

ML-大纲
至今共有14章,我将其分为以下几类。
绪论;
线性模型、神经网络、支持向量机;
降维与度量学习、聚类;
集成学习、特征选择和稀疏学习、半监督学习;
强化学习;
概率图模型1,2、图神经网络;
生成模型;
Reinforcement Learning 强化学习
特点:RL没有监督信息,仅有环境反馈的Rewards(奖励信号);RL的反馈具有滞后性,不能立即获得(游戏在结束的时候才知道结果);序列,数据不具有独立同分布特性;Agent(智能体)当前Acion动作会影响后续获取的数据。
Agent 智能体,通常包含三部分
--Policy,是State到Action的映射
--Value Function,
--Model,通常包含状态转移和即时奖励
MDPs Markov Decision Precesses
A Markov Process is a tuple <S, P>
Markov Reward Process:<S, P, R, γ>
Return 回报
Value Function:MRP的值函数定义为从该状态出发得到的期望回报。
Bellman Equation
值函数可以分为即时奖励和带折扣的累积奖励。
Markov Decision Process <S, A, P, R, γ>
状态值函数 v(s)
动作值函数 q(s, a)
MLP问题的求解:
Prediction 策略评估问题:输入MDP和策略,输出值。
Control 策略提升问题:输入MDP,值和输出策略。
基于模型的算法:值迭代和策略迭代。
无模型:未知状态转移和回报函数
蒙特卡洛MC 方法:要求完整的采样轨迹
时间差分TD 算法:不要求完整采样轨迹
On-Policy 同策略:Sarsa
Off-Policy 异策略:Q-Learning
第十四十五十六章为表示学习、统计物理、张量网络。不考,但是SimCLR和因子图的消息传递模型,需要知道。
第十二章 图神经网络(见第三章) 十三 生成模型(见第九章),见前面章节合并,因记录较少。之后补充
第十一章 概率图模型

probability graph
第十章 强化学习
强化学习的特点是通过与环境的交互来进行学习,其目标为最大化累计奖励,最终得到的结果是一个行为策略,用于在未知环境中做出智能决策。强化学习的训练目标是最大化累计奖励,而以上其他几种的目标通常是经验风险最小化。学习算法通过执行一系列动作来获得与目标相关的奖励信号,这个奖励信号并不总是与每个动作直接相关联,无法通过标签来标识,也不能进行聚类。