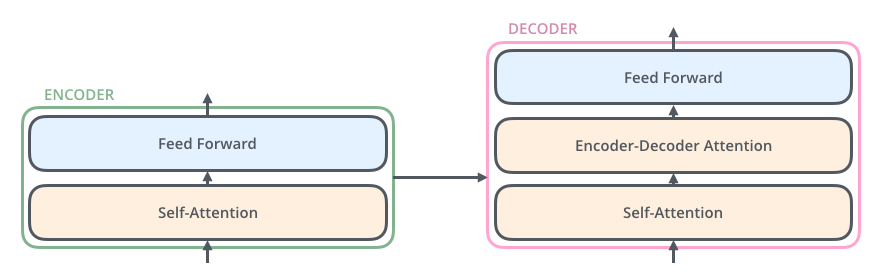
该输出ouput,在传给decoder,大致过程和encoder一致,有些许差异,稍后分析。
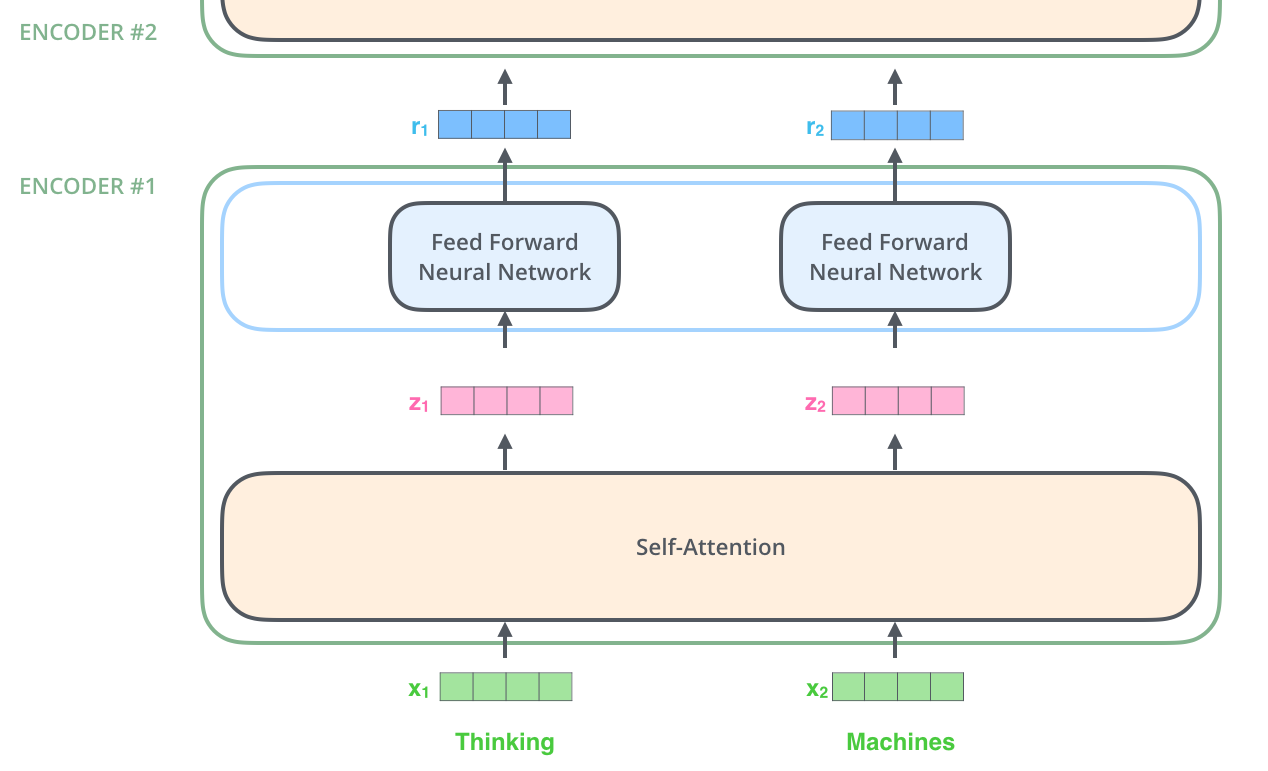
具体示例:
假设输入的是两个单词:Thinking Machine, 首先对单词作embedding,然后作为第一个encoder的输入,在第一个encoder里面经过self-attention,得到zi,然后zi经过FFNN得到第一个encoder的输出ri,然后ri像embedding一样,作为第二个encoder的输入
