玩转Django2.0---Django笔记建站基础十三(第三方功能应用)
第13章 第三方功能应用
在前面的章节中,我们主要讲述Django框架的内置功能以及使用方法,而本章主要讲述Django的第三方功能应用以及使用方法。通过本章的学习,读者能够在网站开发过程中快速开发网站API、生成网站验证码、实现搜索引擎、实现第三方用户注册和分布式任务。
13.1 快速开发网站API
网站API也成为接口,接口其实与网站的URL地址是同一个原理。当用户使用GET或者POST方式访问接口时,接口以JSON或字符串的数据内容返回给用户,这与网站的URL地址返回的数据格式有所不同,网站的URL地址主要返回的是HTML网页信息。
若想快速开发网站API,可以使用Django Rest Framework框架实现。使用框架开发可以规范代码的编写格式,这对企业级开发来说很有必要,毕竟每个开发人员的编程风格存在一定的差异,开发规范化可以方便其它开发人员查看和修改。首先安装Django Rest Framework框架,建议使用pip完成安装,安装指令如下:
pip install djangorestframework
框架按照完成后,以MyDjango项目为例,在项目应用index中创建serializers.py文件,用于定义Django Rest Framework的Serializer类。MyDjango目录结构如下图:
构建项目目录后,接着在setting.py中设置相关配置信息。在settings.py中分别设置数据库连接信息和Django Rest Framework框架的功能配置,配置代码分别如下:
#MyDjango #Django Rest Framework框架配置信息 INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'index', # 添加Django Rest Framework框架 'rest_framework' ] #数据库连接方式配置信息 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'mydjango', 'USER': 'root', 'PASSWORD': '1234', 'HOST': '127.0.0.1', 'PORT': '3306', }, } # Django Rest Framework框架设置信息 # 分页设置 REST_FRAMEWORK = { 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination', # 每页显示多少条数据 'PAGE_SIZE': 2 }
上述代码中,不再对数据库配置做详细的讲述,我们主要分析Django Rest Framework的功能配置。
(一):在INSTALLED_APPS中添加功能配置,这样能使Django在运行过程中自动加载Django Rest Framework的功能。
(二):配置REST_FRAMEWORK属性,属性值以字典的形式表示,用于设置Django Rest Framework的分页功能。
完成settings.py的配置后,下一步是定义项目的数据模型。在index的models.py中分别定义模型Type和Product,代码如下:
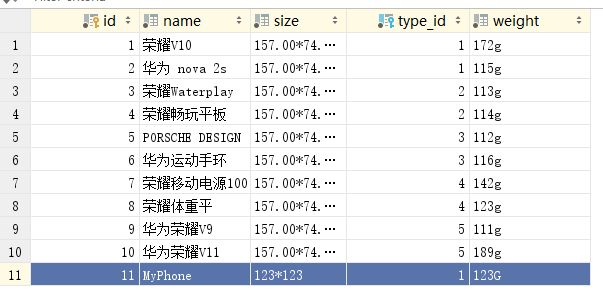
#index/models.py from django.db import models # 产品分类表 class Type(models.Model): id = models.AutoField('序号', primary_key=True) type_name = models.CharField('产品类型', max_length=20) # 设置返回值 def __str__(self): return self.type_name # 产品信息表 class Product(models.Model): id = models.AutoField('序号', primary_key=True) name = models.CharField('名称',max_length=50) weight = models.CharField('重量',max_length=20) size = models.CharField('尺寸',max_length=20) type = models.ForeignKey(Type, on_delete=models.CASCADE,verbose_name='产品类型') # 设置返回值 def __str__(self): return self.name
将定义好的模型执行数据迁移,在项目的数据库中生成相应的数据表,并对数据表index_product和index_type导入数据内容,如下图:
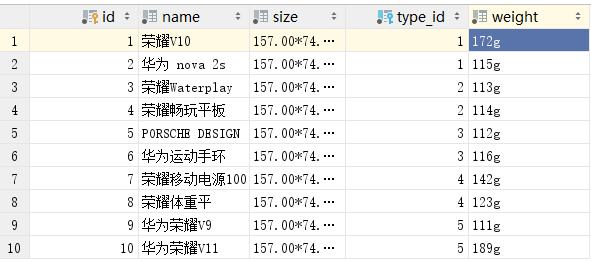
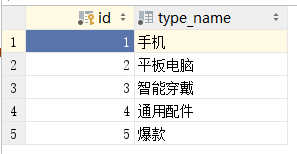
数据表的数据信息
上述基本配置完成后,接下来使用Django Rest Framework快速开发API。首先在项目应用index的serializers.py中分别定义Serializer类和ModelSerializer类,代码如下:


from rest_framework import serializers from .models import Product, Type # 定义Serializer类 # 设置下拉内容 type_id = Type.objects.values('id').all() TYPE_CHOICES = [item['id'] for item in type_id] class MySerializer(serializers.Serializer): id = serializers.IntegerField(read_only=True) name = serializers.CharField(required=True, allow_blank=False, max_length=100) weight = serializers.CharField(required=True, allow_blank=False, max_length=100) size = serializers.CharField(required=True, allow_blank=False, max_length=100) type = serializers.ChoiceField(choices=TYPE_CHOICES, default=1) # 重写create函数,将API数据保存到数据表index_product def create(self, validated_data): return Product.objects.create(**validated_data) # 重写update函数,将API数据更新到数据表index_product def update(self, instance, validated_data): instance.name = validated_data.get('name', instance.name) instance.weight = validated_data.get('weight', instance.weight) instance.size = validated_data.get('size', instance.size) instance.type = validated_data.get('type', instance.type) instance.save() return instance # 定义ModelSerializer类 class ProductSerializer(serializers.ModelSerializer): class Meta: model = Product fields = '__all__' # fields = ('id', 'name', 'weight', 'size', 'type')
从上述代码可以看到,Serializer类ModelSerializer类与Django的表单Form类和ModelForm类非常相似,两者的定义可以相互借鉴。此外,Serializer和ModelSerializer还有其他函数方法,若想进一步了解,在python的安装目录中查看相应的源文件(\Lib\site-packages\rest_framework)。最后,在urls.py和views.py中实现API开发。以定义的ProductSerializer类为例,API功能代码如下:
#index/urls.py from django.urls import path from . import views urlpatterns = [ # 基于类的视图 path('', views.product_class.as_view()), # 基于函数的视图 path('<int:pk>', views.product_def), ] #index/views.py from .models import Product from .serializers import ProductSerializer # APIView 方式生成视图 from rest_framework.views import APIView from rest_framework.response import Response from rest_framework import status from rest_framework.pagination import PageNumberPagination class product_class(APIView): # get 请求 def get(self, request): queryset = Product.objects.all() # 分页查询,需要在settings.py设置REST_FRAMEWORK属性 pg = PageNumberPagination() page_roles = pg.paginate_queryset(queryset=queryset, request=request, view=self) serializer = ProductSerializer(instance=page_roles, many=True) # serializer = ProductSerializer(instance=queryset, many=True) # 全表查询 # 返回对象Response由Django Rest Framework实现 return Response(serializer.data) # post 请求 def post(self, request): # 获取请求数据 serializer = ProductSerializer(data=request.data) # 数据验证 if serializer.is_valid(): # 保存到数据库 serializer.save() # 返回对象Response由Django Rest Framework实现,status是设置响应状态码 return Response(serializer.data, status=status.HTTP_201_CREATED) return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST) # 普通函数方式生成视图 from rest_framework.decorators import api_view @api_view(['GET', 'POST']) def product_def(request, pk): if request.method == 'GET': queryset = Product.objects.filter(id=pk).all() serializer = ProductSerializer(instance=queryset, many=True) # 返回对象Response由Django Rest Framework实现 return Response(serializer.data) elif request.method == 'POST': # 获取请求数据 serializer = ProductSerializer(data=request.data) # 数据验证 if serializer.is_valid(): # 保存到数据库 serializer.save() # 返回对象Response由Django Rest Framework实现,status是设置响应状态码 return Response(serializer.data, status=status.HTTP_201_CREATED) return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
在分析上述代码之前,首先了解一下Django Rest Framework实现API开发的三种方法:
1、基于类的视图。
2、基于函数的视图。
3、重构ViewSets类。
其中,重构ViewSets类的实现过程过于复杂,在开发过程中,如无必要,一般不建议采用这种实现方式。若读者对此方法感兴趣,可以参考官方文档。
在views.py中定义的product_class类和函数product_def分别基于类的视图和基于函数的视图,两者的使用说明如下:
1、基于类的视图:开发者主要通过自定义类来实现视图,自定义类可以选择继承父类APIView、mixins或generics。APIView类适用于Serializer类和ModelSerializer类,mixins类和generics类只适用于ModelSerializer类。
上述代码的product_class类主要继承APIView类,并且定义GET请求和POST请求的处理函数。GET函数主要将模型Product的数据进行分页显示,POST函数将用户发送的数据进行验证并入库处理。启动MyDjango项目,在浏览器上输入192.168.10.100:800/?page=1,运行结果如下:
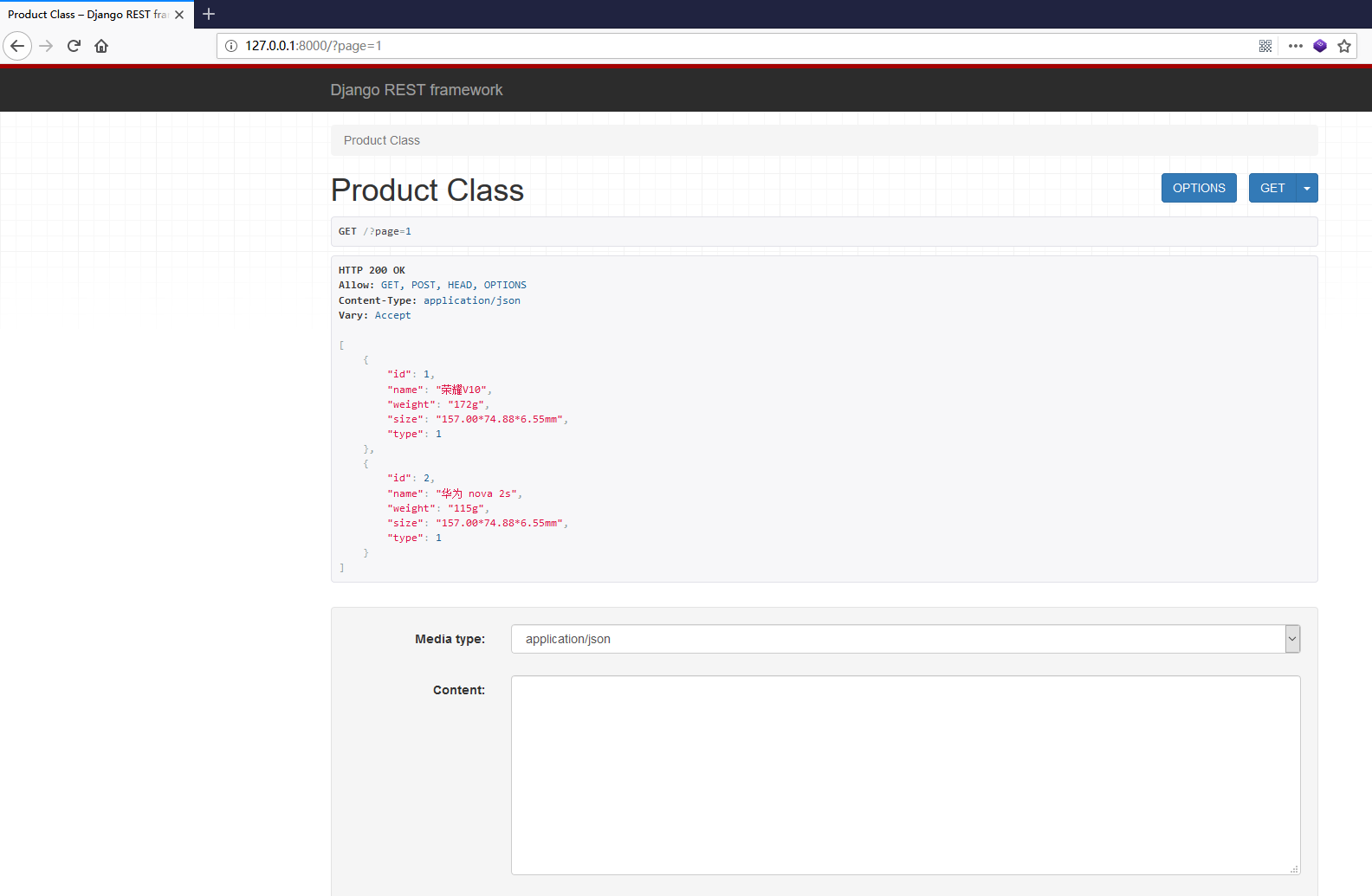
GET请求的响应内容
为了进一步验证POST函数是否正确,我们在项目的目录外创建test.py文件,文件代码如下:
import requests url = 'http://127.0.0.1:8000' data = { 'name': 'MyPhone', 'weight': '123G', 'size': '123*123', 'type': 1 } r = requests.post(url, data=data) print(r.text)
运行test.py文件并查看数据表index_product,可以发现数据表index_product新增一条数据信息,如下图:
2、基于函数的视图:使用函数的方式实现API开发是三者中最为简单的方式,从函数product_def的定义来看,该函数与Django定义的视图函数并无太大区别。唯一的区别在于函数product_def需要使用装饰器api_view并且数据是由Django Rest Framework定义的对象进行返回的。
上述代码中,若用户发送GET请求,函数参数pk作为模型Product的查询条件,查询结果交给ProductSerializer类实例化对象serializer进行数据格式转换,最后由Django Rest Framework的Response对象返回给用户;若用户发送POST请求,函数将用户发送的数据进行验证并入库处理。在浏览器上输入http://127.0.0.1:8000/2,运行结果如图:

GET请求的响应内容
若想验证POST请求的处理方式,只需将上述test.py的url变量改为http://127.0.0.1:8000/1,然后运行test.py文件并查看数据表index_product是否新增一条数据。
Django Rest Framework框架的使用方式总结如下:
1、在settings.py中添加Django Rest Framework功能,并对功能进行分页配置。
2、在App中新建serializers.py文件并定义Serializer类或ModelSerializer类。
3、在urls.py中定义路由地址。
4、在views.py中定义视图函数,三种方式定义分别为:基于类的视图、基于函数的视图和重构ViewSets类。
13.2 验证码的使用
现在很多网站都采用验证码功能,这是反爬虫常用的策略之一。目前常用的验证码类型如下:
1、字符验证码:在图片上随机产生数字、英文字母或汉字,一般有4为或者6位验证码字符。
2、图片验证码:图片验证码采用字符验证码的技术,不再是一随机的字符,而是让用户识别图片,比如12306的验证码。
3、GIF动画验证码:由多张图片组合而成的动态验证码,使得识别器不容易辨识哪一张图片是真正的验证码图片。
4、极验验证码:在2012年推出的新型验证码,采用行为式验证技术,通过拖动滑块完成拼图的形式实现验证,是目前比较有创意的验证码,安全性具有新的突破。
5、手机验证码:通过短信的形式发送到用户手机上面的验证码,一般为6为的数字。
6、语音验证码:也属于手机端验证的一种方式。
7、视频验证码:视频验证码是验证码中的新秀,在视频验证码中,将随机数字、字母和中文组合而成的验证码动态嵌入MP4\FLV等格式的视频中,增大破解难度。
如果想在Django中实现验证码功能,可以使用PIL模块生成图片验证码,但不建议使用这种方式实现,除此之外,还可以通过第三方应用Django Simple Captcha来实现,验证码的生成过程由该应用自动执行,开发者只需考虑如何应用到Django项目中。Django Simple Captcha使用pip按照,安装指令如下:
pip install django-simple-captcha
按照成功后,下一步讲述如何在Django中使用Django Simple Captcha生成网站验证码。以MyDjango项目为例,在项目中应用user创建templates文件夹和forms.py文件,最后在templates文件夹中放置user.html文件,目录结构如图所示:
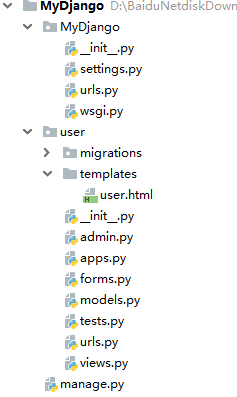
MyDjango目录结构
项目目录结构搭建后,接下来在settings.py中配置项目。除了项目的基本配置之外,如何要配置TEMPLATES和DATABASES,还可以对验证码的生成进行配置,如设置验证码的内容、图片噪点和图片大小等。具体的配置信息如下:
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'user', # 添加验证码功能 'captcha' ] # django_simple_captcha 验证码基本配置 # 设置验证码的显示顺序,一个验证码识别包含文本输入框、隐藏域和验证码图片,该配置是设置三者的显示顺序 CAPTCHA_OUTPUT_FORMAT = '%(text_field)s %(hidden_field)s %(image)s' # 设置图片噪点 CAPTCHA_NOISE_FUNCTIONS = ( # 设置样式 'captcha.helpers.noise_null', # 设置干扰线 'captcha.helpers.noise_arcs', # 设置干扰点 'captcha.helpers.noise_dots', ) # 图片大小 CAPTCHA_IMAGE_SIZE = (100, 25) # 设置图片背景颜色 CAPTCHA_BACKGROUND_COLOR = '#ffffff' # 图片中的文字为随机英文字母,如 mdsh # CAPTCHA_CHALLENGE_FUNCT = 'captcha.helpers.random_char_challenge' # 图片中的文字为英文单词 # CAPTCHA_CHALLENGE_FUNCT = 'captcha.helpers.word_challenge' # 图片中的文字为数字表达式,如1+2=</span> CAPTCHA_CHALLENGE_FUNCT = 'captcha.helpers.math_challenge' # 设置字符个数 CAPTCHA_LENGTH = 4 # 设置超时(minutes) CAPTCHA_TIMEOUT = 1
首先在INSTALLED_APPS中添加captcha验证码功能,项目运行时会字段价值captcha功能。然后对captcha功能进行相关的配置,主要的配置有:验证码的显示顺序、图片噪点、图片大小、背景颜色和验证码内容,具体的配置以及配置说明可以查看源代码及注释。
完成上述配置后,下一步是执行数据迁移。在功能配置后必须执行数据迁移,因为验证码需要依赖数据表才能得以实现。通过python manage.py migrate指令完成数据迁移,然后查看项目所生成的数据表,发现新增数据表captcha_captchastore,如下图:

项目的数据表
接下来将验证码功能生成在网页上并实现验证码功能。下面以实现带验证码的用户登录为例进行介绍,根据整个用户登录过程,我们将其划分为多个不同的功能。
1、用户登录界面:由表单生成,表单类在项目应用user的forms.py中定义。
2、登录验证:触发POST请求,用户信息以及验证功能由Django内置的Auth认证系统实现。
3、验证码动态刷新:由Ajax方式向captcha功能应用发送GET请求完成动态刷新。
4、验证码动态验证:由Ajax方向向Django发送GET请求完成验证码验证。
根据上述功能进行分析,整个用户登录过程由MyDjango的urls.py和项目应用user的forms.py、urls.py、views.py、和user.html共同实现。首先在项目应用user的forms.py中定义用户登录表单类,代码如下:
# 定义用户登录表单类 from django import forms from captcha.fields import CaptchaField class CaptchaTestForm(forms.Form): username = forms.CharField(label='用户名') password = forms.CharField(label='密码', widget=forms.PasswordInput) captcha = CaptchaField()
从表单类CaptchaTestForm可以看到,字段captcha是由Django Simple Captcha定义的CaptchaField对象,该对象在生成HTML网页信息时,将自动生成文本输入框、隐藏域和验证码图片。然后表单类在views.py中进行实例化并展示在网页上,在MyDjango的urls.py和项目应用user的urls.py、views.py和user.html中分别编写以下代码:
#MyDjango的urls.py from django.contrib import admin from django.urls import path,include urlpatterns = [ path('admin/', admin.site.urls), path('', include('user.urls')), # 导入插件URL地址信息,用于生成图片地址 path('captcha/', include('captcha.urls')) ] #user/urls.py from django.urls import path from . import views urlpatterns = [ # 用户登录界面 path('', views.loginView, name='login'), # 验证码验证API接口 path('ajax_val', views.ajax_val, name='ajax_val') ] #user/views.py from django.shortcuts import render from django.contrib.auth.models import User from django.contrib.auth import login, authenticate from .forms import CaptchaTestForm # 用户登录 def loginView(request): if request.method == 'POST': form = CaptchaTestForm(request.POST) # 验证表单数据 if form.is_valid(): username = form.cleaned_data['username'] password = form.cleaned_data['password'] if User.objects.filter(username=username): user = authenticate(username=username, password=password) if user: if user.is_active: login(request, user) tips = '登录成功' else: tips = '账号密码错误,请重新输入' else: tips = '用户不存在,请注册' else: form = CaptchaTestForm() return render(request, 'user.html', locals()) # ajax接口,实现动态验证验证码 from django.http import JsonResponse from captcha.models import CaptchaStore def ajax_val(request): if request.is_ajax(): # 用户输入的验证码结果 response = request.GET['response'] # 隐藏域的value值 hashkey = request.GET['hashkey'] cs = CaptchaStore.objects.filter(response=response, hashkey=hashkey) # 若存在cs,则验证成功,否则验证失败 if cs: json_data = {'status':1} else: json_data = {'status':0} return JsonResponse(json_data) else: json_data = {'status':0} return JsonResponse(json_data) #项目应用user的user.html <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <title>Django</title> <script src="http://apps.bdimg.com/libs/jquery/2.1.1/jquery.min.js"></script> <link rel="stylesheet" href="https://unpkg.com/mobi.css/dist/mobi.min.css"> </head> <body> <div class="flex-center"> <div class="container"> <div class="flex-center"> <div class="unit-1-2 unit-1-on-mobile"> <h1>MyDjango Verification</h1> {% if tips %} <div>{{ tips }}</div> {% endif %} <form class="form" action="" method="post"> {% csrf_token %} <div>用户名:{{ form.username }}</div> <div>密 码:{{ form.password }}</div> <div>验证码:{{ form.captcha }}</div> <button type="submit" class="btn btn-primary btn-block">确定</button> </form> </div> </div> </div> </div> <script> $(function(){ {# ajax 刷新验证码 #} $('.captcha').click(function(){ console.log('click'); $.getJSON("/captcha/refresh/", function(result){ $('.captcha').attr('src', result['image_url']); $('#id_captcha_0').val(result['key']) });}); {# ajax动态验证验证码 #} $('#id_captcha_1').blur(function(){ // #id_captcha_1为输入框的id,当该输入框失去焦点就会触发函数 json_data={ // 获取输入框和隐藏字段id_captcha_0的数值 'response':$('#id_captcha_1').val(), 'hashkey':$('#id_captcha_0').val() } $.getJSON('/ajax_val', json_data, function(data){ $('#captcha_status').remove() //status返回1为验证码正确, status返回0为验证码错误, 在输入框的后面写入提示信息 if(data['status']){ $('#id_captcha_1').after('<span id="captcha_status">*验证码正确</span>') }else{ $('#id_captcha_1').after('<span id="captcha_status">*验证码错误</span>') } }); }); }) </script> </body> </html>
