

Selenium
Selenium介绍:Selenium访问游览器可以像真正的用户一样在访问,确认且支持无界面游览器操作。’
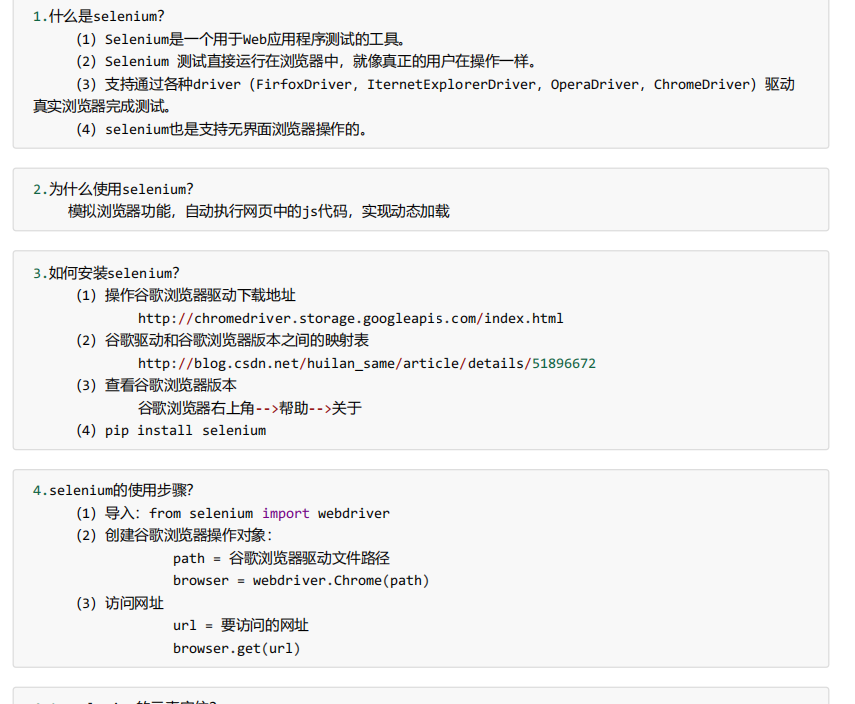
Selenium基本使用
直接访问京东的话,会有一些资源被屏蔽,依靠selenium工具

# (1)导入selenium from selenium import webdriver # (2) 创建浏览器操作对象 path = 'chromedriver.exe' browser = webdriver.Chrome(path) # (3)访问网站 # url = 'https://www.baidu.com' # # browser.get(url) url = 'https://www.jd.com/' browser.get(url) # page_source获取网页源码 content = browser.page_source print(content)