self-attention
selft-attention的作用就是求 某一位置与其他位置的相关性权重。
selft-attention执行流程:
第一步:
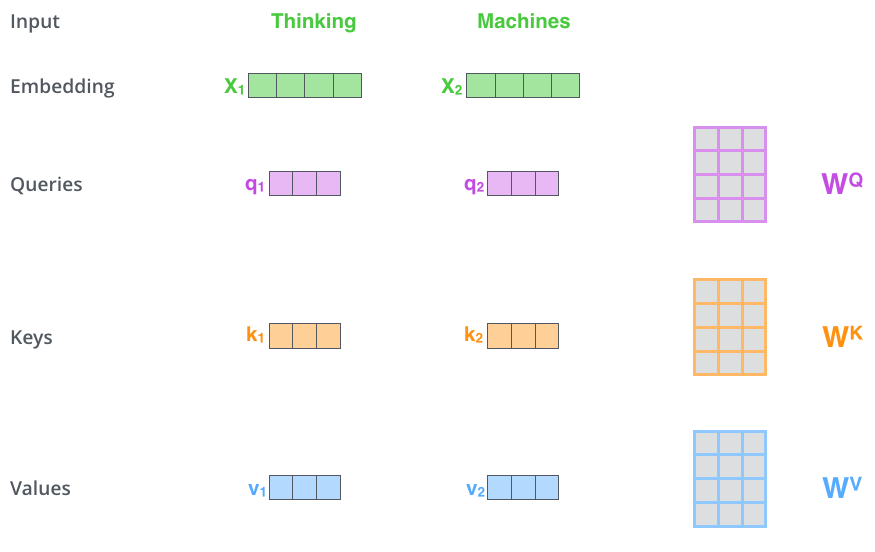
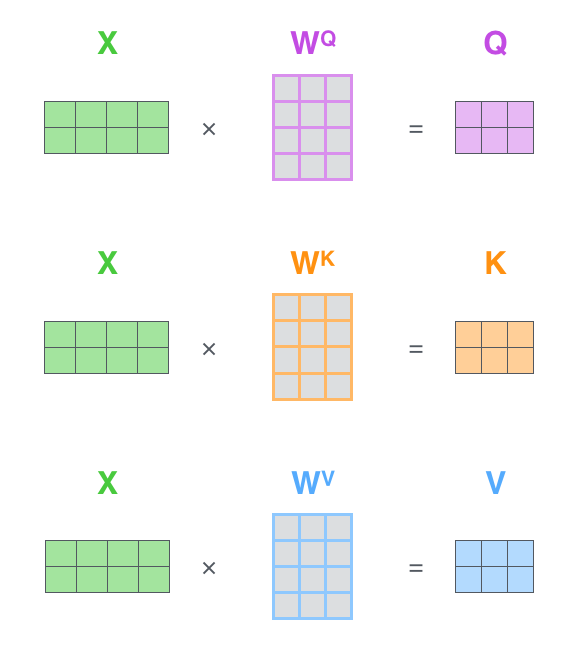
输入向量 embedding分别与三个权重矩阵(WQ WK ,WV)相乘,得到三个向量, Queries, Keys, Values。据说三个权重矩阵(WQ WK ,WV)是在训练过程中获得的,我很好奇它是怎么训练获得的。
