

【大数据】网页相似度-Shingling、MinHash与LSH
给定一个文档"a rose is a rose is a rose",要计算出一个特征用于做网页对比,从而和其他文档计算相似度。
Shingling
和k-gram一样,按照长度为4进行划分,得到{"a rose is a", "rose is a rose", "is a rose is", "a rose is a", "rose is a rose"},因为要得到集合,去重得到{"a rose is a", "rose is a rose", "is a rose is"}。
然后就可以对比了,通常对于两个集合计算器Jaccard系数,设文档1得到集合S1,文档2得到几何S2。则其相似度用Jaccard系数衡量:
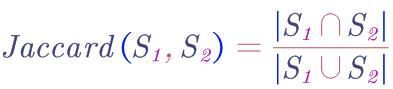
Shingling方法虽好,但是计算两个集合的交集和并集要逐一对比两个集合的Shingling,计算量极大。
MinHash
MinHash方法用来估计Jaccard系数,基本思想是“两个集合Jaccard系数"等于“两个集合MinHash值相等的概率”。
MinHash里的“Hash”函数,其实就是对文档矩阵按行重新排列,然后自上向下找出每一列中,第一次出现非零元素的行数,然后形成一个向量,又叫签名(signature)向量。
记原文档矩阵m行n列,重复执行k次这样的操作,形成一个k行n列的签名矩阵(signature matrix)。
要计算文档i 和文档j 的相似度,只需要对比signature matrix的第i列和第j列,对应相同元素的比例值就是相似度。
例如下面的案例:
import numpy as np def shuffle(A, p): new_A = [] for i in range(len(p)): new_A.append(A[p[i]-1]) return np.array(new_A) A = [ [1,0,1,0], [1,0,0,1], [0,1,0,1], [0,1,0,1], [0,1,0,1], [1,0,1,0], [1,0,1,0] ] p1 = [1,3,7,6,2,5,4] p2 = [4,2,1,3,6,7,5] p3 = [3,4,7,6,1,2,5] print('----p1----') print(shuffle(A, p1)) print('----p2----') print(shuffle(A, p2)) print('----p3----') print(shuffle(A, p3))
矩阵A按照排序p2重新排列的结果如下,其signature vector 为[2,1,3,1]
[[0 1 0 1] [1 0 0 1] [1 0 1 0] [0 1 0 1] [1 0 1 0] [1 0 1 0] [0 1 0 1]]
p1,p2,p3三次Hash操作得到的signature matrix为
[[1 2 1 2] [2 1 3 1] [3 1 3 1]]
计算相似度S(1,3)=0.667, S(2,4)=1, S(1,2)=0
LSH(Local Sensitive Hashing)
局部敏感哈希,就是把signature按行划分出n个bands,每个bands有r行,但是每次计算一个band的signature matrix,要求相似的列在band中对应相等的元素必须大于某一值才算,然后映射到不同的bucket。同一个bucket里面的文档是相似的。
Example如下:


