

scarpy架构组成和工作原理
汽车之间案例:

import scrapy class CarSpider(scrapy.Spider): name = 'car' allowed_domains = ['https://car.autohome.com.cn/price/brand-15.html'] # 注意如果你的请求的接口是html为结尾的 那么是不需要加/的 start_urls = ['https://car.autohome.com.cn/price/brand-15.html'] def parse(self, response): name_list = response.xpath('//div[@class="main-title"]/a/text()') price_list = response.xpath('//div[@class="main-lever"]//span/span/text()') for i in range(len(name_list)): name = name_list[i].extract() price = price_list[i].extract() print(name,price)
scrapy架构组成:
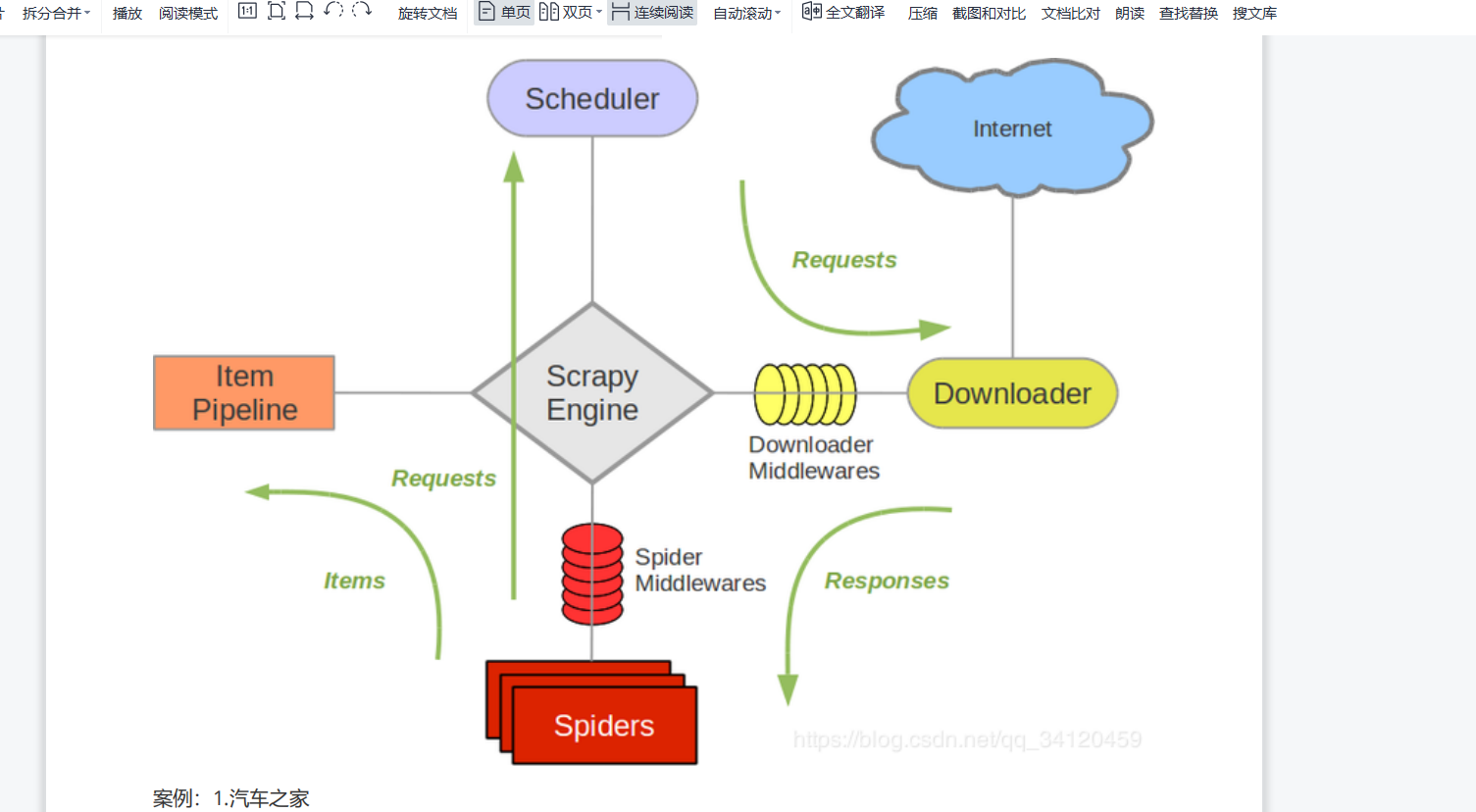
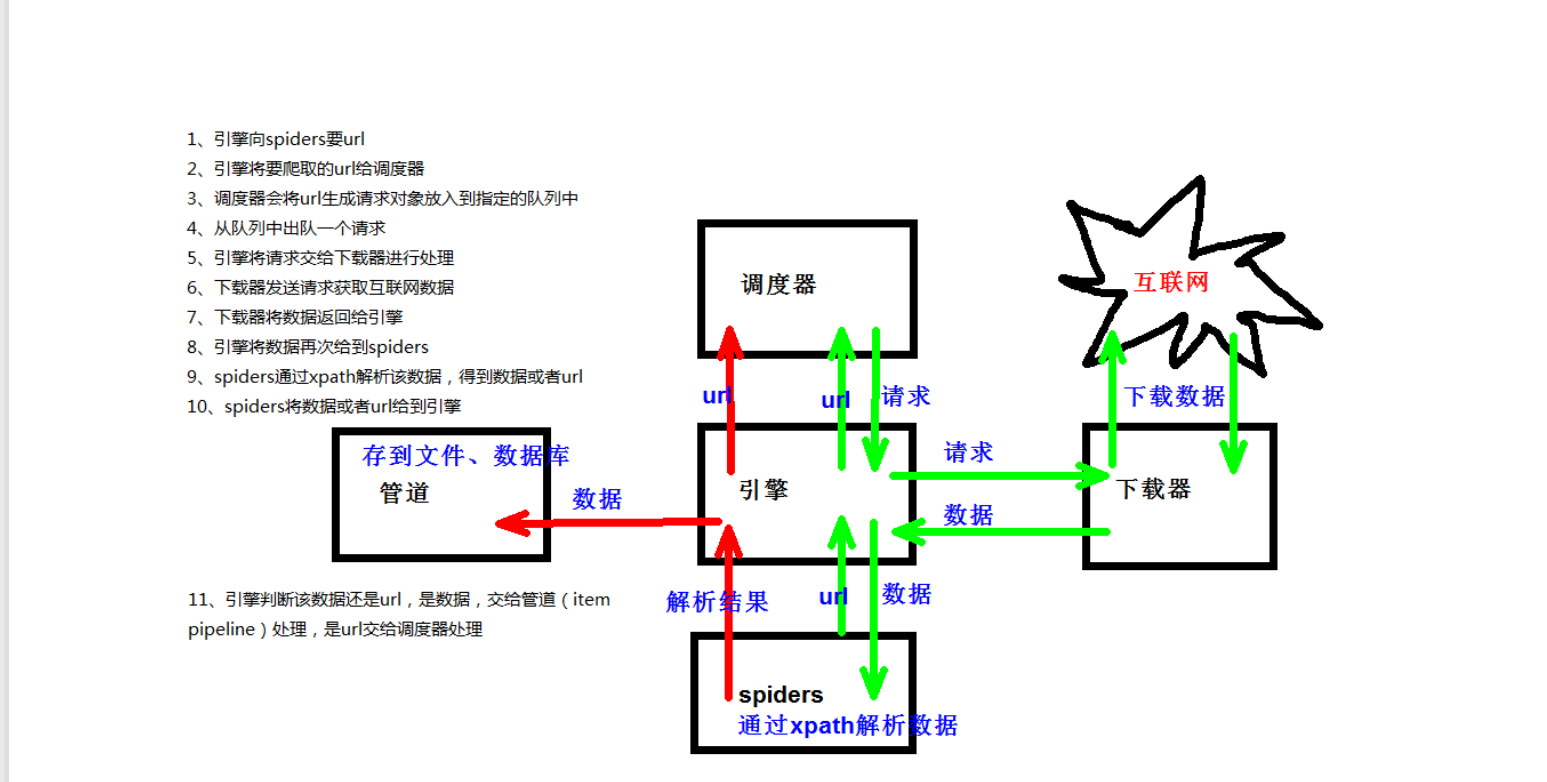
工作原理:


· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 字符编码:从基础到乱码解决
· 提示词工程——AI应用必不可少的技术
2022-01-04 Android 项目结构