还有就是 Queries, Keys, Values这三个向量的维度要比 embedding的维度小, Queries, Keys, Values的维度是64, embedding的维度是512。至于为什么要小,是为了便于multi-head计算
第二步:
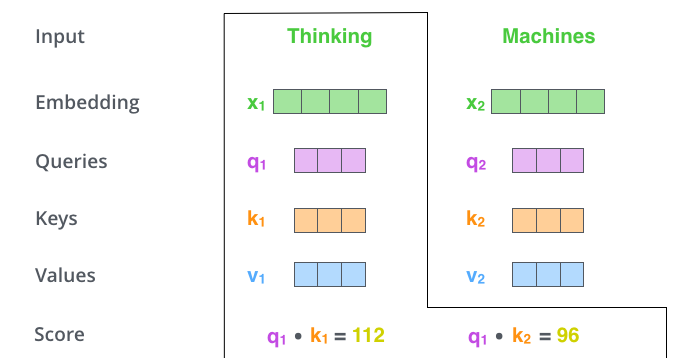
计算每一个位置与其他位置的得分。
如图,以第一个单词Thinking为例,用q1分别与不同位置的keys向量ki进行点积,得到与每其他位置的得分。
第三步
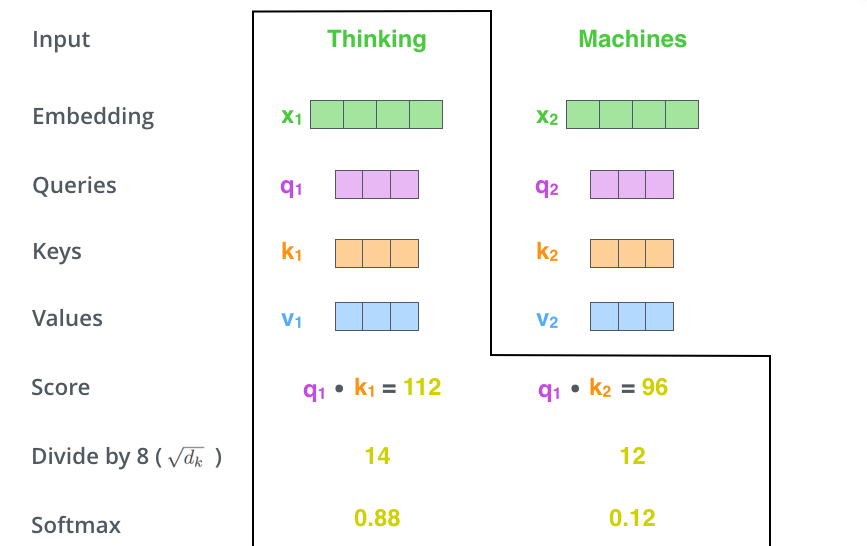
将得分 除以 8, keys的维度平方根,paper是64。
第四步
