
163相册验证码图片的识别手记之二 --- 识别[转]
声明: 此文章只是记录我在处理163相册验证码图片识别过程时的想法思路,在此发表只是纯粹基于技术探讨目的.因此在文章中不会提供任何源码下载!!任何人利用这里介绍的方法所做任何事情而出现的责任本人概不负责!!如果需要转载此文,请注明原作者和出处!!
识别验证码一般是要经过“去干扰”,“切字”,“识别”三步处理。
一、切字:
切字即是将图片里的每个验证码都分别“切”开,这样才能进行下一步的验证码识别,并且“切字”切出来的“字”顺序也关系到识别出来的字符顺序,比如以下验证码样例图片:
![]()
则应该需要切出“7”,“4”,“3”,“7”,“7”五个字图。
对于不同的验证码图片,“切字”的方法也不尽相同,如对于一些验证码出现位置固定的验证码图片则可以直接从图形中分析出字坐标,再进行“切字”即可。而对于一些采用了“变位”干扰的验证码图片(如163相册的)就不能采用固定坐标来“切字”了,并且对于某些字符相连的验证码图片(如Google的),“切字”比“去干扰”还更头痛!!(-_#碰到这类的验证码图片,我一般放弃。咔咔!)
对163相册验证码图片进行“切字”其时还是很简单,因为验证码字符之间是没有任何相连,只是采用了“变位”干扰,但对于这种图形使用“去白拆分法”(嘿嘿,这方法名是我自己名的命)则基本是万能方法。
去白拆分法:
也就是先将空白的头尾行/列去掉,再按空白列拆分为多个子图,再将这几个子图的头尾空白行/列去掉,经过这几步处理后,那些拆分出来的子图就是最终“切”出来的验证码字图了。
1,去白:去除验证码图片的头尾空白行/列
比如上面的验证码图片(为了便于说明我在画板程序中打开样例图并将图形放大了6倍和显示网格):
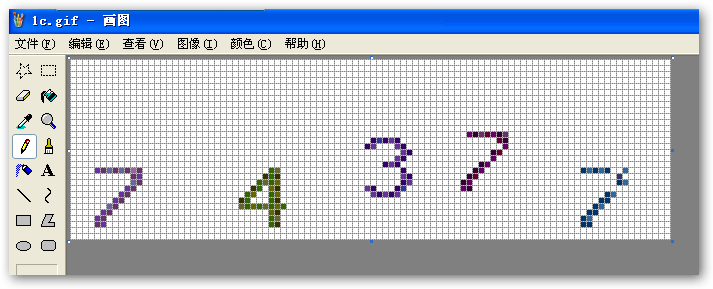
去空白的头尾行/列则是将下面的黄色区域都去掉,只留中间部分。
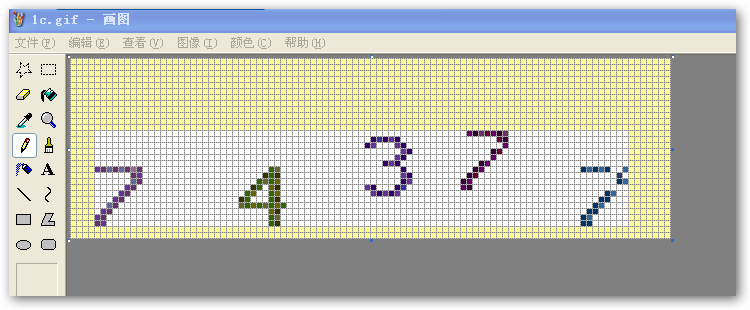
经过“去白”处理后,图形就变成了如下样式:
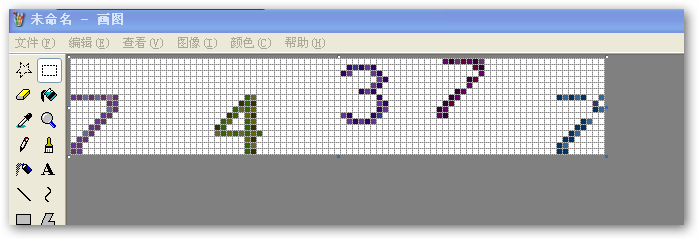
2,拆分 : 按空白列拆分图形,如下图根据红线部分拆分就基本将所有验证码字图(7,4,3,7,7)都“切”出来了,如图:
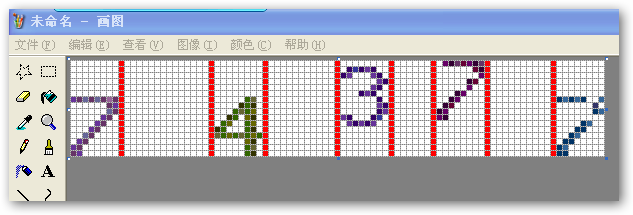
但要注意,经过上面折分后字图里也还是包含有空白的头尾行,所以也要“去白”处理,如下图:(也就是将那些黄色区域去掉)
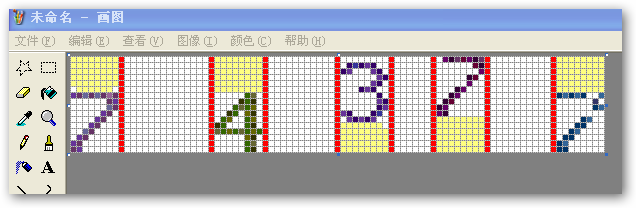
经这样处理后的“字图”就可以用于识别了:)
注意:对于某些被干扰破坏得很严重的图形,在进行“去白拆分”操作时要确保“切”到的字图高宽度为“源数字图”的大小。
如下图中的“5”字:

二、验证码识别:
当经过“去干扰”,“切字”处理后,识别就是一个很轻松的工作了。一般采用图形结构“相似度比较法”进行识别,这样对于一些在“去干扰”时就破坏了结构的字图(如上面图片中最后二个“7”字)也可以识别出来,但也因为是对图形结构进行“相似”比较,所以就存在有识别失败的可能性。
相似度比较法:
此方法是将每个“切”出来的字图和所有源数字图逐一比较,并得出一个图形结构的相似度值,然后再取相似度值最高的“源数字图”,这样“字图”对应的字符就识别出来了。
图形结构相似度:
假如将一幅图看成一个二维数组(一维下标对应X轴,二维下标对应Y轴),数组里的数据就是每个象素点的颜色值。那么求两副图图形结构的相似度值,则是等价于求两个二维数组里的数据的相似度统计。
假如有两个数组的数据分别如下:
二维数组A里的数据:("4"字的01图)
二维数组B里的数据:("4"字被干扰破坏后的01图,注意红色部分)
求A与B的相似度,则分别比较AB对应“行”里的数据,找出不相同点的数量,也就是共有3次不相同,所以相似度值大概为96% ,因此就可以认为B是A了。
注:对于相似度取什么值就可考虑AB“相等”,这个大家要权衡一下,毕竟取的值过低识差率可是很大的。


