requests 库

requests和urllib功能一样,优点更多。
基本使用:
import requests url = 'http://www.baidu.com' response = requests.get(url=url) # 一个类型和六个属性 # Response类型 # print(type(response)) # 设置响应的编码格式 # response.encoding = 'utf-8' # 以字符串的形式来返回了网页的源码 # print(response.text) # 返回一个url地址 # print(response.url) # 返回的是二进制的数据 # print(response.content) # 返回响应的状态码 # print(response.status_code) # 返回的是响应头 print(response.headers)
get请求&&和urllib的区别
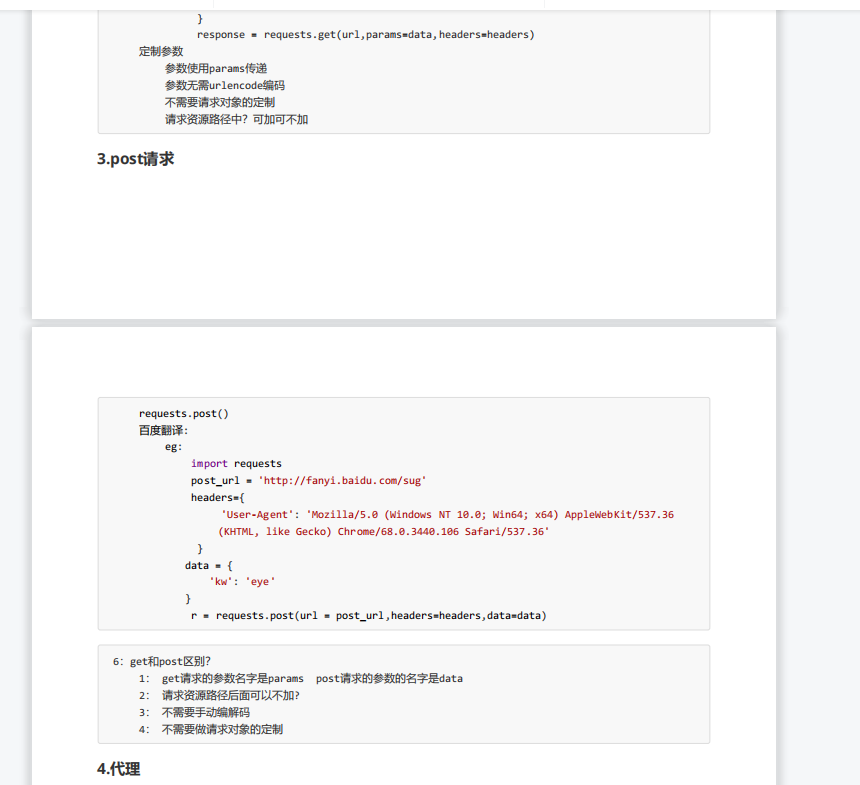
# urllib # (1) 一个类型以及六个方法 # (2)get请求 # (3)post请求 百度翻译 # (4)ajax的get请求 # (5)ajax的post请求 # (6)cookie登陆 微博 # (7)代理 # requests # (1)一个类型以及六个属性 # (2)get请求 # (3)post请求 # (4)代理 # (5)cookie 验证码 import requests url = 'https://www.baidu.com/s' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' } data = { 'wd':'北京' } # url 请求资源路径 # params 参数 # kwargs 字典 response = requests.get(url=url,params=data,headers=headers) content = response.text print(content) # 总结: # (1)参数使用params传递 # (2)参数无需urlencode编码 # (3)不需要请求对象的定制 # (4)请求资源路径中的?可以加也可以不加
post请求
import requests url = 'https://fanyi.baidu.com/sug' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' } data = { 'kw': 'eye' } # url 请求地址 # data 请求参数 # kwargs 字典 response = requests.post(url=url,data=data,headers=headers) content =response.text import json obj = json.loads(content,encoding='utf-8') print(obj) # 总结: # (1)post请求 是不需要编解码 # (2)post请求的参数是data # (3)不需要请求对象的定制
import requests url = 'https://fanyi.baidu.com/sug' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' } data = { 'kw': 'eye' } # url 请求地址 # data 请求参数 # kwargs 字典 response = requests.post(url=url,data=data,headers=headers) content =response.text import json obj = json.loads(content,encoding='utf-8') print(obj) # 总结: # (1)post请求 是不需要编解码 # (2)post请求的参数是data # (3)不需要请求对象的定制
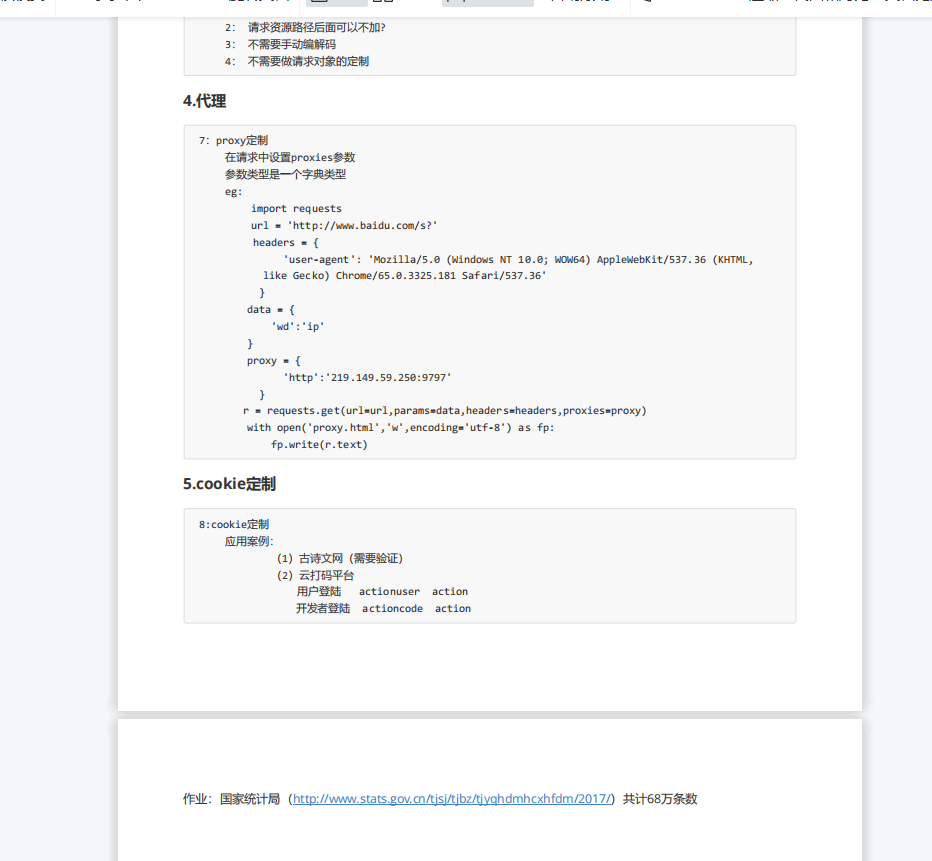
代理:
import requests url = 'http://www.baidu.com/s?' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36', } data = { 'wd':'ip' } proxy = { 'http':'212.129.251.55:16816' } response = requests.get(url = url,params=data,headers = headers,proxies = proxy) content = response.text with open('daili.html','w',encoding='utf-8')as fp: fp.write(content)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号