对得分进行sotfmax
第五步:
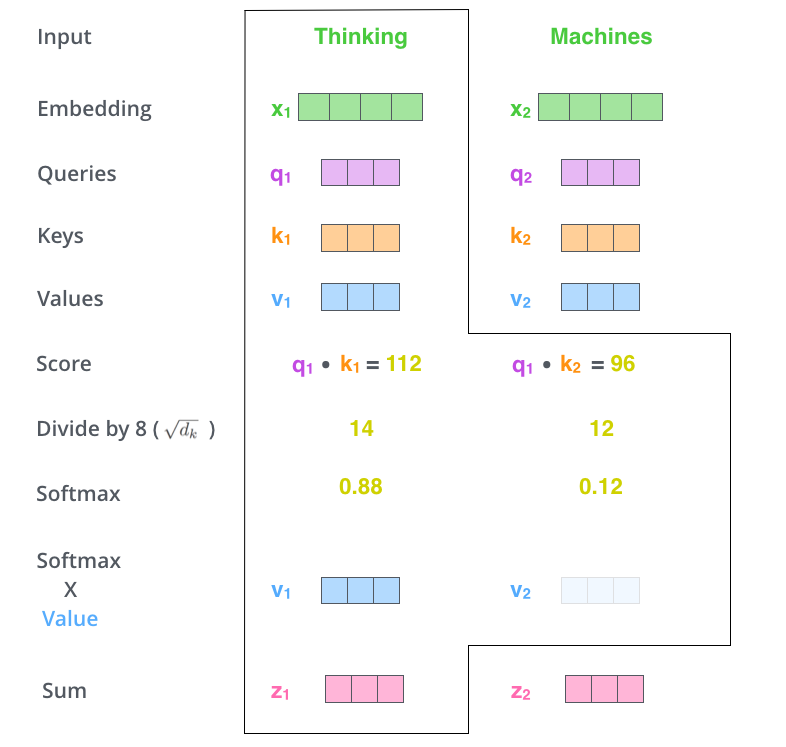
用softmax的得分(权重) 乘以 对应位置的values向量,
第六步:
对加权values向量求和
以上是对于一个单词的运算过程,可以用矩阵对整个输入序列进行操作
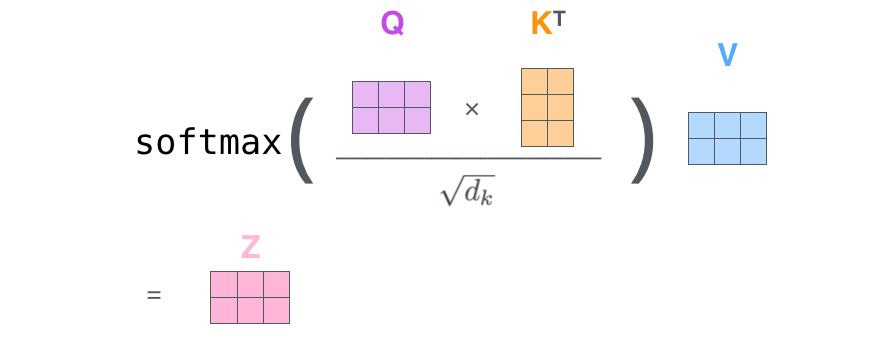
优化Multi-head
motivation:
1、对于上面的计算过程,最后的到z1仅包含与他相关的那些位置的信息,而其他位置信息就包含的较少,Multi-headed可以覆盖到每一个位置的信息 (不太理解,不就是要找到最相关的位置吗, 为什么要其他的都包含呢)
2、它为attention层提供了更多的表示空间。在上面的计算过程中,都产生了一个 Queries,Keys, Values的权重矩阵,Transformer使用了八个head,每一个head相当于一个独立的子空间,在这里将随机初始化 Queries,Keys, Values的权重矩阵,所以最终会有八个权重矩阵,也就是会有八个 Queries,Keys, Values向量。
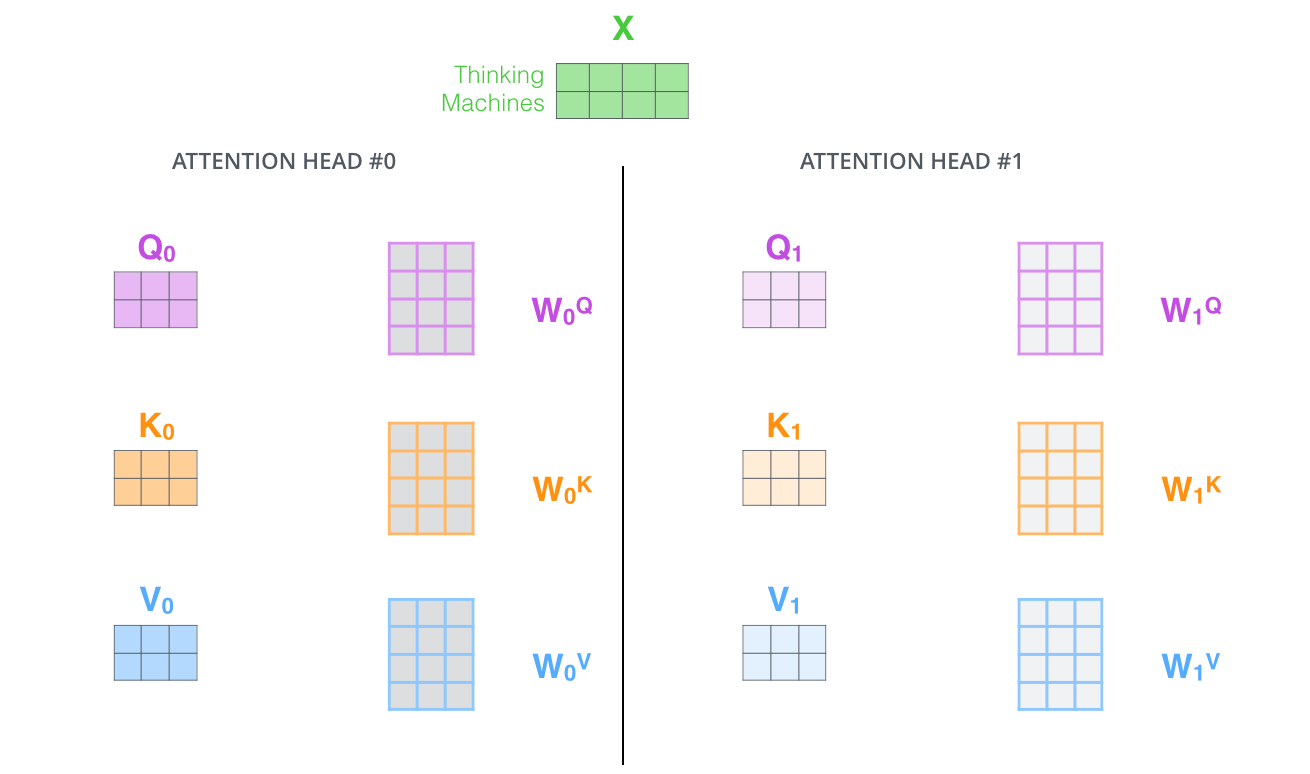
与之前一样的计算方式,embeding需要与每一个head进行计算,最后会有八个输出
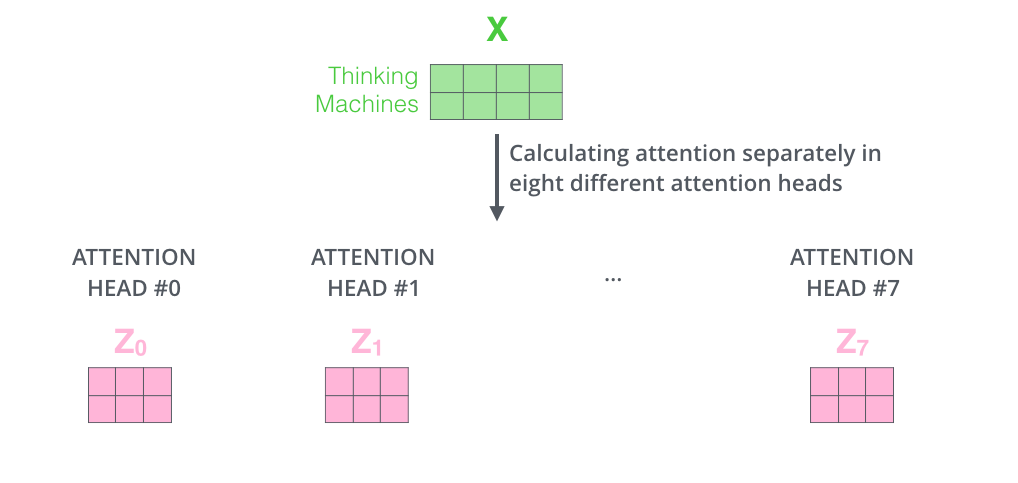
然后八个输出拼接成一个向量,乘以 另一个权重矩阵Wo (怎么得到的?)得到最后的输出Z

multi-headed的整体过程如下:
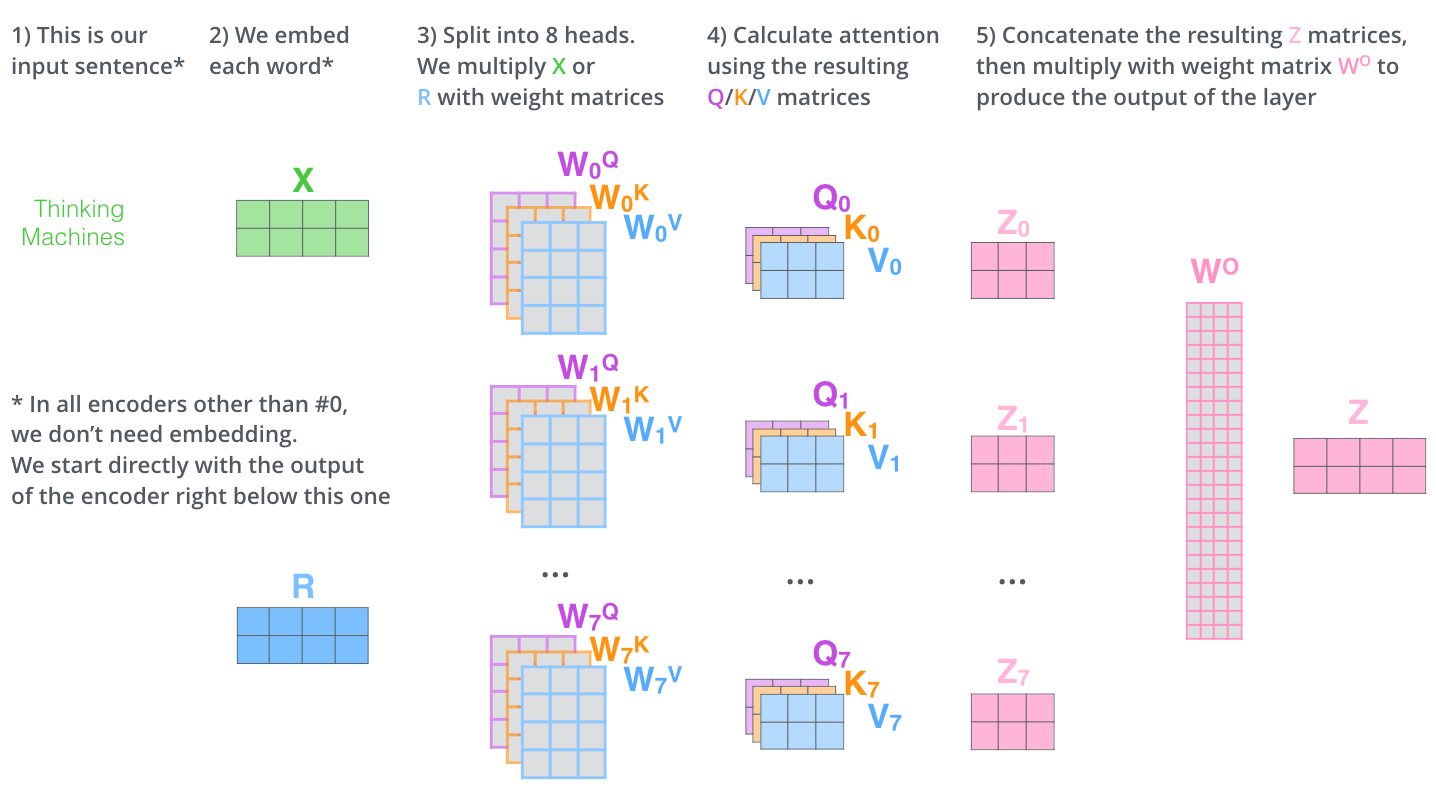
multi-headed与single-headed的效果:
single-headed只关注与他最相关的,也就是权重最大的,如左图。而Multi-headed会关注好的内容,如右图

Position-embedding
上面模型没有考虑位置信息,Transformer增加了一个位置向量,该位置向量是通过也是通过模型学习到的,(怎么学习到的?!),所以 embedding = positional-embeding + embedding
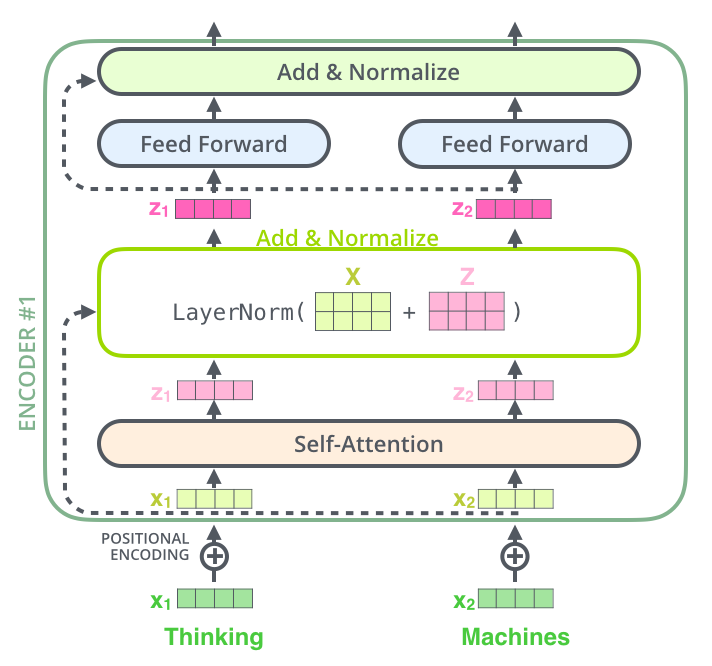
The Residuals
另外在 self-attention与FFNN之间还加入了 一个 residual connection,在这之后还有一个layer-normalization.
意义:为什么?!
对于一个2层的encoder-decoder,它们的架构如图所示:
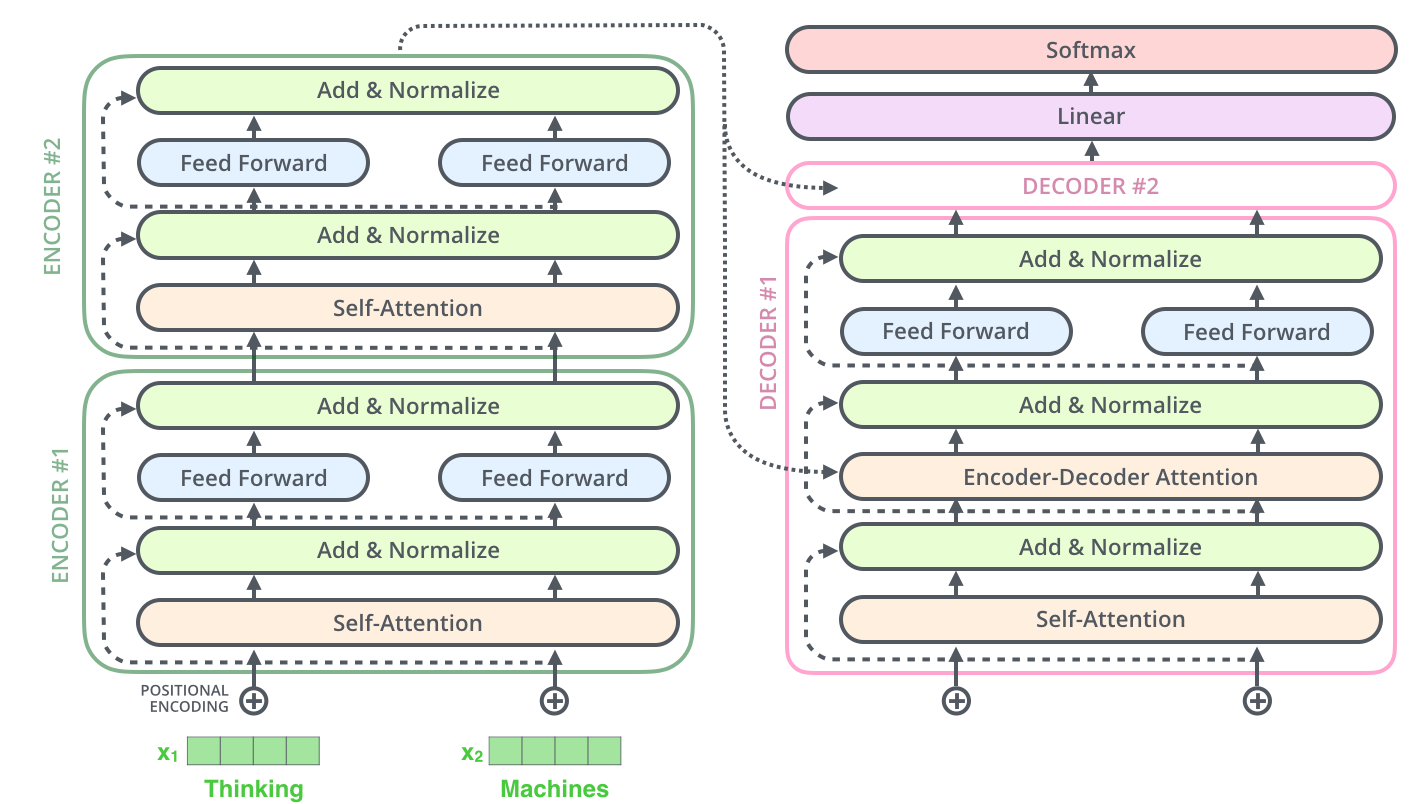
Decoder side
encoder最后一层的输出将被转化成 key, value向量,(怎么转化?!)这两个向量在 decoder中的encoder-decoder attention层共享。
decoder对于输入也和encoder一样加入位置编码,与encoder中selfattetion有些许区别,它只考虑该时间步之前的信息,
decoder中querry是怎样的呢?

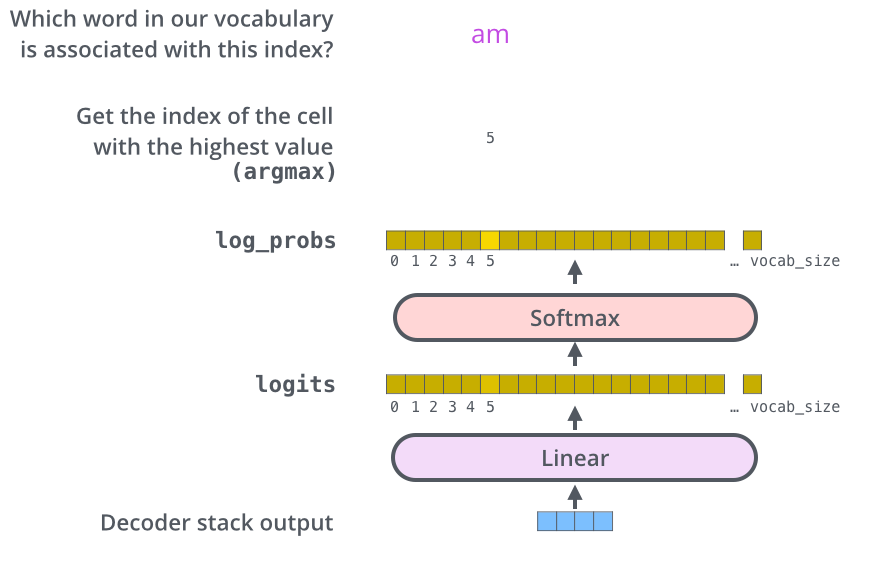
最后在加一个全连接层,softmax得到最后结果
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号