
使用python的requests爬取原神观测枢的内容
本文进行两个任务。
1. 爬取米游社观测枢的圣遗物信息,存到本地json文件
2. 爬取米游社观测枢的书籍信息及其超链接所链接的书籍内容,存到本地json文件
使用技术:Python的requests库和lxml库,用xpath语法解析html文档。
一、 爬取圣遗物信息
目标网址:https://bbs.mihoyo.com/ys/obc/channel/map/189/218?bbs_presentation_style=no_header
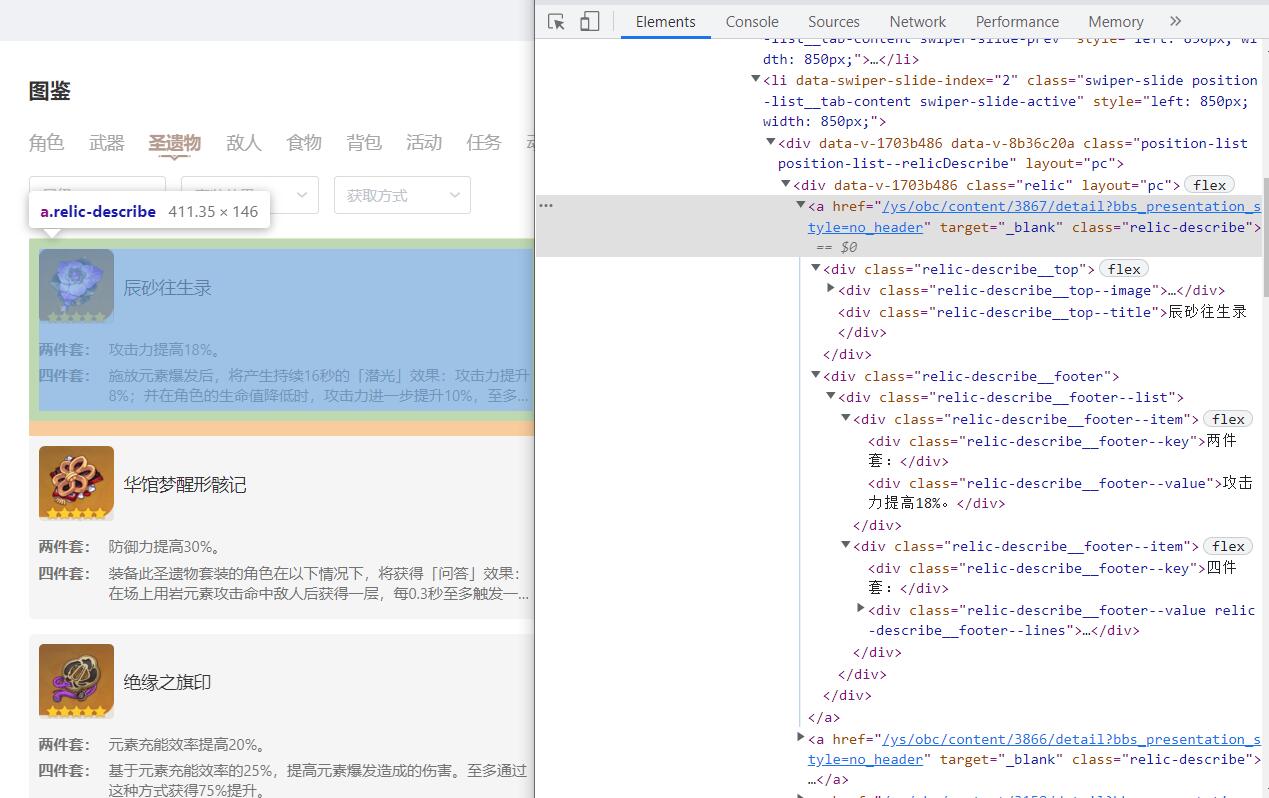
目标如图:
1. 每个圣遗物的标题都在div里面,class属性为"relic-describe__top–title"
2. 每个圣遗物的套装效果的div的class属性为"relic-describe__footer–list",其中该节点下面有两个div分别是两件套效果和四件套效果。
代码1 :获取页面的HTML文档

# -*- coding: utf-8 -*- # @Author : XX # @Time : XX import requests from lxml import etree import json import time import random # 爬虫之前千万记得先关掉系统代理 # 获取HTML文档 def getHtml(target_url): try: response = requests.get(url=target_url) response.encoding = 'utf_8' return etree.HTML(response.text) except Exception as e: print("FAIL...") print(e) exit(-1)
代码2 爬取圣遗物信息,存储形式为json文件,内容为一个列表,存放对象字典,逐行解读详见代码注释。
# lxml库,用xpath语法解析html def get_artifact_list(html): artis = [] # 圣遗物(artifact) # 对输入的页面文档解析,获取所有标题,所有class属性为xx的div标签的内容文本 names = html.xpath('//div[@class="relic-describe__top--title"]/text()') # div[1]是两件套效果,div[2]为四件套效果 # xpath语法里面,列表的下标从1开始 # 不直接获取text()文本,因为div[1]标签下面不仅有标签也有文本 piece2s = html.xpath('//div[@class="relic-describe__footer--list"]/div[1]') piece4s = html.xpath('//div[@class="relic-describe__footer--list"]/div[2]') # .xpath('string(.)')表示获取该节点下面的所有文本内容,无视下面的标签 # 例如"""<div>二件套:<div>攻击力提高18%。</div></div>"""会得到"二件套:攻击力提高18%。" # 逐个在列表里加入一个个目标对象字典, for name, piece2, piece4 in zip(names, piece2s, piece4s): artis.append({'name': name, 'piece2': piece2.xpath('string(.)'), 'piece4': piece4.xpath('string(.)')}) # 把列表写入本地json文件,使用json.dumps(obj, )写入对象 with open("artifacts.json", 'w', encoding='utf_8') as fp: # 必须令ensure_ascii=False,否则输出内容的中文的编码形式不可读,是\u的ascii形式 fp.write(json.dumps(artis, ensure_ascii=False)) print("----end----") if __name__ == '__main__': artifact_url = "https://bbs.mihoyo.com/ys/obc/channel/map/189/218?bbs_presentation_style=no_header" get_artifact_list(getHtml(artifact_url))
二、 爬取书籍
目标网址:https://bbs.mihoyo.com/ys/obc/channel/map/189/68?bbs_presentation_style=no_header
首先获取每一本书的内容的超链接。
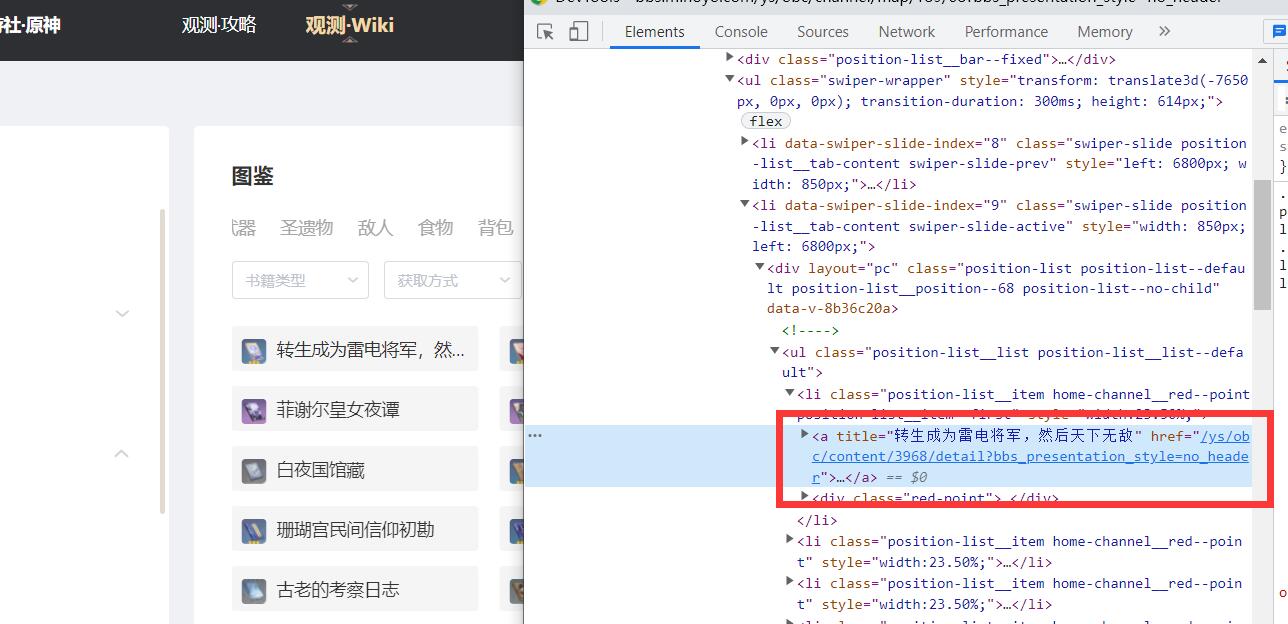
然后再获取该超链接的内容,来爬取该书籍的具体信息和内容。
进入超链接,就是书本的详细内容了。大致看一下每一个书的信息与内容所在的节点。书籍信息就是阴影部分下面两个节点中,第一个div包括 [名字、游戏内的获取方式、概述、作者],第二个div是书籍的内容。信息和内容所在div标签,在HTML文档中是并列的关系。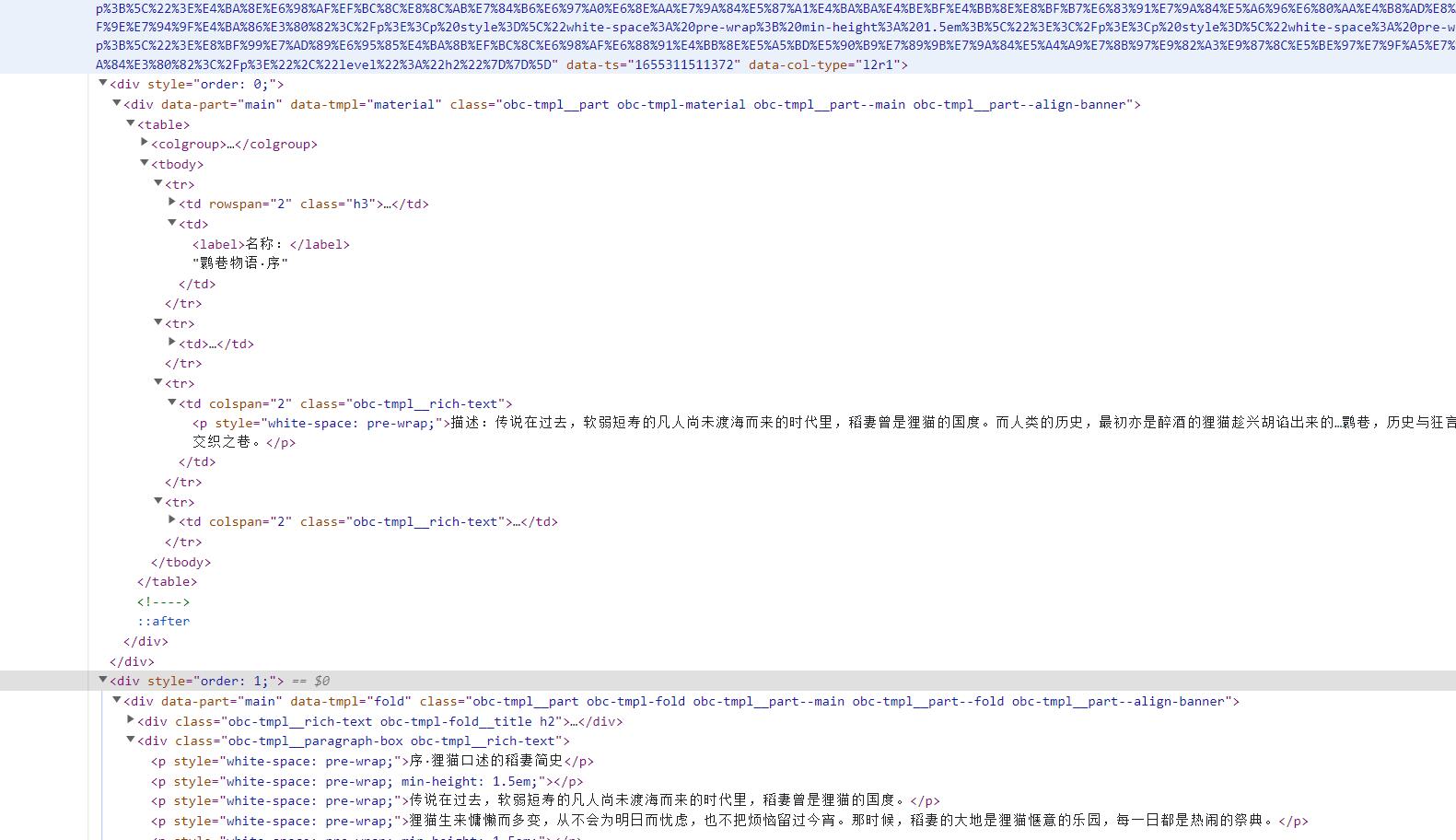
代码3 :获取某一本书的内容和信息
该函数输入某一本书的超链接,返回一个列表,返回列表而不是字典原因如上图,某一本书可能有多部,尘游记一、尘游记二、尘游记三等等。每一本书是一个字典,存【名字、获取方式、简述、作者、内容】
def get_article(target_url): article_html = getHtml(target_url) blocks = article_html.xpath('//div[@class="obc-tmpl obc-tmpl--col-l2r1"]') name_list = ['name', 'obtained', 'abstract', 'author'] data = [] res = {} for i, block in zip(range(len(blocks)), blocks): res = {} infos = block.xpath('./div[1]/div/table/tbody/tr') for j, info in zip(range(4), infos): if j == 0: # pass res[name_list[j]] = info.xpath('./td/text()') else: res[name_list[j]] = info.xpath('./td/p/text()') content = block.xpath('./div[2]/div/div[2]/p') res_str = "" for line in content: line_str = line.xpath('./text()') if len(line_str) > 0: res_str += line_str[0]+"\n" # print(res) res["content"] = res_str res["linkurl"] = target_url data.append(res) # break print('----end----') return data # 爬取每一本书 def get_book_list(html): books = [] elems = html.xpath('//ul[@class="position-list__list position-list__list--default"]')[0] # 每一本书的两个信息,书名和超链接。 book_names = elems.xpath('./li/a/span/text()') link_urls = elems.xpath('./li/a/@href') for book_name, link_url in zip(book_names, link_urls): # books.append({'bookname': book_name, 'linkurl': "https://bbs.mihoyo.com"+link_url}|) # 列表的合并用+运算符即可 books += get_article("https://bbs.mihoyo.com"+link_url) # 控制爬虫频率不要太快 print('get: ', book_name, "。停止五秒...") time.sleep(random.random()*5) # 爬虫结果写入json文件。 with open("genshin_books.json", 'w', encoding='utf_8') as fp: # 比如令ensure_ascii=False,否则输出中文的编码不正确,是\u的ascii形式 fp.write(json.dumps(books, ensure_ascii=False)) print("----end----") if __name__ == '__main__': books_url = "https://bbs.mihoyo.com/ys/obc/channel/map/189/68?bbs_presentation_style=no_header" get_book_list(getHtml(books_url))
结束


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】