这里显示警告,该类型的警告大多属于版本更新时,所使用的方法过时的原因;某方法在当前版本被重构,依旧可以传入参数,但是在之后的某个版本会被删除。参考:https://www.cnblogs.com/hls-code/p/15762958.html
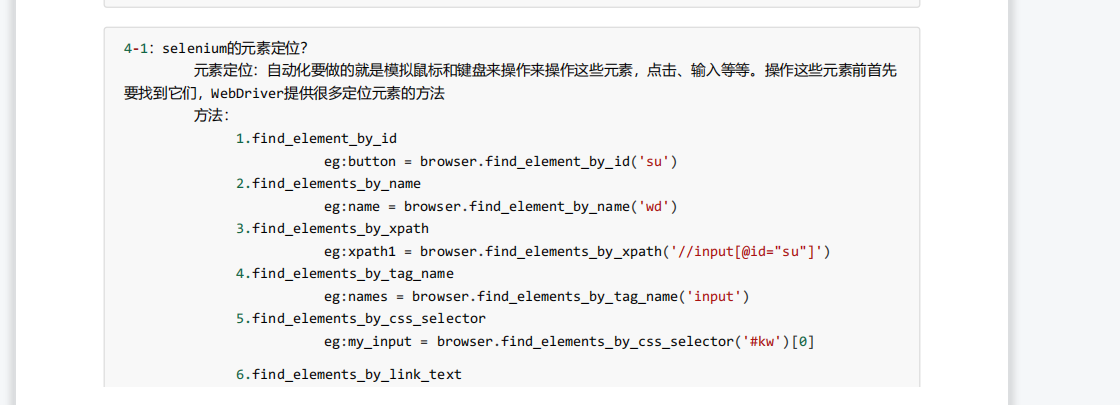
Selenium元素定位:里面的方法过时了,可以去网上找最新的方法。
from selenium import webdriver path = 'chromedriver.exe' browser = webdriver.Chrome(path) url = 'https://www.baidu.com' browser.get(url) # 元素定位 # 根据id来找到对象 # button = browser.find_element_by_id('su') # print(button) # 根据标签属性的属性值来获取对象的 # button = browser.find_element_by_name('wd') # print(button) # 根据xpath语句来获取对象 # button = browser.find_elements_by_xpath('//input[@id="su"]') # print(button) # 根据标签的名字来获取对象 # button = browser.find_elements_by_tag_name('input') # print(button) # 使用的bs4的语法来获取对象 # button = browser.find_elements_by_css_selector('#su') # print(button) # button = browser.find_element_by_link_text('直播') # print(button)
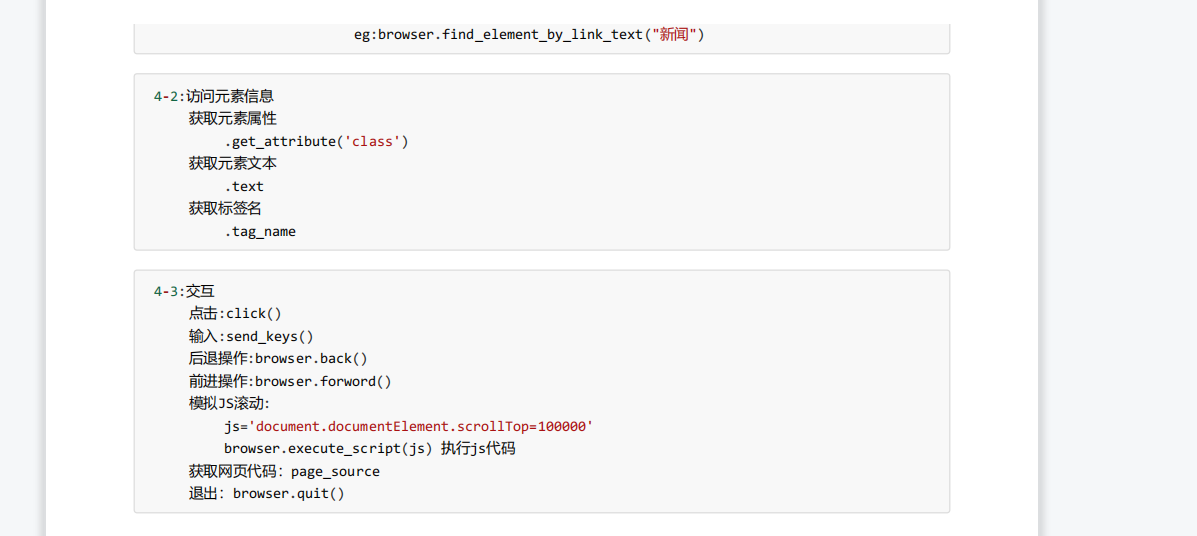
Selenium元素信息
from selenium import webdriver path = 'chromedriver.exe' browser = webdriver.Chrome(path) url = 'http://www.baidu.com' browser.get(url) input = browser.find_element_by_id('su') # 获取标签的属性(这个获取的是class属性) print(input.get_attribute('class')) # 获取标签的名字 print(input.tag_name) # 获取元素文本(标签之间的字) a = browser.find_element_by_link_text('新闻') print(a.text)
Selenium 交互
from selenium import webdriver # 创建浏览器对象 path = 'chromedriver.exe' browser = webdriver.Chrome(path) # url url = 'https://www.baidu.com' browser.get(url) import time time.sleep(2) # 获取文本框的对象 input = browser.find_element_by_id('kw') # 在文本框中输入周杰伦 input.send_keys('周杰伦') time.sleep(2) # 获取百度一下的按钮 button = browser.find_element_by_id('su') # 点击按钮 button.click() time.sleep(2) # 滑到底部(距离顶部多少距离) js_bottom = 'document.documentElement.scrollTop=100000' browser.execute_script(js_bottom) time.sleep(2) # 获取下一页的按钮 next = browser.find_element_by_xpath('//a[@class="n"]') # 点击下一页 next.click() time.sleep(2) # 回到上一页 browser.back() time.sleep(2) # 回去 browser.forward() time.sleep(3) # 退出 browser.quit()


· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 字符编码:从基础到乱码解决
· 提示词工程——AI应用必不可少的技术