上述代码用于实现整个用户登录过程,代码中具体实现的功能代码说明如下。
1、MyDjango的urls.py:引入Django Simple Captcha的urls.py和项目应用user的urls.py。前者主要为验证码图片提供URL地址以及为Ajax动态刷新验证码提供API接口,后者用于设置用户登录界面的URL以及为Ajax动态校验证码提供API接口。
2、项目应用user的urls.py:设置用户登录界面的URL地址和Ajax动态验证的API接口。
3、views.py:函数loginView使用Django内置的Auth实现登录功能;函数ajax_val用于获取Ajax的GET请求参数,然后与Django Simple Captcha定义的模型进行匹配,若匹配的上,则验证成功,否则验证失败。
4、user.html:生成用户表单以及实现Ajax的动态刷新和动态验证功能。Ajax动态刷新是向Django Simple Captcha的urls.py所定义的URL发送GET请求,而Ajax动态验证是向项目应用user的urls.py所定义的URL发送GET请求。
为了更好地验证上述所实现的功能,首先在项目内置User的中创建用户root并启动MyDjango项目,然后执行以下验证步骤:
1、单击验证码图片,查看验证码图片是否发生替换。
2、单击验证码输入框,分别输入正确和错误的验证码,然后单击网页的其他地方,使验证码输入框失去焦点,从而触发Ajax请求,最后查看验证码验证是否正确。
3、输入用户的账号、密码和验证码,查看是否登录成功。
13.3 站内搜索引擎
站内搜索是网站常用的功能之一,其作用是方便用户快速查找站内数据以便查阅。对于一些初学者来说,站内搜索可以使用SQL搜索查询实现,从某个角度来说,这种实现方式只是适用于个人小型网站,对于企业级的开发,站内搜索是由搜索引擎实现的。
Django Haystack是一个专门提供搜索功能的Django第三方应用,它支持Solr、Elasticsearch、Whoosh和Xapian等多种搜索引擎,配合著名的中文自然语言处理库jieba分词可以实现全文搜索系统。
本节在Whoosh搜索引擎和jieba分词的基础上使用Django Haystack实现网站搜索引擎。因此,在安装Django Haystack的过程中,需要自行安装Whoosh搜索引擎和jieba分词,具体的pip安装指令如下:
pip install django-haystack
pip install whoosh
pip install jieba
完成上述模块的安装后,接着在MyDjango项目中配置相关的应用功能。在项目应用index中分别添加文件product_text.txt、search.html、search_indexes.py、whoosh_cn_backend.py和文件夹static,各个文件说明如下:
1、product_text.txt:搜索引擎的索引模板文件,模板文件命名以及路径有固定的设置格式,如/templates/search/indexes/项目应用的名称/模型(小写)_text.txt。
2、search.html:搜索页面的模板文件,用于生成网站的搜索页面。
3、search_indexes.py:定义索引类,该文件与索引模板文件是两个不同的概念。
4、whoosh_cn_backend.py:这是自定义的Whoosh搜索引擎文件。由于Whoosh不支持中文搜索,因此需要重新定义Whoosh搜索引擎文件,将jieba分词器添加到搜索引擎中,使得它具有中文搜索功能。
5、static:存放网页样式common.css和search.css
根据上述目录搭建,最后MyDjango的目录结构如下图:
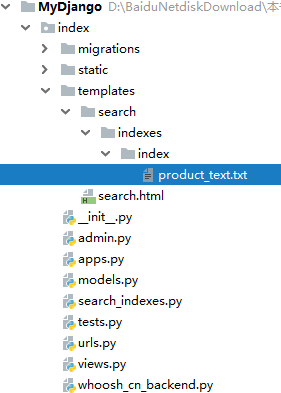
MyDjango目录大家完成后,下一步是在settings.py中配置第三方应用Django Haystack。这里的配置主要在INSTALLED_APPS中引入Django Haystack以及设置该应用的功能配置,具体的配置信息如下:
#settings.py INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'index', # 配置haystack 'haystack', ] # 配置haystack HAYSTACK_CONNECTIONS = { 'default': { # 设置搜索引擎,文件是index的whoosh_cn_backend.py 'ENGINE': 'index.whoosh_cn_backend.WhooshEngine', 'PATH': os.path.join(BASE_DIR, 'whoosh_index'), 'INCLUDE_SPELLING': True, }, } # 设置每页显示的数据量 HAYSTACK_SEARCH_RESULTS_PER_PAGE = 4 # 当数据库改变时,会自动更新索引,非常方便 HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
观察上述配置可以发现,配置属性HAYSTACK_CONNECTIONS的ENGINE指向项目应用index的whoosh_cn_backend.py文件。该文件是自定义的Whoosh搜索引擎文件,这是根据Whoosh源文件进行修改生成的,在Python的安装目录中可以找到Whoosh源文件whoosh_backend.py,如下图:

打开whoosh_backend.py文件并将内容复制到whoosh_cn_backend.py,然后将复制后的内容进行修改和保存,这样就可以生成自定义的Whoosh搜索引擎文件。具体修改的内容如下:
#引入jieba分词器的模块 from jieba.analyse import ChineseAnalyzer #schema_fields[field_class.index_fieldname] = TEXT(stored=True, analyzer=StemmingAnalyzer(), field_boost=field_class.boost, sortable=True) #所在位置并修改整行替代,带入内容如下: #schema_fields[field_class.index_fieldname] = TEXT(stored=True, analyzer=ChineseAnalyzer(),field_boost=field_class.boost,sortable=True)
完成settings.py和whoosh_cn_backend.py的配置后,接下来实现搜索引擎的开发。在功能开发之前,需要在项目应用index的models.py中重新定义数据模型Product,模型Product作为搜索引擎的搜索对象。模型Product的定义代码如下:
from django.db import models # 创建产品信息表 class Product(models.Model): id = models.AutoField('序号', primary_key=True) name = models.CharField('名称',max_length=50) weight = models.CharField('重量',max_length=20) describe = models.CharField('描述',max_length=500) # 设置返回值 def __str__(self): return self.name
将定义好的模型Product执行数据迁移,在数据库中生成数据表index_product,并对数据表index_product导入数据内容,如下图:

数据表index_product的数据信息
现在开始讲述搜索引擎的开发过程,首先创建搜索引擎的索引。创建索引主要能使搜索引擎快速找到符合条件的数据,索引就像是书本的目录,可以为读者快读地查找内容,在这里也是同样的道理。当数据量非常大的时候,要从这些数据中找出所有满足搜索条件的数据是不太可能的,并且会给服务器带来极大的负担,所以我们需要为指定的数据添加一个索引。
索引是在search_indexes.py中定义的,然后由指令指令创建过程。我们以模型Product为例,在search_indexes.py中定义该模型的索引,代码如下:
from haystack import indexes from .models import Product # 类名必须为模型名+Index,比如模型Product,则索引类为ProductIndex class ProductIndex(indexes.SearchIndex, indexes.Indexable): text = indexes.CharField(document=True, use_template=True) # 设置模型 def get_model(self): return Product # 设置查询范围 def index_queryset(self, using=None): return self.get_model().objects.all()
从上述代码来看,在定义模型的索引类时,类定义要求以及定义说明如下:
1、定义索引类的文件名必须为search_indexes.py,不得修改文件名,否则程序无法创建索引。
2、索引类的类名格式必须为"模型+Index",每个模型对应一个索引类,如模型Product的索引类为ProductIndex。
3、字段text设置document=True,代表搜索引擎将使用此字段的内容作为索引进行检索。
4、use_template=True是使用索引模板建立索引文件,可以理解为在索引中设置模型的查询字段,如设置Product的得desctibe字段,这样可以通过describe的内容检索Product的数据。
5、类函数get_model是将该索引类与模型Product进行绑定,类函数index_queryset用于设置索引的查询范围。
从上述分析可以知道,use_template=True是使用索引模板建立索引文件,索引模板的路径是固定的,其格式为/templates/search/indexes/项目应用的名称/模型(小写)_text.txt。以ProductIndex为例,其索引模板路径为templates/search/indexes/index/product_text.txt。我们在索引模板中设置模型Product的name和describe字段作为索引的检索字段,可以在索引模板中添加以下代码:
#templates/search/indexes/index/product_text.txt {{ object.name }} {{ object.describe }}
上述设置是对Product.name和Product.describe两个字段建立索引,当搜索引擎进行检索时,系统会根据搜索条件对着两个字段进行全文检索匹配,然后将匹配结果排序后并返回。
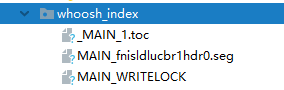
现在只定义了搜索引擎的索引类和索引模板,我们可以根据这两者创建索引文件,通过指令python manage.py rebuild_index即可完成索引文件的创建,在MyDjango中可以看到whoosh_index文件夹,该文件夹中含有索引文件,如下图:
最后在Django中实现搜索功能,实现模型Product的全文检索。在urls.py、views.py和search.html中分别定义搜索引擎的URL地址、URL的视图以及HTML模板,具体的代码及说明如下:
#index/urls.py from django.urls import path from . import views urlpatterns = [ # 搜索引擎 path('search.html', views.MySearchView(), name='haystack'), ] #index/views.py from django.shortcuts import render from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger from django.conf import settings from .models import * from haystack.views import SearchView # 视图以通用视图实现 class MySearchView(SearchView): # 模版文件 template = 'search.html' # 重写响应方式,如果请求参数q为空,返回模型Product的全部数据,否则根据参数q搜索相关数据 def create_response(self): if not self.request.GET.get('q', ''): show_all = True product = Product.objects.all() paginator = Paginator(product, settings.HAYSTACK_SEARCH_RESULTS_PER_PAGE) try: page = paginator.page(int(self.request.GET.get('page', 1))) except PageNotAnInteger: # 如果参数page的数据类型不是整型,则返回第一页数据 page = paginator.page(1) except EmptyPage: # 用户访问的页数大于实际页数,则返回最后一页的数据 page = paginator.page(paginator.num_pages) return render(self.request, self.template, locals()) else: show_all = False qs = super(MySearchView, self).create_response() return qs #index/search.html <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>搜索引擎</title> {# 导入CSS样式文件 #} {% load staticfiles %} <link type="text/css" rel="stylesheet" href="{% static "common.css" %}"> <link type="text/css" rel="stylesheet" href="{% static "search.css" %}"> </head> <body> <div class="header"> <div class="search-box"> <form id="searchForm" action="" method="get"> <div class="search-keyword"> {# 搜索输入文本框必须命名为q #} <input id="q" name="q" type="text" class="keyword" maxlength="120"/> </div> <input id="subSerch" type="submit" class="search-button" value="搜 索" /> </form> <div id="suggest" class="search-suggest"></div> </div> </div><!--end header--> <div class="wrapper clearfix" id="wrapper"> <div class="mod_songlist"> <ul class="songlist__header"> <li class="songlist__header_name">产品名称</li> <li class="songlist__header_author">重量</li> <li class="songlist__header_album">描述</li> </ul> <ul class="songlist__list"> {# 列出当前分页所对应的数据内容 #} {% if show_all %} {% for item in page.object_list %} <li class="js_songlist__child" mid="1425301" ix="6"> <div class="songlist__item"> <div class="songlist__songname">{{ item.name }}</div> <div class="songlist__artist">{{item.weight}}</div> <div class="songlist__album">{{ item.describe }}</div> </div> </li> {% endfor %} {% else %} {# 导入自带高亮功能 #} {% load highlight %} {% for item in page.object_list %} <li class="js_songlist__child" mid="1425301" ix="6"> <div class="songlist__item"> <div class="songlist__songname">{% highlight item.object.name with query %}</div> <div class="songlist__artist">{{item.object.weight}}</div> <div class="songlist__album">{% highlight item.object.describe with query %}</div> </div> </li> {% endfor %} {% endif %} </ul> {# 分页导航 #} <div