Lesson01_Action1使用CART对MNIST分类
from sklearn.datasets import load_digits # 加载mnist数据集
from sklearn.preprocessing import StandardScaler, MinMaxScaler # 数据预处理-标准化
from sklearn.model_selection import train_test_split # 拆分数据集
from sklearn.tree import DecisionTreeClassifier, export_graphviz # 决策树分类模型, 输出决策树
from sklearn.metrics import accuracy_score # 评估模型 准确率
from matplotlib import pyplot as plt
digits = load_digits()
data = digits.data
target = digits.target
data.shape,target.shape
((1797, 64), (1797,))
#使用树模型不需要归一化,因为树模型只考虑相对大小
transfer = MinMaxScaler()
data = transfer.fit_transform(data)
拆分数据集
x_train,x_test,y_train,y_test = train_test_split(data,target,test_size=0.25,random_state=30)
x_train.shape,x_test.shape
((1347, 64), (450, 64))
y_train.shape,y_test.shape
((1347,), (450,))
#训练模型:
#基尼系数最小的准则,是在sklearn中的默认的划分依据
estimator = DecisionTreeClassifier(criterion='gini')
estimator.fit(x_train,y_train)
DecisionTreeClassifier()
#预测和评估
y_pred = estimator.predict(x_test)
y_pred[:10]
array([3, 8, 6, 5, 3, 3, 3, 2, 1, 2])
acc = accuracy_score(y_test,y_pred)
print("预测准确率为:{:.2f}%".format(acc * 100))
预测准确率为:84.44%
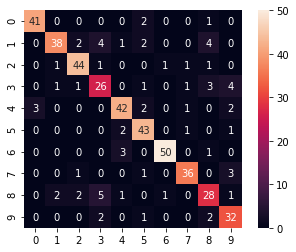
#预测结果混淆矩阵可视化
import seaborn as sns
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_pred)
cm
array([[41, 0, 0, 0, 0, 2, 0, 0, 1, 0],
[ 0, 38, 2, 4, 1, 2, 0, 0, 4, 0],
[ 0, 1, 44, 1, 0, 0, 1, 1, 1, 0],
[ 0, 1, 1, 26, 0, 1, 0, 1, 3, 4],
[ 3, 0, 0, 0, 42, 2, 0, 1, 0, 2],
[ 0, 0, 0, 0, 2, 43, 0, 1, 0, 1],
[ 0, 0, 0, 0, 3, 0, 50, 0, 1, 0],
[ 0, 0, 1, 0, 0, 1, 0, 36, 0, 3],
[ 0, 2, 2, 5, 1, 0, 1, 0, 28, 1],
[ 0, 0, 0, 2, 0, 1, 0, 0, 2, 32]], dtype=int64)
sns.heatmap(cm,annot=True,square=True)
plt.show()
export_graphviz(decision_tree=estimator,
out_file='./minist_CART_tree.dot')
#熟悉属性、方法
estimator.get_depth()#树的深度
14
estimator.get_n_leaves()#树的叶子节点数
140
dec_path = estimator.decision_path(x_train)
type(dec_path)
scipy.sparse.csr.csr_matrix
#返回树中的决策路径的稀疏矩阵
print(dec_path)
(0, 0) 1
(0, 32) 1
(0, 94) 1
(0, 144) 1
(0, 145) 1
(0, 157) 1
(0, 158) 1
(0, 162) 1
(0, 163) 1
(0, 175) 1
(0, 176) 1
(1, 0) 1
(1, 1) 1
(1, 2) 1
(1, 12) 1
(1, 14) 1
(1, 16) 1
(2, 0) 1
(2, 32) 1
(2, 94) 1
(2, 144) 1
(2, 145) 1
(2, 157) 1
(2, 183) 1
(2, 187) 1
: :
(1344, 144) 1
(1344, 200) 1
(1344, 201) 1
(1344, 221) 1
(1344, 222) 1
(1344, 234) 1
(1344, 235) 1
(1344, 239) 1
(1345, 0) 1
(1345, 1) 1
(1345, 2) 1
(1345, 12) 1
(1345, 14) 1
