爬虫3---Urllib库完善
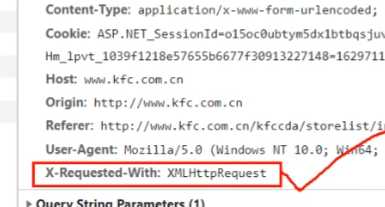
当有红框中的内容时,就是ajax请求
urllib 异常
import urllib.request import urllib.error # url = 'https://blog.csdn.net/sulixu/article/details/1198189491' url = 'http://www.doudan1111.com' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' } try: request = urllib.request.Request(url = url, headers = headers) response = urllib.request.urlopen(request) content = response.read().decode('utf-8') print(content) except urllib.error.HTTPError: print('系统正在升级。。。') except urllib.error.URLError: print('我都说了 系统正在升级。。。')
urllib 的cooike登陆:演示代码为微博
# 适用的场景:数据采集的时候 需要绕过登陆 然后进入到某个页面 # 个人信息页面是utf-8 但是还报错了编码错误 因为并没有进入到个人信息页面 而是跳转到了登陆页面 # 那么登陆页面不是utf-8 所以报错 # 什么情况下访问不成功? # 因为请求头的信息不够 所以访问不成功 import urllib.request url = 'https://weibo.cn/6451491586/info' headers = { # ':authority': 'weibo.cn', # ':method': 'GET', # ':path': '/6451491586/info', # ':scheme': 'https', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', # 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9', 'cache-control': 'max-age=0', # cookie中携带着你的登陆信息 如果有登陆之后的cookie 那么我们就可以携带着cookie进入到任何页面 'cookie': '_T_WM=24c44910ba98d188fced94ba0da5960e; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFxxfgNNUmXi4YiaYZKr_J_5NHD95QcSh-pSh.pSKncWs4DqcjiqgSXIgvVPcpD; SUB=_2A25MKKG_DeRhGeBK7lMV-S_JwzqIHXVv0s_3rDV6PUJbktCOLXL2kW1NR6e0UHkCGcyvxTYyKB2OV9aloJJ7mUNz; SSOLoginState=1630327279', # referer 判断当前路径是不是由上一个路径进来的 一般情况下 是做图片防盗链 'referer': 'https://weibo.cn/', 'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"', 'sec-ch-ua-mobile': '?0', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'same-origin', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36', } # 请求对象的定制 request = urllib.request.Request(url=url,headers=headers) # 模拟浏览器向服务器发送请求 response = urllib.request.urlopen(request) # 获取响应的数据 content = response.read().decode('utf-8') # 将数据保存到本地 with open('weibo.html','w',encoding='utf-8')as fp: fp.write(content)
Handler处理器:
Hadeler可以定制更高级的请求头(动态Cookie或者代理)
# 需求 使用handler来访问百度 获取网页源码 import urllib.request url = 'http://www.baidu.com' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' } request = urllib.request.Request(url = url,headers = headers) # handler build_opener open # (1)获取hanlder对象 handler = urllib.request.HTTPHandler() # (2)获取opener对象 opener = urllib.request.build_opener(handler) # (3) 调用open方法 response = opener.open(request) content = response.read().decode('utf-8') print(content)
.
代理服务器:
反爬IP的解决办法
import urllib.request url = 'http://www.baidu.com/s?wd=ip' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' } # 请求对象的定制 request = urllib.request.Request(url = url,headers= headers) # 模拟浏览器访问服务器 # response = urllib.request.urlopen(request) proxies = { 'http':'118.24.219.151:16817' } # handler build_opener open handler = urllib.request.ProxyHandler(proxies = proxies) opener = urllib.request.build_opener(handler) response = opener.open(request) # 获取响应的信息 content = response.read().decode('utf-8') # 保存 with open('daili.html','w',encoding='utf-8')as fp: fp.write(content)
代理池:
import urllib.request proxies_pool = [ {'http':'118.24.219.151:16817'}, {'http':'118.24.219.151:16817'}, ] import random proxies = random.choice(proxies_pool) url = 'http://www.baidu.com/s?wd=ip' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' } request = urllib.request.Request(url = url,headers=headers) handler = urllib.request.ProxyHandler(proxies=proxies) opener = urllib.request.build_opener(handler) response = opener.open(request) content = response.read().decode('utf-8') with open('daili.html','w',encoding='utf-8')as fp: fp.write(content)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号