
时间序列数据的定义,读取与指数平滑(Java)
应上头的要求,需要实现以下指数平滑进行资源调度负载的预测,那就是用我最喜欢的Java做一下吧。
引用《计量经济学导论》的一句话:时间序列数据区别于横截面数据的一个明显特点是,时间序列数据集是按照时间顺序排列的。
显然,横截面数据被视为随机的结果,也就是说在总体中随机抽取样本。时间序列数据和横截面数据区别较为微妙,虽然它也满足随机性,但是这个序列标有时间脚标,依照时间有序,而不可以让时间随机排列导致错乱,我们不能让时间逆转重新开始这个过程。对于这样的序列我们称之为随机过程,或者时间序列过程。
对于时间序列,经常研究的一个问题就是预测,而指数平滑法是非常常见也常用的方法之一。这里对于二次指数平滑进行Java的实现(一次指数平滑包含在二次指数平滑之内)。其原理参照: https://cloud.tencent.com/developer/article/1058557 。这里就不再赘述。
数据也是参照我国1981年至1983年度平板玻璃月产量数据,以下文件保存为data2.txt

我国1981年至1983年度平板玻璃月产量数据
1,240.3
2,222.8
3,243.1
4,222.2
5,222.6
6,218.7
7,234.5
8,248.6
9,261
10,275.3
11,269.4
12,291.2
13,301.9
14,285.5
15,286.6
16,260.5
17,298.5
18,291.8
19,267.3
20,277.9
21,303.5
22,313.3
23,327.6
24,338.3
25,340.37
26,318.51
27,336.85
28,326.64
29,342.9
30,337.53
31,320.09
32,332.17
33,344.01
34,335.79
35,350.67
36,367.37
对于以上数据,时间是int类型,而产量是double类型,为了便于读取,对于以上数据定义行数据类
package timeSeries; public class RowData { private int time; private double value; public RowData() { // TODO Auto-generated constructor stub } public RowData(int time, double value) { super(); this.time = time; this.value = value; } public int getTime() { return time; } public void setTime(int time) { this.time = time; } public double getValue() { return value; } public void setValue(double value) { this.value = value; } }
然后定义文件读取类,读取所得数据为RowData数组
package utilFile; import java.io.BufferedReader; import java.io.File; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.util.ArrayList; import timeSeries.RowData; public class FileOpts { public static ArrayList<RowData> loadTxt(String dataPath, boolean ishead) { File file = new File(dataPath); FileReader fr; ArrayList<RowData> datas = new ArrayList<RowData>(); try { fr = new FileReader(file); BufferedReader br = new BufferedReader(fr); String line = ""; String[] splitdata; if (ishead) { br.readLine(); } while ((line = br.readLine()) != null) { splitdata = line.split(","); datas.add(new RowData(Integer.parseInt(splitdata[0]), Double.parseDouble(splitdata[1]))); } br.close(); fr.close(); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } return datas; } }
然后定义时间序列分析类,其实就是一个函数
package timeSeries; import java.util.ArrayList; import java.util.Iterator; public class ExponentialSmoothing2 { public static double[][] expSmoothOrder2(int[] time, double[] values, double alpha, int preNum) { int len = time.length; // 返回一个汇总表 double[][] result = new double[len + preNum][7]; // 第一列时间,第二列实际观察值 for (int i = 0; i < len; i++) { result[i][0] = time[i]; result[i][1] = values[i]; } result[0][2] = values[0]; result[0][3] = result[0][2]; // 第三列一次指数平滑值,第四列二次指数平滑值 // S1, S2 2, 3 for (int i = 1; i < len; i++) { result[i][2] = alpha*values[i] + (1-alpha)*result[i-1][2]; result[i][3] = alpha*result[i][2] + (1-alpha)*result[i-1][3]; } // 第五列a,第六列b // a, b 4, 5 for (int i = 1; i < len; i++) { result[i][4] = 2*result[i][2] - result[i][3]; result[i][5] = alpha/(1-alpha) * (result[i][2] - result[i][3]); } // 第七列预测值F // F 6 for (int i = 1; i < len; i++) { result[i+preNum][6] = result[i][4] + result[i][5] * preNum; } return result; } public static void main(String[] args) { // 获取数据 ArrayList<RowData> data = utilFile.FileOpts.loadTxt("src/timeSeries/data2.txt", true); int len = data.size(); int[] time = new int[len]; double[] values = new double[len]; Iterator<RowData> it = data.iterator(); int index = 0; while (it.hasNext()) { RowData rowData = (RowData) it.next(); time[index] = rowData.getTime(); values[index] = rowData.getValue(); index++; } // -------------------数据准备完毕--------------- // System.out.println(Arrays.toString(time)); // System.out.println(Arrays.toString(values)); // ------------------二次指数平滑--------------------- double[][] pre2= expSmoothOrder2(time, values, 0.5, 1); System.out.printf("%6s, %6s, %6s, %6s, %6s, %6s, %6s\n", "time", "y", "s1", "s2", "a", "b", "F"); for (int i = 0; i < values.length; i++) { System.out.printf("%6.2f, %6.2f, %6.2f, %6.2f, %6.2f, %6.2f, %6.2f \n", pre2[i][0], pre2[i][1], pre2[i][2], pre2[i][3], pre2[i][4], pre2[i][5], pre2[i][6]); } // System.out.printf("%6d, %6d, %6d, %6d, %6d, %6d, %6.2f \n", 37, 0, 0, 0, 0, 0, pre2[values.length][3]); // System.out.printf("%6d, %6d, %6d, %6d, %6d, %6d, %6.2f \n", 38, 0, 0, 0, 0, 0, pre2[35][1] + pre2[35][2] * 2); // 误差分析 double MSE = 0; double MAPE = 0; double temp; // System.out.println("pre2.length = "+pre2.length); for (int i = 2; i < pre2.length-1; i++) { MSE += (pre2[i][1]-pre2[i][6])*(pre2[i][1]-pre2[i][6])/(pre2.length-2); temp = (pre2[i][1]-pre2[i][6])/pre2[i][1]; if (temp < 0) { MAPE -= temp/(pre2.length-2); }else { MAPE += temp/(pre2.length-2); } // System.out.printf("iter: %d, y = %6.2f, F = %6.2f, MSE = %6.2f, MAPE = %6.5f\n", i, pre2[i][1], pre2[i][6], MSE, MAPE); } System.out.printf("MSE = %6.2f, MAPE = %6.5f\n", MSE, MAPE); if (MAPE < 0.05) { System.out.println("百分误差小于0.05,预测精度较高"); }else { System.out.println("预测误差超过了0.05"); } } }
执行结果:
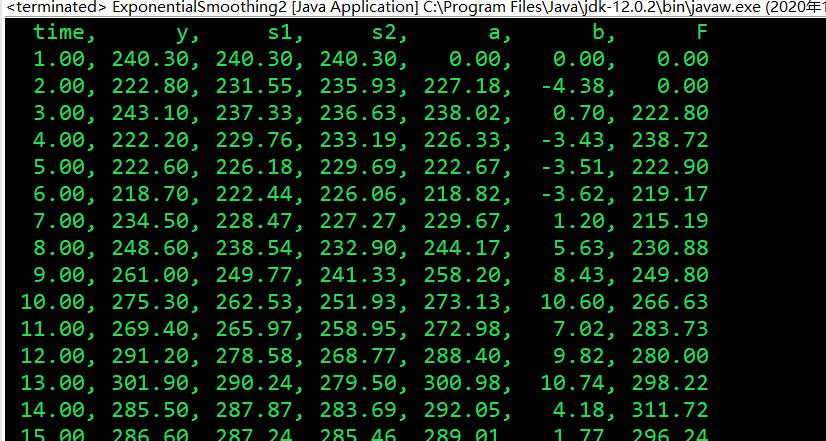
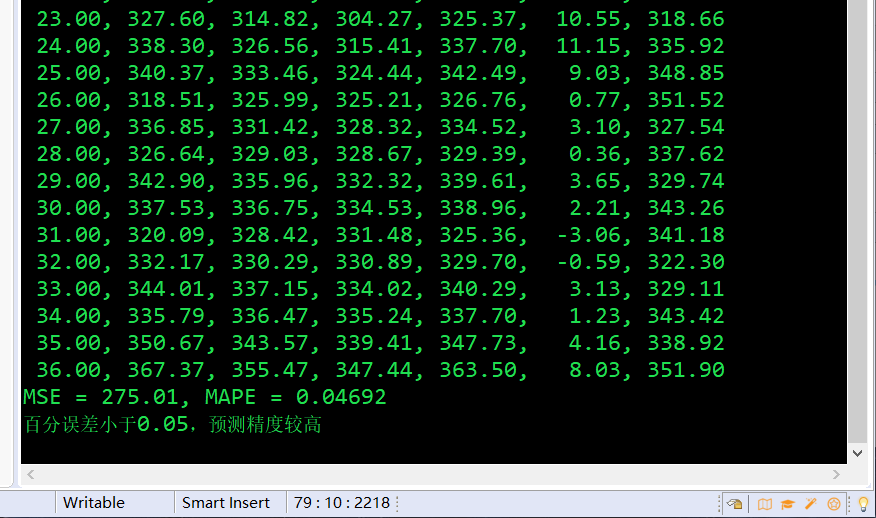
其他时间序列模型还有温特线性和季节性指数平滑法、ARIMA和GARCH等等,可见于《数学建模》或《计量经济学》。其实处理时间序列,用SPSS或R语言是很方便的,或者Matlab。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】