(1345, 16) 1
(1346, 0) 1
(1346, 32) 1
(1346, 94) 1
(1346, 144) 1
(1346, 145) 1
(1346, 157) 1
(1346, 158) 1
(1346, 162) 1
(1346, 178) 1
(1346, 179) 1
(1346, 180) 1
#稀疏矩阵的元组中第一个元素是数组的行索引,第二个元素应该是决策树中node的索引号,即数组的列索引
dec_path.toarray()
array([[1, 0, 0, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 0, 0, ..., 0, 0, 0],
...,
[1, 0, 0, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 0, 0, ..., 0, 0, 0]], dtype=int64)
#稀疏矩阵数组
#一共1347个样本,279个node
dec_path.toarray().shape
(1347, 279)
#特征的重要性(值越高,特征越重要)
estimator.feature_importances_
array([0. , 0.01087691, 0. , 0. , 0.01000771,
0.03892517, 0.00266332, 0.00442418, 0.00161759, 0.00412525,
0.00512906, 0.0016501 , 0.00425294, 0.01473198, 0.00082505,
0. , 0. , 0.00123758, 0.01155984, 0.02522066,
0.05415936, 0.08281241, 0. , 0. , 0. ,
0.00162305, 0.07636993, 0.04634309, 0.05791402, 0.00544033,
0.01487322, 0. , 0. , 0.05113273, 0.01787237,
0.0051784 , 0.07459433, 0.03054113, 0.00953599, 0. ,
0. , 0.01219702, 0.08933728, 0.0561104 , 0.01733228,
0.00509998, 0.00295643, 0. , 0. , 0. ,
0.00635548, 0.00743226, 0.00404733, 0.01326413, 0.02397377,
0. , 0. , 0.00297018, 0.00570801, 0.01465981,
0.06131626, 0.00234505, 0.0015841 , 0.00767254])
#维度等于n_features的数组
estimator.feature_importances_.shape
(64,)
#执行拟合时的输出数量
estimator.n_outputs_
1
推演决策树中一些指标计算过程:
import pandas as pd
import numpy as np
N = x_train.shape[0]
#样本数
N
1347
df = pd.DataFrame(x_train,columns=['X_%d'% i for i in range(x_train.shape[1])])
df
| X_0 | X_1 | X_2 | X_3 | X_4 | X_5 | X_6 | X_7 | X_8 | X_9 | ... | X_54 | X_55 | X_56 | X_57 | X_58 | X_59 | X_60 | X_61 | X_62 | X_63 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.8125 | 1.0000 | 1.0000 | 0.3125 | 0.0000 | 0.0 | 0.0 | 0.3125 | ... | 0.3750 | 0.0 | 0.0 | 0.0 | 0.9375 | 1.0000 | 1.0000 | 0.6250 | 0.0000 | 0.0 |
| 1 | 0.0 | 0.0 | 0.1250 | 0.6875 | 0.9375 | 0.1250 | 0.0000 | 0.0 | 0.0 | 0.0000 | ... | 0.0000 | 0.0 | 0.0 | 0.0 | 0.2500 | 1.0000 | 0.7500 | 0.0625 | 0.0000 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0000 | 0.0625 | 0.4375 | 0.9375 | 0.6875 | 0.0 | 0.0 | 0.0000 | ... | 0.0000 | 0.0 | 0.0 | 0.0 | 0.0000 | 0.0000 | 0.5625 | 0.3750 | 0.0000 | 0.0 |