强化学习面临的环境是时间顺序上紧密关联的,需要考虑到先前的行动和当前状态,因此强化学习的策略会产生延迟反馈,当前的行动会影响到后续的决策和奖励。

enforcement
第九章 半监督学习
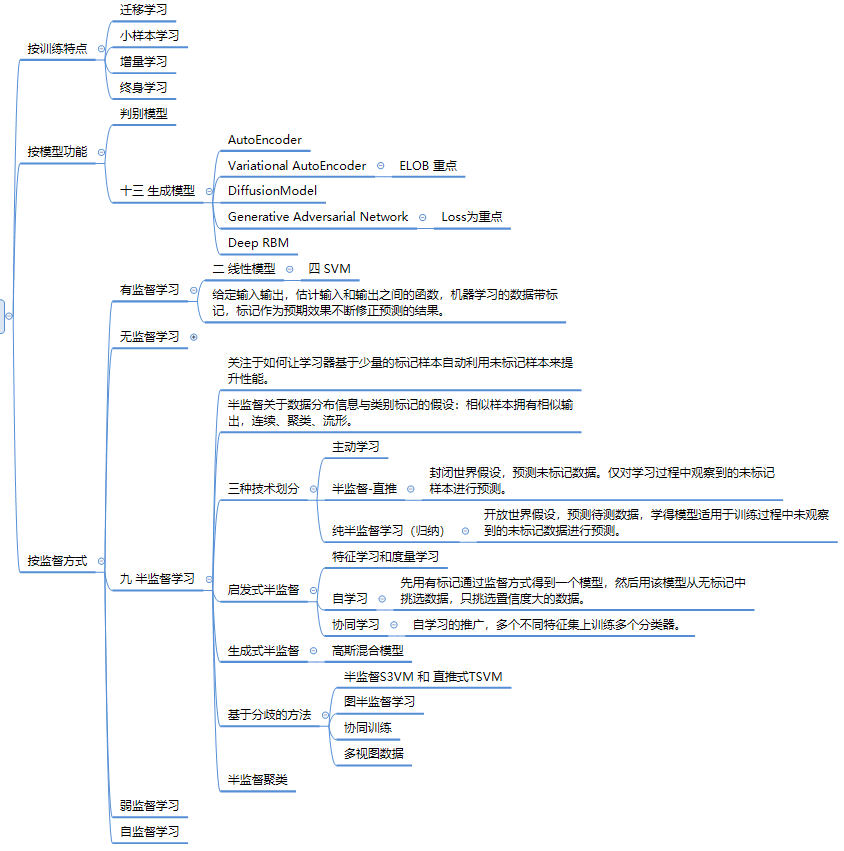
semi-supervised
第八章 选择与稀疏
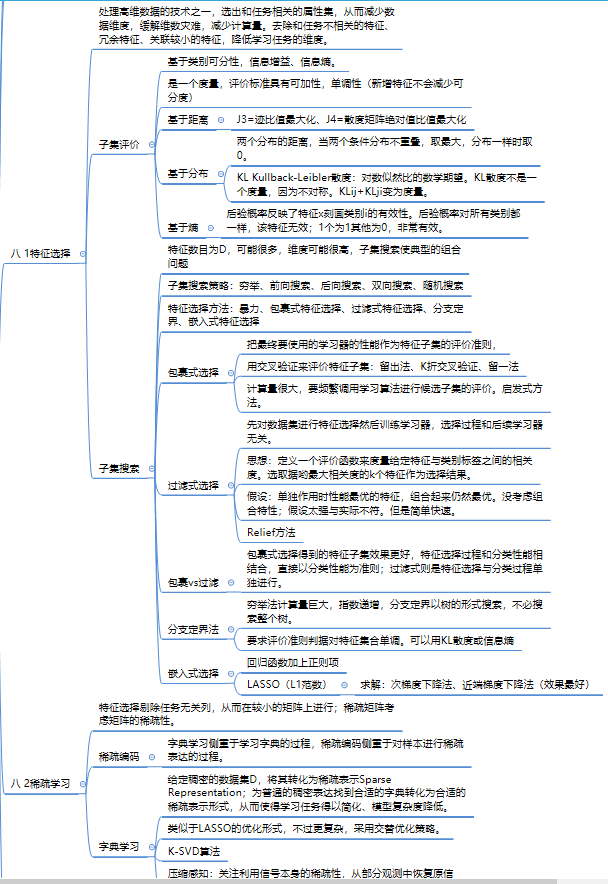
sparse
第七章 集成
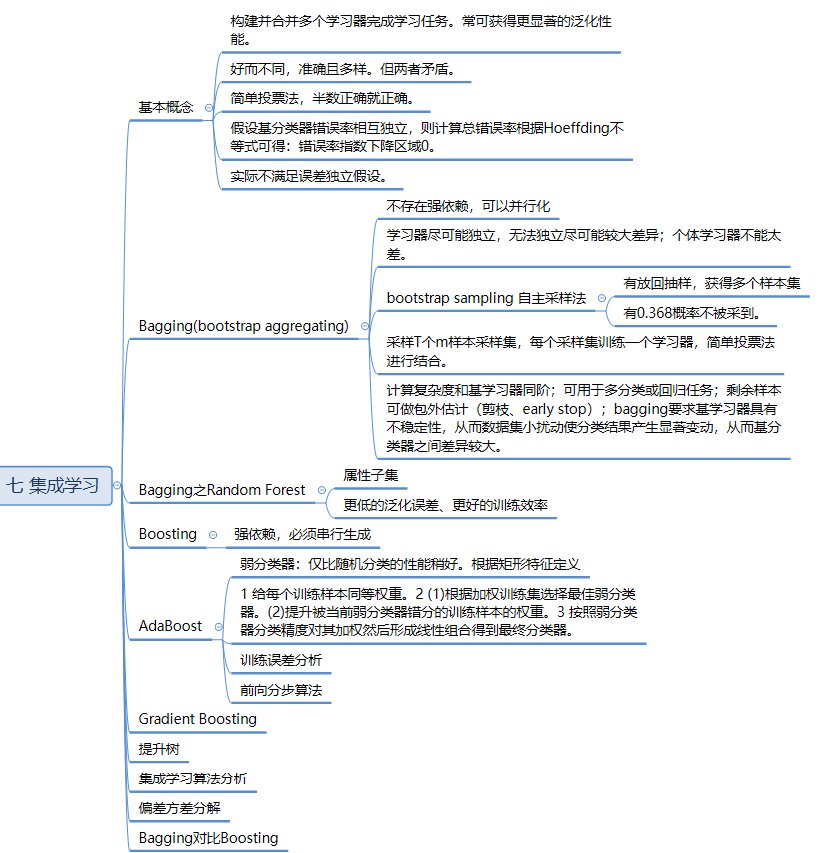
baggingboosting
第五章、第六章 降维、聚类
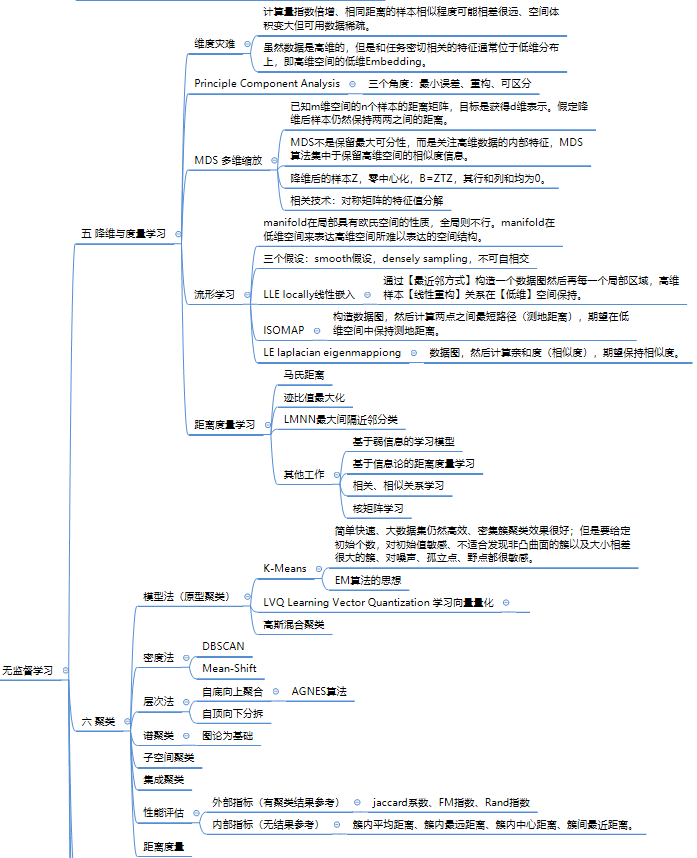
reduction, clustering
第四、十四、十五章 SVM、表示学习、统计物理
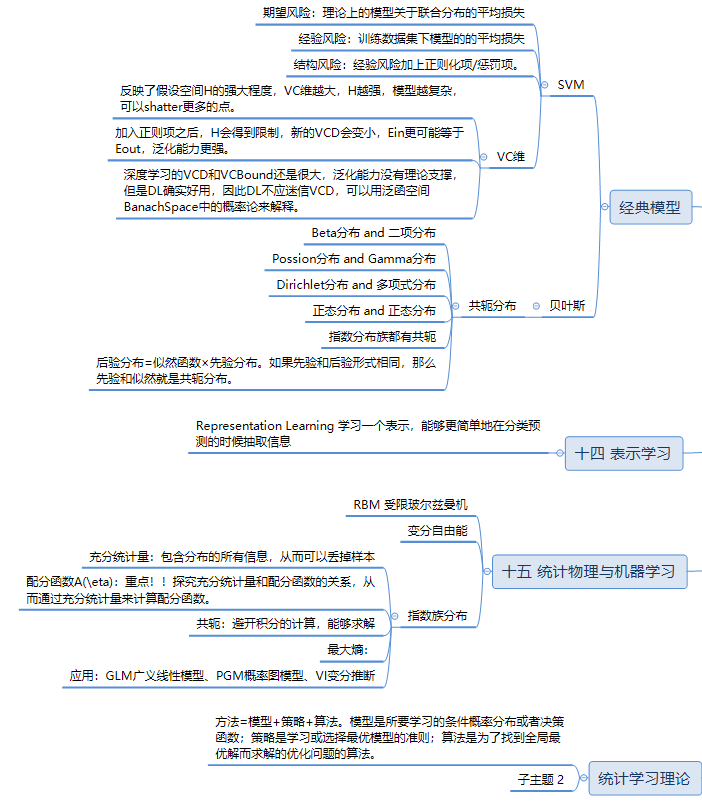
SVM、统计物理和表示的一小部分
第三章 神经网络

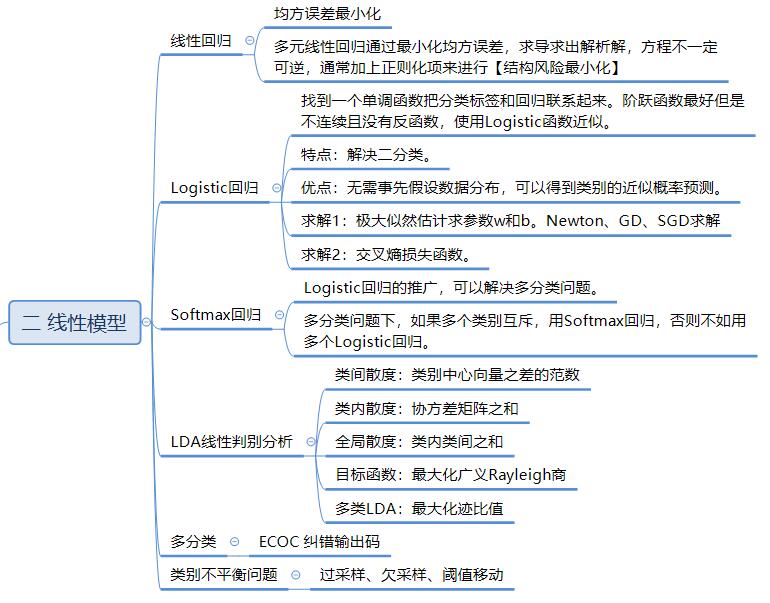
第二章 线性模型
----end

