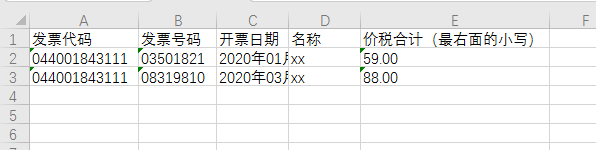
python读取当前以pdf结尾的文件并保存到excel文件里面
使用python读取当前以pdf结尾的文件并保存到excel文件里面
#!pip install PyMuPDF 调用fitz所需要使用的模块
import fitz
import openpyxl
import os
class Electronic:
def __init__(self,pdf_document,workbook,exsave):
self.LIST1 = []
self.LIST2 = []
self.pdf_document = pdf_document
self.workbook = workbook
self.exsave = exsave
self.wb = openpyxl.Workbook()
def invoice(self):
"""
读取数据
"""
doc = fitz.open(pdf_document)
page1 = doc.loadPage(0)
#读取excel里面的文本信息
self.LIST1.append(page1.getText("text"))
#切割回车符
LL = self.LIST1[0].split('\n')
#将读取的数据放入L2列表
self.LIST2.append(LL[75])
self.LIST2.append(LL[76])
self.LIST2.append(LL[77])
self.LIST2.append(LL[70])
#分隔空格后取出数值
self.LIST2.append(LL[79].split(' ')[1])
return self.LIST2
def pyexcel(self):
"""
插入数据
"""
self.wb = openpyxl.load_workbook(self.workbook)
#读取第一个单元薄
sh = self.wb['Sheet1']
#插入数据
sh.append(self.LIST2)
def save(self):
"""
保存数据
"""
self.wb.save(self.exsave)
# 关闭工作薄
self.wb.close()
if __name__ == '__main__':
workbook = '读取信息.xlsx'
exsave = '读取信息.xlsx'
#读取目录
path = os.getcwd()
#读取当前目录底下的文件
dir_file = os.listdir(path)
for i in dir_file:
#切割文件里面包含pdf结尾的文件
ii = i.endswith('.pdf')
if ii:
pdf_document = i
w = Electronic(pdf_document,workbook,exsave)
w.invoice()
w.pyexcel()
w.save()
#读取后的结果