| 3 | 0.0 | 0.0 | 0.1250 | 0.9375 | 0.9375 | 1.0000 | 0.6875 | 0.0 | 0.0 | 0.0000 | ... | 0.0000 | 0.0 | 0.0 | 0.0 | 0.2500 | 0.9375 | 0.4375 | 0.0000 | 0.0000 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0000 | 0.0000 | 0.3125 | 0.9375 | 0.5000 | 0.0 | 0.0 | 0.0000 | ... | 0.0625 | 0.0 | 0.0 | 0.0 | 0.0000 | 0.0000 | 0.5000 | 0.8750 | 0.0000 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1342 | 0.0 | 0.0 | 0.0000 | 0.1250 | 0.8750 | 0.3125 | 0.0000 | 0.0 | 0.0 | 0.0000 | ... | 0.0000 | 0.0 | 0.0 | 0.0 | 0.0000 | 0.2500 | 1.0000 | 0.4375 | 0.0000 | 0.0 |
| 1343 | 0.0 | 0.0 | 0.5000 | 0.8750 | 1.0000 | 1.0000 | 0.1250 | 0.0 | 0.0 | 0.0000 | ... | 0.0000 | 0.0 | 0.0 | 0.0 | 0.7500 | 0.4375 | 0.0000 | 0.0000 | 0.0000 | 0.0 |
| 1344 | 0.0 | 0.0 | 0.1875 | 0.6250 | 0.8750 | 0.1875 | 0.0000 | 0.0 | 0.0 | 0.5000 | ... | 0.7500 | 0.0 | 0.0 | 0.0 | 0.1250 | 0.6875 | 1.0000 | 1.0000 | 0.5625 | 0.0 |
| 1345 | 0.0 | 0.0 | 0.3750 | 0.8750 | 0.6875 | 0.0625 | 0.0000 | 0.0 | 0.0 | 0.0000 | ... | 0.0000 | 0.0 | 0.0 | 0.0 | 0.3125 | 0.8750 | 0.9375 | 0.2500 | 0.0000 | 0.0 |
| 1346 | 0.0 | 0.0 | 0.6875 | 0.6250 | 0.7500 | 0.8750 | 0.6875 | 0.0 | 0.0 | 0.0000 | ... | 0.0000 | 0.0 | 0.0 | 0.0 | 0.5625 | 0.8750 | 0.5625 | 0.1250 | 0.0000 | 0.0 |
1347 rows × 64 columns
desc = df.describe().T
desc
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| X_0 | 1347.0 | 0.000000 | 0.000000 | 0.0 | 0.0000 | 0.0000 | 0.0000 | 0.0 |
| X_1 | 1347.0 | 0.038512 | 0.113674 | 0.0 | 0.0000 | 0.0000 | 0.0000 | 1.0 |
| X_2 | 1347.0 | 0.325863 | 0.296793 | 0.0 | 0.0625 | 0.2500 | 0.5625 | 1.0 |
| X_3 | 1347.0 | 0.736405 | 0.269557 | 0.0 | 0.6250 | 0.8125 | 0.9375 | 1.0 |
| X_4 | 1347.0 | 0.743458 | 0.267270 | 0.0 | 0.6250 | 0.8125 | 0.9375 | 1.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| X_59 | 1347.0 | 0.752227 | 0.278157 | 0.0 | 0.6250 | 0.8125 | 1.0000 | 1.0 |
| X_60 | 1347.0 | 0.736359 | 0.310159 | 0.0 | 0.6250 | 0.8750 | 1.0000 | 1.0 |
| X_61 | 1347.0 | 0.417919 | 0.365054 | 0.0 | 0.0000 | 0.3750 | 0.7500 | 1.0 |
| X_62 | 1347.0 | 0.121334 | 0.248453 | 0.0 | 0.0000 | 0.0000 | 0.0625 | 1.0 |
| X_63 | 1347.0 | 0.020973 | 0.113492 | 0.0 | 0.0000 | 0.0000 | 0.0000 | 1.0 |
64 rows × 8 columns
desc.loc['X_36']
count 1347.000000
mean 0.640497
std 0.376634
min 0.000000
25% 0.312500
50% 0.812500
75% 1.000000
max 1.000000
Name: X_36, dtype: float64
根节点总基尼系数
决策树可视化文件中根节点的内容如下:
X[36] <= 0.031
gini = 0.9
samples = 1347
value = [134, 131, 128, 146, 131, 135, 127, 138, 134, 143]
第一行代表X的第36个特征中是否 <= 0.031;gini是总的基尼系数;samples代表总样本数;value代表每个label中的样本数。