class="page-box"> <div class="pagebar" id="pageBar"> {# 上一页的URL地址 #} {% if page.has_previous %} {% if query %} <a href="{% url 'haystack'%}?q={{ query }}&page={{ page.previous_page_number }}" class="prev">上一页</a> {% else %} <a href="{% url 'haystack'%}?page={{ page.previous_page_number }}" class="prev">上一页</a> {% endif %} {% endif %} {# 列出所有的URL地址 #} {% for num in page.paginator.page_range %} {% if num == page.number %} <span class="sel">{{ page.number }}</span> {% else %} {% if query %} <a href="{% url 'haystack' %}?q={{ query }}&page={{ num }}" target="_self">{{num}}</a> {% else %} <a href="{% url 'haystack' %}?page={{ num }}" target="_self">{{num}}</a> {% endif %} {% endif %} {% endfor %} {# 下一页的URL地址 #} {% if page.has_next %} {% if query %} <a href="{% url 'haystack' %}?q={{ query }}&page={{ page.next_page_number }}" class="next">下一页</a> {% else %} <a href="{% url 'haystack' %}?page={{ page.next_page_number }}" class="next">下一页</a> {% endif %} {% endif %} </div> </div> </div><!--end mod_songlist--> </div><!--end wrapper--> </body> </html>
上述代码中,视图是通过继承SearchView类实现的,父类SearchView是由Django Haystack封装的视图类。如果想了解DjangoHaystack封装的视图类,可以在Python按照目录查看具体的源代码,文件路径为\Lib\site-packages\haystack\views.py,也可以查看Django Haystack官方文档。
在模板文件search.html中,我们将搜索结果中的搜索条件进行高亮显示。模板标签highlight是Django Haystack自定义的标签,标签的使用方法较为简单,此处不做详细介绍,具体使用方法可以参考官方文档http://django-haystack.readthedocs.io/en/master/templatetags.html。
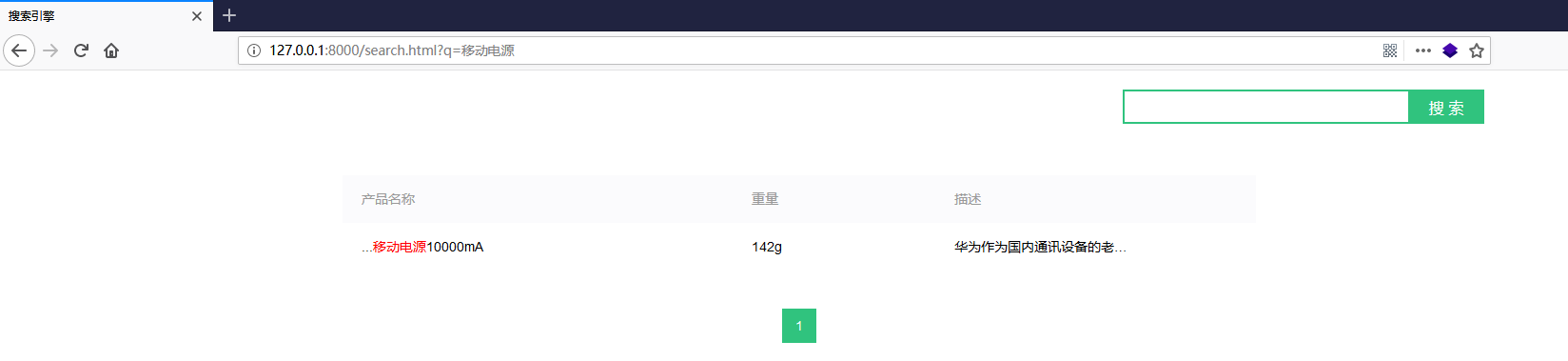
启动MyDjango项目,在浏览器上输入http://127.0.0.1:8000/search.html,并在上方输入"移动电源"进行搜索,搜索结果如下图:
13.4 第三方用户注册
用户注册与登录以及成为网站必备的功能之一,Django内置的Auth认证系统可以帮助开发人员快速实现用户管理功能。但很多网站为了加强社交功能,在用户管理功能上增设了第三方用户注册与登录功能,这是通过OAuth2.0认证与授权来实现的。OAuth2.0的具体实现过程相对繁琐,我们通过流程图来大致了解OAuth2.0的实现过程,如下图:

OAuth2.0的实现过程
分析实现过程,我们可以简单理解OAuth2.0认证与授权是两个网站的服务器后台进行通信交流。根据实现原理,可以使用requests库或urllib标准库实现OAuth2.0认证与授权,从而实现第三方用户的注册与登录功能。如果网站涉及多个第三方网站,这种方式实现不太可取的,而且发现代码会出现重复使用的情况。因此,我们可以使用Django第三方功能应用Django Social Auth,它为我们提供了各大网站平台的认证与授权功能。
Django Social Auth是在Python Social Auth的基础上进行封装而成的,除了按照Django Social Auth之外,还需要安装Python Social Auth。通过pip方式进行安装,按照指令如下:
pip install python-social-auth
pip install social-auth-app-django
功能模块安装成功后,以MyDjango项目为例,讲述如何在Django中使用Django Social Auth实现第三方用户注册功能,MyDjango的目录结构如下图:
MyDjango的目录结构较为简单,因为Django Social Auth的本质是一个Django的项目应用,可以在Python的安装目录下找到Django Social Auth所有的源代码文件,发现它具有urls.py、views.py和models.py等文件,这与Django App(项目应用)的文件架构是一样的,如下图:
Django Social Auth的源代码文件
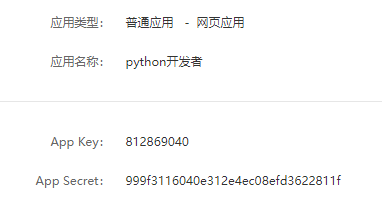
了解Django Social Auth的本质后,在后续的使用中可以更加清晰地知道他的实现过程。本节以微博帐号实现用户的注册功能。首先在浏览器中打开微博开放平台(http://open.weibo.com/),登录微博并新建应用,然后获取应用的App Key和App Secret,如图:
获取App Key和App Secret
下一步是设置应用的OAuth2.0授权设置,单击应用中的高级信息,编辑OAuth2.0授权设置的授权回调页,如下图:

OAuth2.0授权设置
授权回调页的URL地址必须为/complete/weibo/,因为授权回调页是由Django Social Auth进行处理的,而它已经为授权回调页设置相应的地址路径。可以打开Django Social Auth的源代码文件urls.py查看具体的设置内容,具体如下:
"""URLs module""" from django.conf import settings from django.conf.urls import url from social_core.utils import setting_name from . import views extra = getattr(settings, setting_name('TRAILING_SLASH'), True) and '/' or '' app_name = 'social' urlpatterns = [ # authentication / association url(r'^login/(?P<backend>[^/]+){0}$'.format(extra), views.auth, name='begin'), url(r'^complete/(?P<backend>[^/]+){0}$'.format(extra), views.complete, name='complete'), # disconnection url(r'^disconnect/(?P<backend>[^/]+){0}$'.format(extra), views.disconnect, name='disconnect'), url(r'^disconnect/(?P<backend>[^/]+)/(?P<association_id>\d+){0}$' .format(extra), views.disconnect, name='disconnect_individual'), ]
完成上述配置后,接着在settings.py中设置Django Social Auth的配置信息,主要在INSTALLED_APPS和TEMPLATES中引入功能模块以及设置相关的功能配置,配置信息如下:
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'user', # 添加第三方应用 'social_django' ] # 设置第三方的OAuth2.0,所有第三方的OAuth2.0可以查看源码目录:\Lib\site-packages\social\backends AUTHENTICATION_BACKENDS = ( 'social.backends.weibo.WeiboOAuth2', # 微博的功能 'social.backends.qq.QQOAuth2', # QQ的功能 'social.backends.weixin.WeixinOAuth2', # 微信的功能 'django.contrib.auth.backends.ModelBackend',) # 注册成功后跳转页面 SOCIAL_AUTH_LOGIN_REDIRECT_URL = 'success' # 开放平台应用的 APPID 和 SECRET SOCIAL_AUTH_WEIBO_KEY = '812869040' SOCIAL_AUTH_WEIBO_SECRET = '999f3116040e312e4ec08efd3622811f' SOCIAL_AUTH_QQ_KEY = 'APPID' SOCIAL_AUTH_QQ_SECRET = 'SECRET' SOCIAL_AUTH_WEIXIN_KEY = 'APPID' SOCIAL_AUTH_WEIXIN_SECRET = 'SECRET' TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [os.path.join(BASE_DIR, 'user/templates'),], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', #需要添加的配置信息 'social_django.context_processors.backends', 'social_django.context_processors.login_redirect', ], }, }, ]
