

C# 之Dictionary(字典)底层源码解析
Dictionary是我们经常使用的,一起来看看它是如何构造的,及有哪些优缺点。
Dictionary是一种键值对的形式存放数据,即 key值 、value 值 一 一映射的。key的类型没有限制,可以是整数、字符串甚至是实例对象。
Dictionary的实现原理,有两个关键的算法,Hash算法 和 解决Hash 碰撞冲突 的算法。key value的映射关系用的就是Hash函数来建立的。
Hash算法:
Hash算法是一种数字摘要算法,将不定长度的二进制数据集给映射到一个较短的二进制长度数据集。常见的MD5算法就是一种Hash算法,通过MD5算法 对任何数据生成数字摘要。实现Hash算法的函数 成为Hash函数。
对于实例对象和字符串来说,它们没有直接的数字作为Hash标准,因此它们需要通过内存地址计算一个Hash值,计算这个内存对象的函数也就是Hash函数。
Hash函数:
Hash函数有很多种算法,最简单的就是 除留余数法【模(Mod)的操作】,取key 被某个不大于散列表 表长m的数p 除后所得余数作为散列地址。即 hash_key = key % p , p<=m。
Hash函数有以下特征:
1.相同的key 进行Hash计算,得到的结果一定是同一Hash地址。HashFunc(Key1) == HashFunc(Key1)。
2.不相同的key 进行Hash计算,得到的结果也可能是同一Hash地址。key1 != key2 = > HashFunc(Key1)== HashFunc(Key2)。【这种现象称之为Hash冲突】
Hash冲突:
处理Hash冲突的方法中,通常有开放定址法、再Hash法、链地址法、建立一个公共溢出区等。Dictionary使用的是 链地址法 又称 拉链法。
下图 Hash冲突示意图:
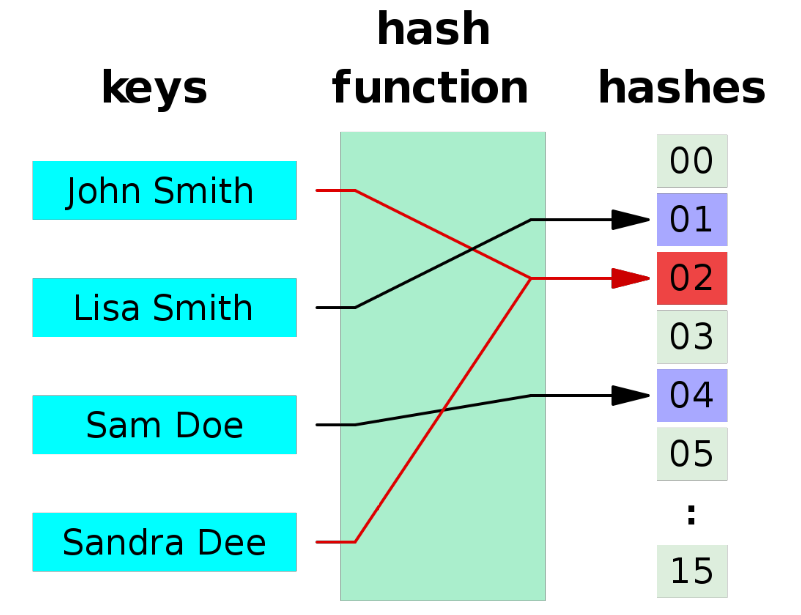
Sandra Dee 和 John Smith 通过hash函数 运算后都落到了02的位置,产生了碰撞和冲突。
拉链法:将产⽣冲突的元素建⽴⼀个单链表,并将头指针地址存储⾄Hash表对应桶的位置。这样定位到Hash桶的位置后可通过遍历单链表的形式来查找元素。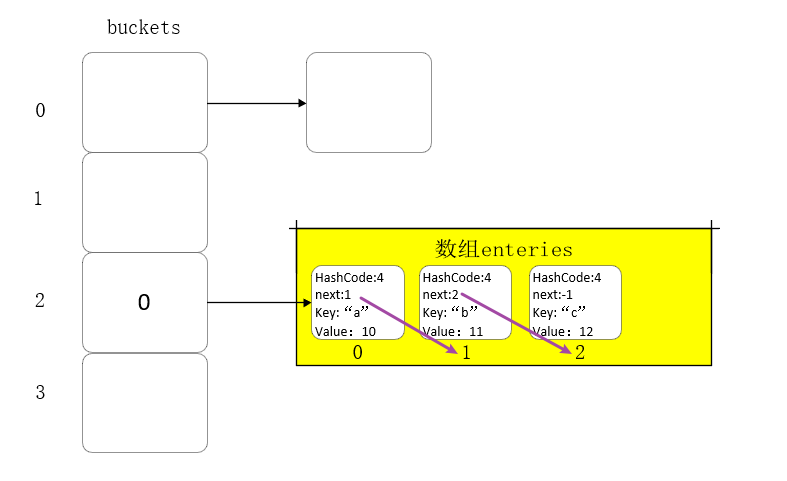
数组内的元素通过next(下一个元素的索引)形成一个单链表。
Hash桶:
是解决哈希表而引入的一个概念 ,为每一个hashCode 建立一个桶,桶里面放着一个数组(如上图 数组enteries)。
Dictionary 接口:
1.变量定义
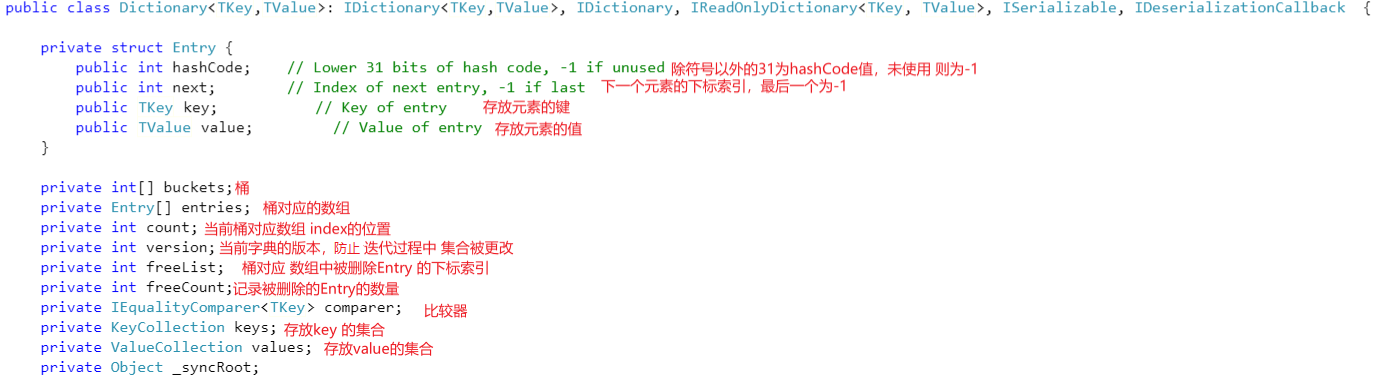
从定义可知,字典的实现底层数据结构依靠的是数组。
Add方法:




桶数量:
if (buckets == null) Initialize(0); 初始化桶
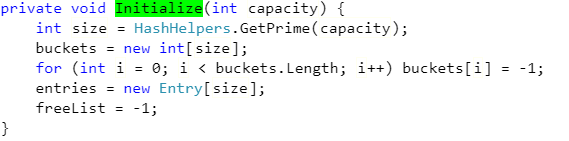
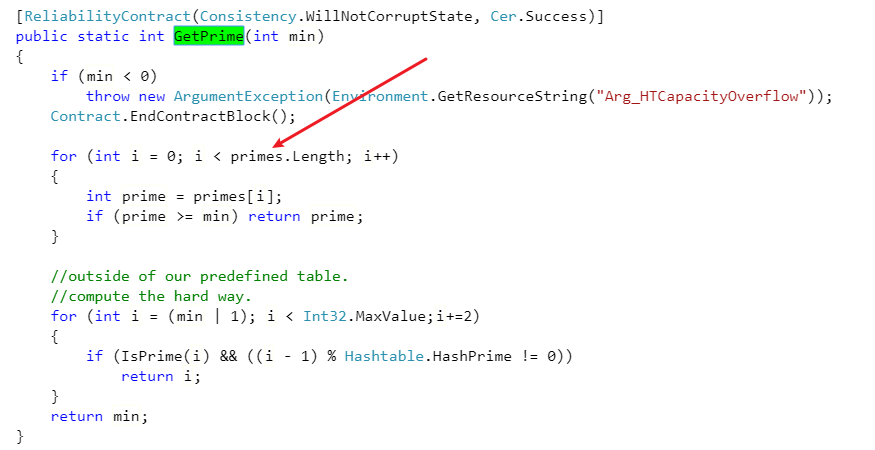

在初始化Hash桶数量的时候,若未自定义数量,首次分配3个。如果我们自定义了数量,自定义的值 会再根据 primes 数组进行计算,得出到底使用多大的桶数量。
比如 实例化字典 自定义数量 3:
System.Collections.Generic.Dictionary<int, string> dic = new System.Collections.Generic.Dictionary<int, string>(3);
Resize();扩容




Remove方法:

ContainsKey 、TryGetValue 方法,源码贴出,比较简单,不做解析。

总结:
Dictionary由数组构成,Hash函数作为地址构建,拉链法解决Hash冲突。Dictionary也是线程不安全的,因此在多线程访问的时候,需要自行加lock处理。
源码地址:https://referencesource.microsoft.com/#mscorlib/system/collections/generic/dictionary.cs


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!