sr = pd.Series(y_train)
sr.shape
(1347,)
#y_train中每个label的样本数量,按label排序
sr.value_counts().sort_index()
0 134
1 131
2 128
3 146
4 131
5 135
6 127
7 138
8 134
9 143
dtype: int64
y_value_counts = sr.value_counts().sort_index()
#总基尼系数
gini = 1- sum([(n / N ) ** 2 for n in y_value_counts])
gini
0.89981255604442
第二层节点
第二层左节点:gini是当特征X_36>0.031时label的基尼系数;samples代表当特征X_36>0.031时的总样本数;value代表当特征X_36>0.031时每个label中的样本数。
X[28] <= 0.156
gini = 0.569
samples = 218
value = [132, 0, 4, 0, 5, 20, 4, 0, 2, 51]
第二层右节点:gini是当特征X_36<=0.031时label的基尼系数;samples代表当特征X_36<=0.031时的总样本数;value代表当特征X_36<=0.031时每个label中的样本数。
X[21] <= 0.031
gini = 0.888
samples = 1129
value = [2, 131, 124, 146, 126, 115, 123, 138, 132, 92]
desc.loc['X_28']
count 1347.00000
mean 0.62500
std 0.38502
min 0.00000
25% 0.25000
50% 0.81250
75% 1.00000
max 1.00000
Name: X_28, dtype: float64
desc.loc['X_21']
count 1347.000000
mean 0.499490
std 0.385754
min 0.000000
25% 0.000000
50% 0.562500
75% 0.875000
max 1.000000
Name: X_21, dtype: float64
# f['X_36'] > 0.031 的样本数有1129个
(df['X_36'] > 0.031).sum()
1129
(df['X_36'] <= 0.031).sum()
218
df['label'] = sr
node_2_right_value = sr[df['X_36'] > 0.031].value_counts()
node_2_right_value.sort_index()
0 2
1 131
2 124
3 146
4 126
5 115
6 123
7 138
8 132
9 92
dtype: int64
#第二层右节点的gini系数值0.888
1 - sum((n / node_2_right_value.sum()) ** 2 for n in node_2_right_value)
0.8877966423487084
node_2_left_value = sr[df['X_36'] <= 0.031].value_counts()
node_2_left_value.sort_index()
0 132
2 4
4 5
5 20
6 4
8 2
9 51
dtype: int64
#第二层左节点的gini系数值0.569
1 - sum((n / node_2_left_value.sum()) ** 2 for n in node_2_left_value)
0.5689335914485312
可以得出:
根节点除第一行外,显示的都是样本总体的基尼系数、总样本数和label样本数;每个节点中第一行的特征的大小,决定了下一个节点中的gini系数、sample和value。也就是,第一行特征划分出的样本数、基尼系数、label数都在下一行的2个节点中体现。
每个结点特征<=某个值,并不是四分位数或中位数
验证下其他节点的基尼系数是否大于目前的根节点
假如X[28] <= 0.156作为根节点
#总基尼系数仍然是0.9。分析它决定的左孩子和右孩子的基尼系数
df
| X_0 | X_1 | X_2 | X_3 | X_4 | X_5 | X_6 | X_7 | X_8 | X_9 | ... | X_55 | X_56 | X_57 | X_58 | X_59 | X_60 | X_61 | X_62 | X_63 | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.8125 | 1.0000 | 1.0000 | 0.3125 | 0.0000 | 0.0 | 0.0 | 0.3125 | ... | 0.0 | 0.0 | 0.0 | 0.9375 | 1.0000 | 1.0000 | 0.6250 | 0.0000 | 0.0 | 3 |
| 1 | 0.0 | 0.0 | 0.1250 | 0.6875 | 0.9375 | 0.1250 | 0.0000 | 0.0 | 0.0 | 0.0000 | ... | 0.0 | 0.0 | 0.0 | 0.2500 | 1.0000 | 0.7500 | 0.0625 | 0.0000 | 0.0 | 0 |