因为Django Social Auth定义了相关的数据模型,完成settings.py的配置后,需要使用python manage.py migrate执行数据迁移,生成相关的数据表,最后在MyDjango项目中实现第三方用户注册功能,功能主要由MyDjango的urls.py、项目应用user的urls.py、views.py和user.html共同实现,分别编写相关的功能代码,代码如下:
#MyDjango/urls.py from django.contrib import admin from django.urls import path, include from django.conf.urls import url urlpatterns = [ path('admin/', admin.site.urls), path('', include('user.urls')), # 导入social_django的URL,源码地址\Lib\site-packages\social_django\urls.py url('', include('social_django.urls', namespace='social')), ] #user/urls.py from django.urls import path from . import views urlpatterns = [ # 用户注册界面的URL地址,显示微博登录链接。 path('', views.loginView, name='login'), # 注册后回调的页面,成功注册后跳转回站内地址。 path('success', views.success, name='success') ] #user/views.py from django.shortcuts import render # 用户注册界面 def loginView(request): title = '用户注册' return render(request, 'user.html', locals()) # 注册后回调的页面 from django.http import HttpResponse def success(request): return HttpResponse('注册成功') #user/user.html <!DOCTYPE html> <html lang="zh-cn"> <head> <meta charset="utf-8"> <title>{{ title }}</title> <link rel="stylesheet" href="https://unpkg.com/mobi.css/dist/mobi.min.css"> </head> <body> <div class="flex-center"> <div class="container"> <div class="flex-center"> <div class="unit-1-2 unit-1-on-mobile"> <h1>MyDjango Social Auth</h1> <div> {# {% url "social:begin" "weibo" %}来自Lib\site-packages\social_django\urls.py #} <a class="btn btn-primary btn-block" href="{% url "social:begin" "weibo" %}">微博注册</a> </div> </div> </div> </div> </div> </body> </html>
在上述代码中,我们一共设置了三个URL路由地址,分别为social、login和success,三者的作用说明如下:
1、social:导入Django Social Auth的URL,将其添加到MyDjango项目中,主要生成授权页面和处理授权回调请求。
2、login:生成网站的用户注册页面,为授权页面提供链接入口,方便用户进入授权页面。
3、success:授权回调处理完成后,程序自动跳转的页面,由settings.py的配置属性SOCIAL_AUTH_LOGIN_REDIRECT_URL设置。
启动MyDjango项目,在浏览器中输入http://127.0.0.1:8000/并单击微博"注册"按钮,网页会出现微博的授权认证页面,然后单击"授权"按钮,程序会字段跳转到success的URL所生成的页面,如下图:

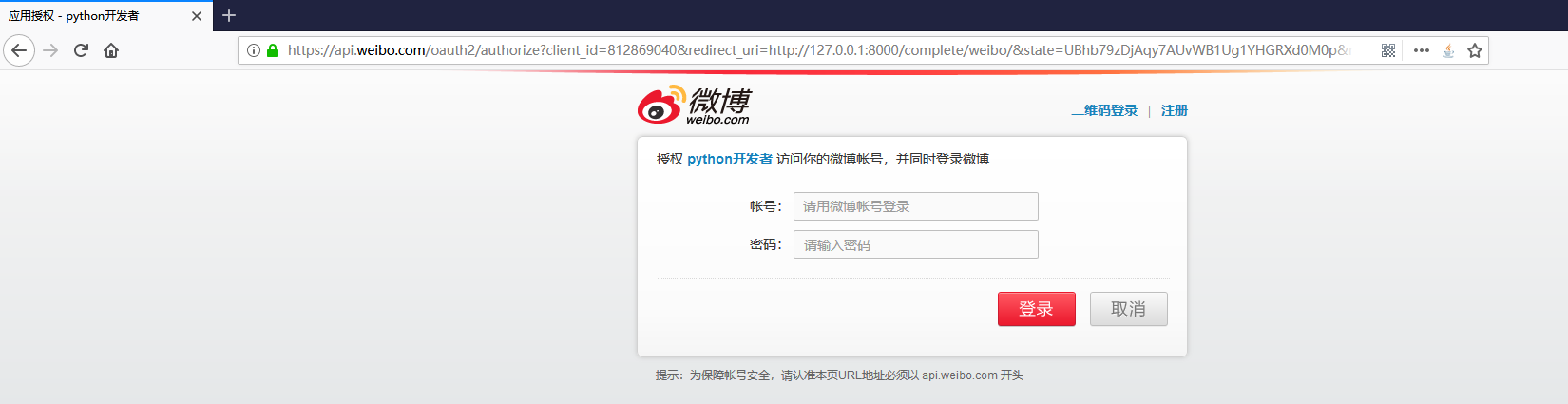
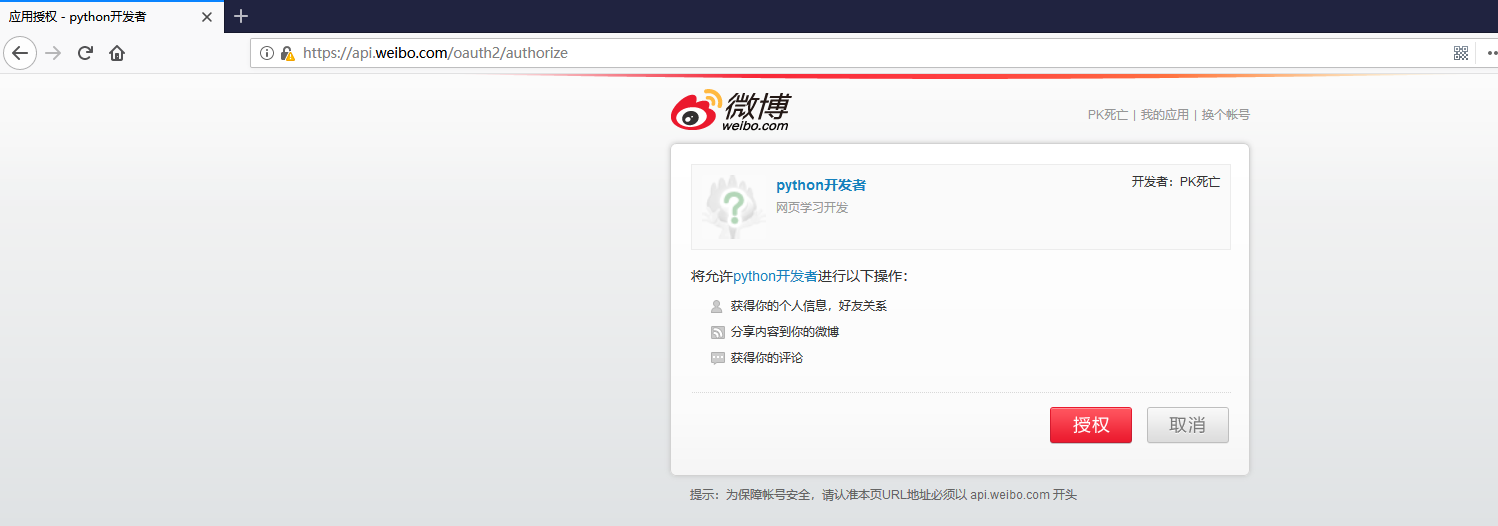

微博授权认证过程
完成微博的认证与授权后,我们在数据库中分别查看数据表social_auth_usersocialauth和auth_user。可以发现两个数据表都创建了用户信息,前者是微博认证授权后的微博用户信息,前者是微博认证授权后的微博用户信息,后者是根据前者的用户信息在网站中创建的新用户,如下图:


数据表social_auth_usersocialauth和auth_user
上述例子主要实现了第三方用户注册网站帐号的功能。除此之外,还可以实现第三方用户登录网站、第三方用户失联已有的网站帐号以及Admin后台管理设置等功能。由于篇幅有限就不再详细讲述,有兴趣的可以参考官方文档和查阅相关资料。
13.5 分布式任务与定时任务
网站的并发编程主要处理网站的业务流程,根据网站请求到响应的过程分析,Django处理用户请求主要在视图中执行,视图主要是一个函数,而且是单线程执行的函数。在视图函数处理用户请求时,如果遇到繁琐的数据读写或高密度计算,往往会造成响应时间过长,在网页上容易出现卡死的情况,不利于用户体验。为了解决这种情况,我们可以在视图中加入分布式任务,让他处理一些耗时的业务流程,从而缩短用户响应时间。
Django的分布式主要由Celery框架实现,这是Python开发的分布式任务队列。它支持使用任务队列的方式在分布的机器、进程和线程上执行任务调度。Celery侧重与实时操作,用于生成系统每天处理数以百万计的任务。Celery本身不提供消息存储服务,它使用第三方消息服务来传递任务。目前支持RabbitMQ、Redis和MongoDB等。
本节使用第三方应用Django Celery Results、Django Celery Beat、 Celery和Redis数据库实现Django的分布式任务和定时任务开发。值得注意的是,定时任务是分布式任务的一种特殊类型任务。
首先需要安装Redis数据库,在Windows中安装Redis数据库有两种方式:在官网下载压缩包安装和在GitHub下载MSI安装程序。前者的数据库版本是最新的,但需要通过指令安装并设置相关的环境配置;后者是旧版本,但安装方法是傻瓜式安装,启动程序后单击安装按钮即可完成安装。两者的下载地址如下:
#官网下载地址 https://redis.io/download #github下载地址 https://github.com/MicrosoftArchive/redis/releases
Redis数据库的安装过程本书就不详细讲述了,读者可以自行查阅相关的资料。除了安装Redis数据库之外,还可以安装Redis数据库的可视化工具,可视化工具可以帮助初次接触Redis的读者了解数据库结构。本书使用Redis Desktop Manager作为Redis的可视化工具,如下图:
Redis Desktop Manager
下一步是按照本节所需要的功能模块,主要的功能模块有:celery、redis、django-celery-results、django-celery-beat和eventlet。这些功能模块能通过pip完成安装,安装指令如下:
pip install celery pip install redis pip install django-celery-results pip install django-celery-beat pip install eventlet
每个功能模块负责实现不同的功能,在此简单讲解各个功能模块的具体作用,其说明如下:
1、celery:安装Celery框架,实现分布式任务调度。
2、redis:使Python与Redis数据库实现连接。
3、django-celery-results:基于Celery基础上封装的分布式任务功能,主要适用于Django。
4、django-celery-beat:基于Celery基础上封装的定时任务功能,主要适用于Django。
5、eventlet:Python的协程并发库,这是Celery实现分布式的并发模式之一。
在MyDjango项目中,分别在MyDjango文件夹创建celery.py和在项目应用index中tasks.py。前者是在Django框架中引入Celery框架,后者是创建MyDjango的分布式任务。MyDjango目录结构如图:

然后在celery.py和tasks.py文件中分别编写功能代码。celery.py的代码基本是固定的,而tasks.py的代码可以根据需求自行编写。两者代码如下:
#celery.py from __future__ import absolute_import, unicode_literals import os from celery import Celery # 获取settings.py的配置信息 os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # 定义Celery对象,并将项目配置信息加载到对象中。 # Celery的参数一般以为项目名命名 app = Celery('MyDjango') app.config_from_object('django.conf:settings', namespace='CELERY') app.autodiscover_tasks() # 创建测试任务 @app.task(bind=True) def debug_task(self): print('Request: {0!r}'.format(self.request)) #tasks.py from celery import shared_task from .models import * import time # 带参数的分布式任务 @shared_task def updateData(product_id, value): Product.objects.filter(id=product_id).update(weight=value) # 该任务用于执行定时任务 @shared_task def timing(): now = time.strftime("%H:%M:%S") with open("E:\\output.txt", "a") as f: f.write("The time is " + now) f.write("\n") f.close()
从celery.py的代码得知,该文件是将Celery框架进行实例化并生成app对象。现在还需要将app对象与MyDjango项目进行连接,使项目可以执行分布式任务。在celery.py同一级目录的__init__.py中编写相关代码,当MyDjango初始化时,Django会字段加载app对象。__init__.py的代码如下:
from __future__ import absolute_import, unicode_literals from .celery import app as celery_app __all__ = ['celery_app']
再分析tasks.py中的函数updateData可知,该函数是对模型Product进行读写操作。因此,我们需要在models.py中定义模型Product,然后对模型Product执行数据迁移,并在对应的数据表中导入相关的数据内容。模型Product的定义如下:
from django.db import models # 创建产品信息表 class Product(models.Model): id = models.AutoField('序号', primary_key=True) name = models.CharField('名称',max_length=50) weight = models.CharField('重量',max_length=20) describe = models.CharField('描述',max_length=500) # 设置返回值 def __str__(self): return self.name
将定义好的模型Product执行数据迁移,在数据库中生成数据表index_product,并且对数据表导入相关数据内容,数据表index_product的数据信息如下图:

数据表index_product的数据信息
接着在MyDjango的settings.py中配置Celery的配置信息,由于本节需要实现分布式任务和定时任务,因此配置信息主要对两者进行配置,具体的配置内容如下:
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'index', # 添加分布式任务功能 'django_celery_results', # 添加定时任务功能 'django_celery_beat' ] # 设置存储Celery任务队列的Redis数据库 CELERY_BROKER_URL = 'redis://192.168.10.100:6379/0' CELERY_ACCEPT_CONTENT = ['json'] CELERY_TASK_SERIALIZER = 'json' # 设置存储Celery任务结果的数据库 CELERY_RESULT_BACKEND = 'django-db' # 设置定时任务相关配置 CELERY_ENABLE_UTC = False CELERY_BEAT_SCHEDULER = 'django_celery_beat.schedulers:DatabaseScheduler'
配置完成后,需要再次执行数据迁移,因为分布式任务和定时任务在运行过程中需要依赖数据表才能完成任务执行。完成数据迁移后,打开项目的数据库,可以看到项目一共生成了17个数据表,如下图:
MyDjango的数据库结构
最后在项目应用index的urls.py和views.py中分别编写URL路由地址和视图函数,当用户访问网页时,MyDjango将字段执行分布式任务。urls.py和views.py的代码如下:
#index/urls.py from django.urls import path from . import views urlpatterns = [ # 首页的URL path('', views.index), ] #index/views.py from django.http import HttpResponse from .tasks import updateData def index(request): # 传递参数并执行异步任务 updateData.delay(10, '140g') return HttpResponse("Hello Celery")
至此,我们已完成Django分布式功能的代码开发,接下来讲述如何使用分布式任务和定时任务。首先启动MyDjango项目,然后单击PyCharm的Terminal,并输入以下指令启动Celery:
#指令中的MyDjango是项目名 celery -A MyDjango worker -l info -P eventlet
Celery启动成功后,Celery会自动加载MyDjango定义的分布式任务,并且显示相关的数据库连接信息,如下图:
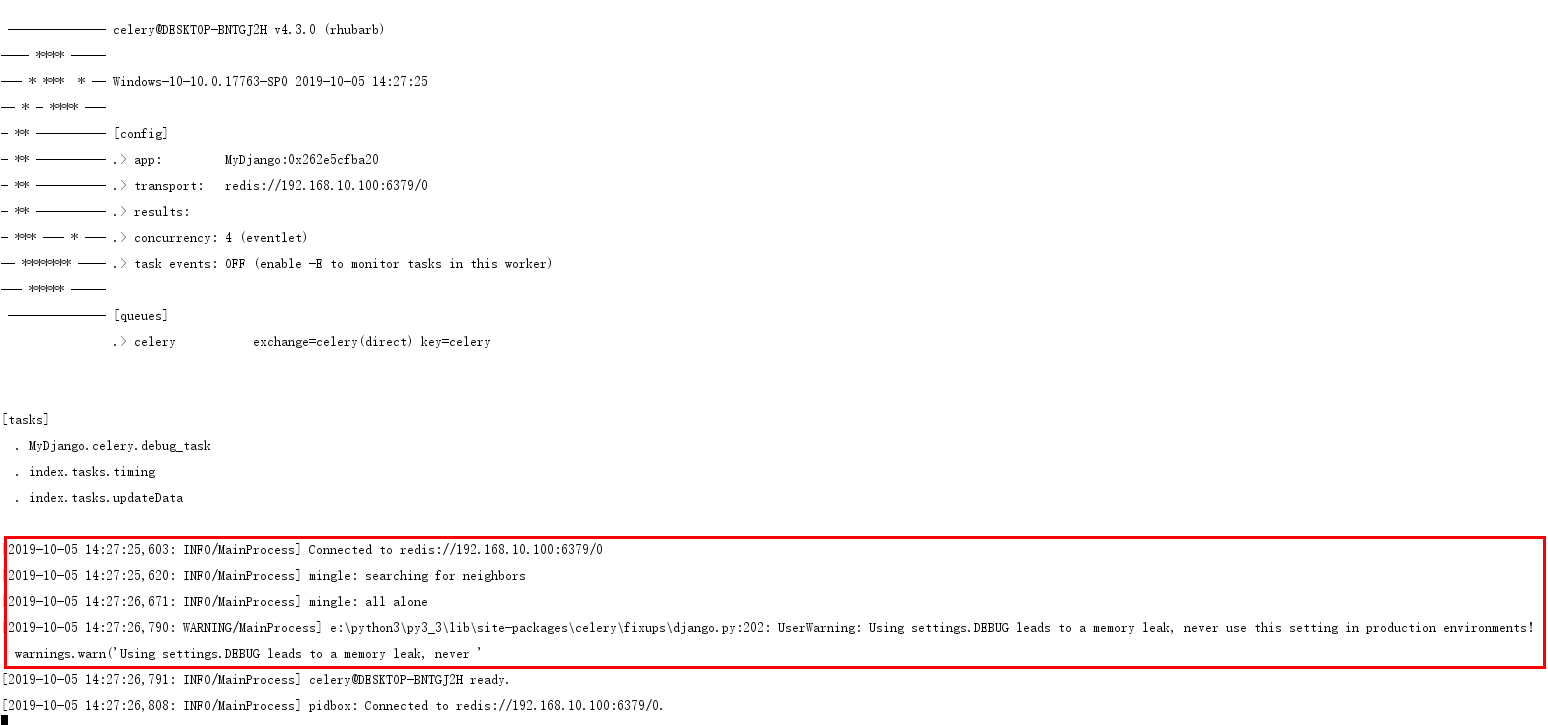
Celery启动消息
在浏览器上输入http://127.0.0.1:8000/,视图函数index将会执行分布式任务updateData,该任务是在数据表index_product卡找到ID=10的数据,然后将该数据的字段weight内容改为140g。当分布式任务执行成功后,执行的结果会显示在Terminal中,并以及保存到数据表django_celery_results_taskresult中,如下图所示:

分布式任务执行结果
下一步是使用定时任务,定时任务主要通过Admin后台生成。首先在MyDjango中创建超级用户root并登录到Admin后台,然后进入Periodic tasks并且创建定时任务,将任务设置为每间隔3秒执行函数timing,如下图:
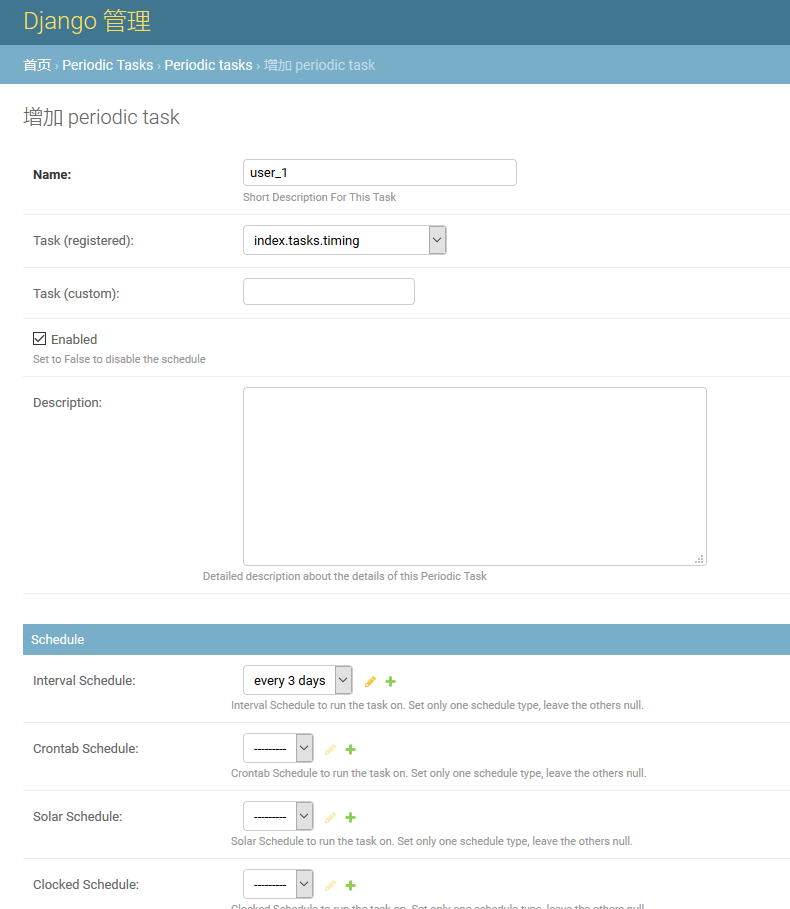
任务设置完毕后,我们通过输入指令来启动定时任务。在输入指令之前,必须保证MyDjango和Celery处于运行状态。简单来说,如果使用CMD模式来启动定时任务,需要启动三个CMD窗口,一次输入以下指令:
#启动MyDjango python manage.py runserver 8000 #启动 celery celery -A MyDjango worker -l info -P eventlet #启动定时任务 celery -A MyDjango beat -l info -S django
如果在PyCharm中启动定时任务,可以在Terminal下新建会话窗口,输入相应的指令即可。定时任务启动后,每隔三秒会执行一次程序,在Terminal和数据表django_celery_results_taskresult中都可以查看相关的执行情况,如下图:
13.6 本章小结
本章主要讲述了Django的第三方功能应用,将网站中常用的功能进行封装处理,避免开发人员重复造轮子,缩减开发时间以及维护成本。在本章讲述的第三方功能应用的实现过程中,我们总结出大致的实现过程:
1、在settings.py的INSTALLED_APPS中添加应用功能以及设置该功能的相关配置。
2、创建新的.py文件,主要对功能进行实例化或定义相关的对象,如Django Rest Framework的serializers.py和搜索引擎的search_indexes.py等。
3、设置项目的URL地址以及调用第三方功能内置的URL地址,如Django Social Auth和Django Simple Captcha等。
4、在项目的视图函数中,调用第三方功能的对象或实例化对象,使其作用于模型或模板,在网站中生成相应的功能界面。
