安装pytorch的cuda版、安装jupyter与notebook、一些pandas技巧
pytorch+cuda+torvision+torchaudio的一个好用的配置
在这个网站下载本地安装用的文件:https://download.pytorch.org/whl/torch_stable.html
直接使用本地文件安装(这样最快)
(torchbert) D:\Python3Files>pip install torch-1.13.0+cu116-cp38-cp38-win_amd64.whl
(torchbert) D:\Python3Files>pip install torchvision-0.14.0+cu116-cp38-cp38-win_amd64.whl
(torchbert) D:\Python3Files>pip install torchaudio-0.13.0+cu116-cp38-cp38-win_amd64.whl
某个conda环境下安装jupyter+加速镜像
安装虚拟环境:conda create -n torchbert python==3.6
查看本机conda环境列表的两种方式:conda info --envs、conda-env list
1. 激活虚拟环境:activate envname
安装必要的依赖库,采用豆瓣镜像加速下载安装
2. pip install ipython==8.12.2 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
3. pip install jupyter==1.0.0 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
4. 添加当前环境的jupyterkernel:python -m ipykernel install --name envname
然后就可以启动jupyter notebook了。
其他常用库和版本对应
MicroSoft Visual Studio
科学计算:
numpy==1.24.4, scipy==1.9.1, pandas==1.5.3, scikit-learn==1.3.0, umap-learn==0.5.6, scikit-image==0.20.0, matplotlib==3.7.2, seaborn==0.12.2, resampy==0.2.2, numba==0.57.0
音频处理
librosa==0.10.1, ffmpeg==1.4, soundfile==0.12.1, PyAudio==0.2.13, pydub==0.25.1
深度学习组件
tqdm==4.66.1, visdom==0.2.4, pyYAML==6.0.1, pyparsing==3.0.9, pyro-ppl==1.8.5, einops==0.6.1, timm==0.4.5, tensorboard==2.11.0, torchsummary==1.5.1,
gym==0.13.0,:OpenAI的强化学习环境模拟库。
fairseq==0.12.2:一个自然语言处理深度学习库。
apex==: NVIDIA的Pytorch组件,用于混合精度和分布式训练的库。
kornia==:PyTorch扩展库,专门用于深度学习视觉算法的实现。它提供了一系列高效的视觉变换和几何操作函数,包括仿射变换、透视变换、图像金字塔、边缘检测、特征提取等。
vector-quantize-pytorch==0.1.0:专为PyTorch设计的轻量级库,实现了VQ-VAE(Vector Quantized Variational Autoencoder)的核心算法,并扩展支持了其他向量量化技术,如Gumbel-Softmax等。
pytorch_fid:FID(Fréchet Inception Distance)是一种用于评估生成模型和真实数据分布之间差异的指标。它是由Martin Heusel等人在2017年提出的,是目前广泛使用的评估指标之一。
contrastive_learner:lucidrains/contrastive-learner
网页应用: Flask==2.3.3, Werkzeug==2.3.7, 网络爬虫: requests==2.23.0, 数据库: SQLAlchemy==2.0.23, 工具: pypinyin==0.49.0, openpyxl==3.1.2, lxml==4.9.0, json5==0.9.14
fire==:生成命令行界面的库
图像:Pillow==10.0.0, opencv-python==4.4.0.0,
桌面应用
PyQt5, pyqt5-tools, qt-applications, pyinstaller
注释:
以上是本人长期使用的版本,全都兼容,其中pyro-ppl就是pyro库,1.8.5之后的版本都不兼容pytorch1了,需要pytorch2,所以我用的1.8.4版本,1.8.5应该也可以,看官方文档1.8.5开始支持pytroch2的。