| 2 | 0.0 | 0.0 | 0.0000 | 0.0625 | 0.4375 | 0.9375 | 0.6875 | 0.0 | 0.0 | 0.0000 | ... | 0.0 | 0.0 | 0.0 | 0.0000 | 0.0000 | 0.5625 | 0.3750 | 0.0000 | 0.0 | 9 |
| 3 | 0.0 | 0.0 | 0.1250 | 0.9375 | 0.9375 | 1.0000 | 0.6875 | 0.0 | 0.0 | 0.0000 | ... | 0.0 | 0.0 | 0.0 | 0.2500 | 0.9375 | 0.4375 | 0.0000 | 0.0000 | 0.0 | 5 |
| 4 | 0.0 | 0.0 | 0.0000 | 0.0000 | 0.3125 | 0.9375 | 0.5000 | 0.0 | 0.0 | 0.0000 | ... | 0.0 | 0.0 | 0.0 | 0.0000 | 0.0000 | 0.5000 | 0.8750 | 0.0000 | 0.0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1342 | 0.0 | 0.0 | 0.0000 | 0.1250 | 0.8750 | 0.3125 | 0.0000 | 0.0 | 0.0 | 0.0000 | ... | 0.0 | 0.0 | 0.0 | 0.0000 | 0.2500 | 1.0000 | 0.4375 | 0.0000 | 0.0 | 4 |
| 1343 | 0.0 | 0.0 | 0.5000 | 0.8750 | 1.0000 | 1.0000 | 0.1250 | 0.0 | 0.0 | 0.0000 | ... | 0.0 | 0.0 | 0.0 | 0.7500 | 0.4375 | 0.0000 | 0.0000 | 0.0000 | 0.0 | 7 |
| 1344 | 0.0 | 0.0 | 0.1875 | 0.6250 | 0.8750 | 0.1875 | 0.0000 | 0.0 | 0.0 | 0.5000 | ... | 0.0 | 0.0 | 0.0 | 0.1250 | 0.6875 | 1.0000 | 1.0000 | 0.5625 | 0.0 | 8 |
| 1345 | 0.0 | 0.0 | 0.3750 | 0.8750 | 0.6875 | 0.0625 | 0.0000 | 0.0 | 0.0 | 0.0000 | ... | 0.0 | 0.0 | 0.0 | 0.3125 | 0.8750 | 0.9375 | 0.2500 | 0.0000 | 0.0 | 0 |
| 1346 | 0.0 | 0.0 | 0.6875 | 0.6250 | 0.7500 | 0.8750 | 0.6875 | 0.0 | 0.0 | 0.0000 | ... | 0.0 | 0.0 | 0.0 | 0.5625 | 0.8750 | 0.5625 | 0.1250 | 0.0000 | 0.0 | 5 |
1347 rows × 65 columns
(df['X_28'] <= 0.156).sum()
300
#右节点samples
(df['X_28'] > 0.156).sum()
1047
#左节点value
node_2_left_value = df['label'][df['X_28'] <= 0.156].value_counts()
node_2_left_value.sort_index()
0 133
1 1
2 6
3 3
4 47
5 29
6 69
7 8
8 3
9 1
Name: label, dtype: int64
#左孩子的基尼系数
1 - sum((n / node_2_left_value.sum()) ** 2 for n in node_2_left_value)
0.7153333333333334
#右节点value
node_2_right_value = df['label'][df['X_28'] > 0.156].value_counts()
node_2_right_value.sort_index()
0 1
1 130
2 122
3 143
4 84
5 106
6 58
7 130
8 131
9 142
Name: label, dtype: int64
node_2_right_value.sum()
1047
#右孩子的基尼系数
1 - sum((n / node_2_right_value.sum()) ** 2 for n in node_2_right_value)
#选择的标准:是在所有可能的特征A以及它们所有可能的切分点a中,选择基尼指数最小的特征及其对应的切分点作为最优特征与最优切分点。依最优特征与最优切分点,从现结点生成两个子结点,将训练数据集依特征分配到两个子结点中去。
#与X[36] <= 0.031作为根节点相比,X[28] <= 0.156做根节点时,左孩子的基尼系数大于了X[36] <= 0.031的左孩子的基尼系数0.569。二者相比,X[36] <= 0.031更适合做根节点。
0.8831290383494389
特征重要性的计算--未成功推导出
如果每个特征只被使用一次,那么featureimportances应当就是这个Gini importance:
N_t / N * (impurity - N_t_R / N_t * right_impurity - N_t_L / N_t * left_impurity)
其中,N是样本的总数,N_t是当前节点的样本数目,N_t_L是结点左孩子的样本数目,N_t_R是结点右孩子的样本数目。impurity直译为不纯度(基尼指数或信息熵),这里的实现的是基尼指数。
estimator.feature_importances_
array([0. , 0.01087691, 0. , 0. , 0.01000771,
0.03892517, 0.00266332, 0.00442418, 0.00161759, 0.00412525,
0.00512906, 0.0016501 , 0.00425294, 0.01473198, 0.00082505,
0. , 0. , 0.00123758, 0.01155984, 0.02522066,
0.05415936, 0.08281241, 0. , 0. , 0. ,
0.00162305, 0.07636993, 0.04634309, 0.05791402, 0.00544033,
0.01487322, 0. , 0. , 0.05113273, 0.01787237,
0.0051784 , 0.07459433, 0.03054113, 0.00953599, 0. ,
0. , 0.01219702, 0.08933728, 0.0561104 , 0.01733228,
0.00509998, 0.00295643, 0. , 0. , 0. ,
0.00635548, 0.00743226, 0.00404733, 0.01326413, 0.02397377,
0. , 0. , 0.00297018, 0.00570801, 0.01465981,
0.06131626, 0.00234505, 0.0015841 , 0.00767254])
#max_depth最大深度为2时:
# 特征X_36的特征重要性 总样本1397 当前节点样本数1397 总基尼0.9 左孩子样本数218 左孩子基尼数0.569 右孩子1129 右孩子基尼数0.888
1397 / 1397 * (0.9 - 1129 / 1397 * 0.888 - 218 / 1397 * 0.569)
0.09356191839656411
218 / 1397 * (0.569 - 144 / 218 * 0.17 - 74 / 218 * 0.476)
0.04605440229062275
(0.09356191839656411)/ (0.09356191839656411 + 0.04605440229062275 + 0.061335719398711575)
0.4655932746767357
0.04605440229062275 / (0.09356191839656411 + 0.04605440229062275 + 0.061335719398711575)
0.22918106365546953
0.061335719398711575 / (0.09356191839656411 + 0.04605440229062275 + 0.061335719398711575)
0.3052256616677948
去掉前面特征重要程度0的特征重新训练
#重新训练时,每次运行均使用默认参数
feature_clip = np.arange(64)
feature_clip
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50,
51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63])
estimator.feature_importances_
array([0. , 0.01087691, 0. , 0. , 0.01000771,
0.03892517, 0.00266332, 0.00442418, 0.00161759, 0.00412525,
0.00512906, 0.0016501 , 0.00425294, 0.01473198, 0.00082505,
0. , 0. , 0.00123758, 0.01155984, 0.02522066,
0.05415936, 0.08281241, 0. , 0. , 0. ,
0.00162305, 0.07636993, 0.04634309, 0.05791402, 0.00544033,
0.01487322, 0. , 0. , 0.05113273, 0.01787237,
0.0051784 , 0.07459433, 0.03054113, 0.00953599, 0. ,
0. , 0.01219702, 0.08933728, 0.0561104 , 0.01733228,
0.00509998, 0.00295643, 0. , 0. , 0. ,
0.00635548, 0.00743226, 0.00404733, 0.01326413, 0.02397377,
0. , 0. , 0.00297018, 0.00570801, 0.01465981,
0.06131626, 0.00234505, 0.0015841 , 0.00767254])
feature_clip = feature_clip[estimator.feature_importances_ > 0.]
feature_clip
array([ 1, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 17, 18, 19, 20, 21,
25, 26, 27, 28, 29, 30, 33, 34, 35, 36, 37, 38, 41, 42, 43, 44, 45,
46, 50, 51, 52, 53, 54, 57, 58, 59, 60, 61, 62, 63])
x_train[:, feature_clip].shape
(1347, 47)
x_train_ = x_train[:, feature_clip]
y_train_ = y_train
x_test_ = x_test[:, feature_clip]
y_test_ = y_test
estimator2 = DecisionTreeClassifier()
estimator2.fit(x_train,y_train_)
DecisionTreeClassifier()
y_pred_ = estimator2.predict(x_test_)
accuracy_score(y_test_,y_pred_)
0.8488888888888889
#去掉特征前后,模型的准确率提升并不明显,且有时会降低。
#原模型参数max_depth=8,其他参数均为默认值,准确率85.11%时,得到的特征重要程度;再利用该特征重要程度对特征筛选后,再用默认参数重建模型,得到的准确率为87.11%。
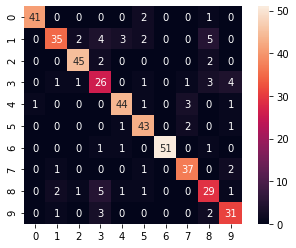
#预测结果混淆矩阵可视化
conf_m = confusion_matrix(y_test_,y_pred_)
conf_m
array([[41, 0, 0, 0, 0, 2, 0, 0, 1, 0],
[ 0, 35, 2, 4, 3, 2, 0, 0, 5, 0],
[ 0, 0, 45, 2, 0, 0, 0, 0, 2, 0],
[ 0, 1, 1, 26, 0, 1, 0, 1, 3, 4],
[ 1, 0, 0, 0, 44, 1, 0, 3, 0, 1],
[ 0, 0, 0, 0, 1, 43, 0, 2, 0, 1],
[ 0, 0, 0, 1, 1, 0, 51, 0, 1, 0],
[ 0, 1, 0, 0, 0, 1, 0, 37, 0, 2],
[ 0, 2, 1, 5, 1, 1, 0, 0, 29, 1],
[ 0, 1, 0, 3, 0, 0, 0, 0, 2, 31]], dtype=int64)
sns.heatmap(conf_m,annot=True,square=True)
plt.show()
调参前后准确率对比:
all defualt 代表全部为默认值;
all feature准确率 代表所有特征训练的准确率最佳结果;
cliped feature准确率 代表步骤9中,去掉特征重要程度0的特征用默认参数重新训练后的准确率
all feature准确率 与 cliped feature准确率 的为同一次运行得到的结果
本次调参只调整了单个参数,未同时调整
参数名称 参数值 all feature准确率 cliped feature准确率
all default 86.67% 84%
max_depth 8 85.11% 87.11%
max_features log2 78.22% 84.89%
max_features sqrt 84.00% 85.56%
min_samples_split 4 84.89% 84.67%
min_samples_split 10 83.78% 84.67%
当使用默认参数进行训练时,去掉特征重要程度0的特征再次训练,并不一定会提升准确率;
当调整了某个参数值时,大概率情况下,去掉特征重要程度0的特征再次训练会对准确率有1~2个百分点的提升。
推荐系统的几个思考
Q:既然内容相似度计算简单,能频繁更新,为什么还需要协同过滤算法呢?
A:
因为内容相似度只是从静态的物理属性进行的统计,并没有利用用户动态的行为;
用户的行为更有反映用户兴趣的偏好,以及当下的流行。
Q:你需要推荐系统么?哪些情况下不需要推荐系统?
A:
不是所有的系统都需要推荐系统。创业早期,用户数少,item并不多的时候,不需要协同过滤进行推荐;此时首要目标是通过各种营销手段扩大用户量。
Q:如果给一个视频打标签,视频中有音乐作为背景音乐,采用了NLP方式对内容自动打标签,可能存在什么问题?
A:
由于音乐如果有歌词的话,当用自然语言处理的方法,给视频打标签时会有噪音出现。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步