
手写数字数据集AutoEncoder降噪算法
对训练数据加噪声的方法,在训练里面对 x 做如下处理,添加椒盐噪声:
bs, ch, h, w = x.shape x = x.reshape(bs, ch, h*w) + 0.2*np.random.normal(size=28*28) x = x.to(torch.float32)
数据集里面的标签 label 无用,因为 AutoEncoder 去噪是无监督方法。
一、读取数据

import torch import torch.nn as nn import torchvision import torch.optim as optim import matplotlib.pyplot as plt import numpy as np EPOCH = 5 BATCH_SIZE = 64 LR = 0.001 DOWNLOAD_MNIST = True N_TEST_IMG = 5 train_data = torchvision.datasets.MNIST( root='../mnist_data/', train=True, transform=torchvision.transforms.ToTensor(), download=DOWNLOAD_MNIST, ) test_data = torchvision.datasets.MNIST( root='../mnist_data/', train=False, transform=torchvision.transforms.ToTensor(), download=DOWNLOAD_MNIST, ) print(train_data.train_data.size()) print(train_data.train_labels.size()) train_loader=Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE,shuffle=True) test_loader=Data.DataLoader(dataset=test_data, batch_size=BATCH_SIZE,shuffle=False)
二、前3步:构建模型、设置优化器、损失函数
class AutoEncoder(nn.Module): def __init__(self): super(AutoEncoder, self).__init__() self.encoder = nn.Sequential( nn.Linear(28*28, 128), nn.ReLU(), nn.Linear(128, 64), nn.ReLU(), nn.Linear(64, 12), nn.ReLU(), # nn.Linear(12, 3), ) self.decoder = nn.Sequential( # nn.Linear(3, 12), # nn.Tanh(), nn.Linear(12, 64), nn.ReLU(), nn.Linear(64, 128), nn.ReLU(), nn.Linear(128, 28*28), # nn.Sigmoid(), ) def forward(self, x): encoded = self.encoder(x) decoded = self.decoder(encoded) return decoded AE = AutoEncoder() optimizer = optim.Adam(AE.parameters(), lr=LR) loss_func = nn.MSELoss() # 1 2 3
三、后5步:前向计算、计算损失、no_grad, backward, step,如果有验证集的话,每到一定步数在no_grad下进行验证,不需要zer_grad和backward
for epoch in range(EPOCH): for step, (x, _) in enumerate(train_loader): bs, ch, h, w = x.shape x = x.reshape(bs, ch, h*w) + 0.2*np.random.normal(size=28*28) x = x.to(torch.float32) # 4 5 code = AE.encoder(x) # https://blog.csdn.net/weixin_55191433/article/details/121402942 recon = AE.decoder(code) loss = loss_func(recon, x) optimizer.zero_grad() loss.backward() optimizer.step() if step % 100 == 0: print('Epoch:', epoch, ' | train loss: %.4f'%loss.item())
四、查看结果(测试集)
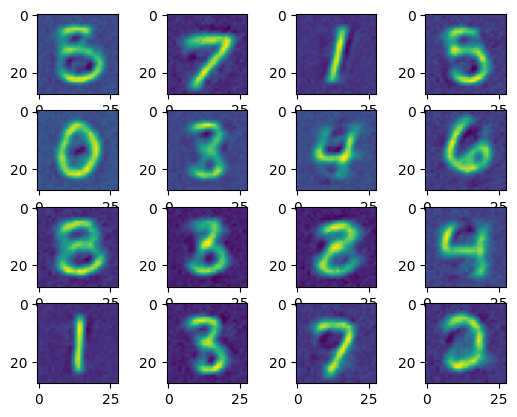
cnt = 16 idx = 0 plt.figure(1) with torch.no_grad(): for step, (x, _) in enumerate(test_loader): bs, ch, h, w = x.shape x = x.reshape(bs, ch, h*w) + 0.2*np.random.normal(size=28*28) x = x.to(torch.float32) # 4 5 code = AE.encoder(x) # https://blog.csdn.net/weixin_55191433/article/details/121402942 recon = AE.decoder(code) print(recon.shape) for i in range(16): plt.subplot(4,4,step+1) img = recon[i].squeeze().reshape(28, 28) plt.imshow(img) # loss = loss_func(recon, x) idx += 1 if idx == 16: break
结果如下:加噪声后,和通过AE去噪后。

分类:
AI、ML和Bigdata


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理