Releases · pyro-ppl/pyro (github.com)(https://github.com/pyro-ppl/pyro/releases)
批量修该文件名。
import os #导入模块 filename = './2212144sep' #文件地址 list_path = os.listdir(filename) #读取文件夹里面的名字 st = # 写入开始 for index in list_path: #list_path返回的是一个列表 通过for循环遍历提取元素 if index[:6] == "vocals": print(index) name = index.split('.')[0] #split字符串分割的方法 , 分割之后是返回的列表 索引取第一个元素[0] kid = index.split('.')[-1] #[-1] 取最后一个 path = filename + '/' + index new_path = filename + '/' + ("0000"+str(st))[-6:] + '.' + kid print("new name:", new_path) os.rename(path, new_path) #重新命名 st += 1 print('修改完成')
对pandas的列作差分
import os import pandas as pd df = pd.read_csv("annotation-time-len.CSV",'r',delimiter=',') df['act_len'] = df.iloc[:,3] # df['act_len'].diff() df['act_len']=df['act_len'].diff() df.to_csv('annotation-time-len.csv', sep=',')
用pandas吧一行行字符串转换为DataFrame
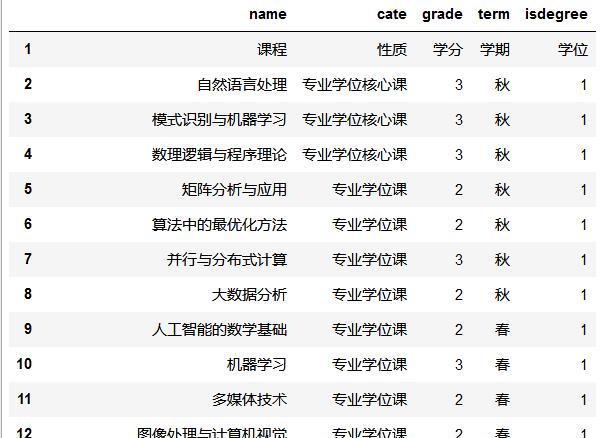
给定数据如下:
课程 性质 学分 学期 学位 自然语言处理 专业学位核心课 3 秋 1 模式识别与机器学习 专业学位核心课 3 秋 1 数理逻辑与程序理论 专业学位核心课 3 秋 1 矩阵分析与应用 专业学位课 2 秋 1 算法中的最优化方法 专业学位课 2 秋 1 并行与分布式计算 专业学位课 3 秋 1 大数据分析 专业学位课 2 秋 1 人工智能的数学基础 专业学位课 2 春 1 机器学习 专业学位课 3 春 1 多媒体技术 专业学位课 2 春 1 图像处理与计算机视觉 专业学位课 2 春 1 智能决策理论方法 专业普及课 1 春 0 科学、艺术与传播研究 公共选修课 2 春 0 视觉信息学习与分析 专业普及课 1 春 0 基础学术论文写作-01班 公共选修课 1 春 0 学术交流英语口语-01班 公共选修课 1 春 0 科学哲学英文文献选读 公共选修课 1 春 0 逻辑与批判性思维 公共选修课 1 秋 0 自然辩证法概论 公共必修课 1 秋 1 新时代中国特色社会主义理论与实践 公共必修课 2 秋 1 英语A-37班(怀) 公共必修课 3 秋 1 学术道德与学术写作规范-分论 公共必修课 0.5 秋 1 学术道德与学术写作规范-通论 公共必修课 0.5 秋 1
实际上每一行都是一个带引号的字符串,并且也不是规范的Excel,而是挤在一个单元格了,现处理成DataFrame:
import pandas as pd import numpy as np path = "./courseslist.csv" linelist = [] with open(path, 'r', encoding='gb2312') as file: line = file.readline() while line.strip() != "": print(line) linelist.append(line.strip("\"")) line = file.readline() cols = ('name', 'cate','grade','term', 'isdegree') courses_table = pd.DataFrame(columns=cols) ind = 0 for item in linelist: print(item.strip().split('\t')) tmp = pd.DataFrame(np.array(item.strip().split('\t')).reshape(1,len(cols)), columns=cols) courses_table = pd.concat([courses_table, tmp], axis=0) courses_table.index =range(1,len(courses_table)+1) # courses_table.to_csv("./courses_list_new.csv", sep=',', header=True, index=True, encoding='utf_8') courses_table
结果: