

【转载】细粒度图像识别Object-Part Attention Driven Discriminative Localization for Fine-grained Image Classification
细粒度图像识别Object-Part Attention Driven Discriminative Localization for Fine-grained Image Classification(OPADDL) 论文笔记
原文:"Object-Part Attention Model for Fine-grained Image Classification", IEEE Transactions on Image Processing (TIP), Vol. 27, No. 3, pp. 1487-1500, Mar. 2018.
作者:Yuxin Peng, Xiangteng He, and Junjie Zhao(北京大学)
下载地址:https://arxiv.org/abs/1704.01740 【pdf】
细粒度图像识别系列其他文章:
- Mask-CNN:http://blog.csdn.net/cyiano/article/details/71440358
- PDFS:http://blog.csdn.net/cyiano/article/details/71629754
1 简介
- 细粒度图像识别是现在图像分类中一个颇具挑战性的任务,它的目标是在一个大类中的数百数千个子类中正确识别目标。相同的子类中物体的动作姿态可能大不相同,不同的子类中物体可能又有着相同的动作姿态,这是识别的一大难点。细粒度图像分类的关键点在寻找一些存在细微差别的局部区域(比如鸟类的喙、眼睛、爪子等),因此,现有的细粒度图像识别算法不但寻找图像中的整个物体(object),还寻找一些有区别的局部(part)。


- 过去常用的生成object和part算法为Selective search,但它的召回率高,精准度低。细粒度图像识别中的寻找object和part可以视为一个两级注意力模型,一级是寻找object,另一级是寻找parts。大多数算法在训练寻找object和part的网络时都依赖于object-level attention 和 parts annotations等额外标注,这是一个非常大的劳动量。此为第一个限制。
- 虽然现在有很多人开始不用annotations来训练寻找object和part的网络,但他们的生成方法破坏了object和parts之间的关联性,这就导致生成的parts包含大量背景,且parts之间互相重叠严重。此为第二个限制。
- 为了解决上述两个限制,作者提出了object-part attention driven discriminative localization(OPADDL)方法。它在生成object和part方面使用了两个模型:
- Object-Part Attention Model:该模型可以不利用人工annotaions信息来生成object和parts。它的注意力分为两级:Object级注意力模型利用CNN中的全局平均池化提取saliency map,以定位物体在图中的位置;Part级注意力模型首先选出有区别的部分,然后再把它们根据神经网络中的 cluster pattern 排列起来,以学习局部特征。将两级模型连接起来,就可以增强multi-view and multi-scale的特征学习。
- Object-Part Spatial Constraint Model:该模型同样分为两个约束:Object级空间约束强行让选择出来的parts定位到object区域中;Part级空间约束减少parts中的重叠,且强调parts的显著性,这样可以消除重复且提高parts的区分性。两种空间约束联合起来,不仅可以发现更多显著的局部细节,还可以大大提高细粒度图像分类的准确率。
- 最后强调一下,作者使用的弱监督方法,即训练和测试时不用任何annotations!
2 相关工作
- 本章就不详细展开了,有兴趣的读者可以看看原文。提一下,现有的细粒度图像识别方法可以分成三类:Ensemble of Networks Based Methods、Visual Attention Based Methods、Part Detection Based Method。
3 OPADDL模型
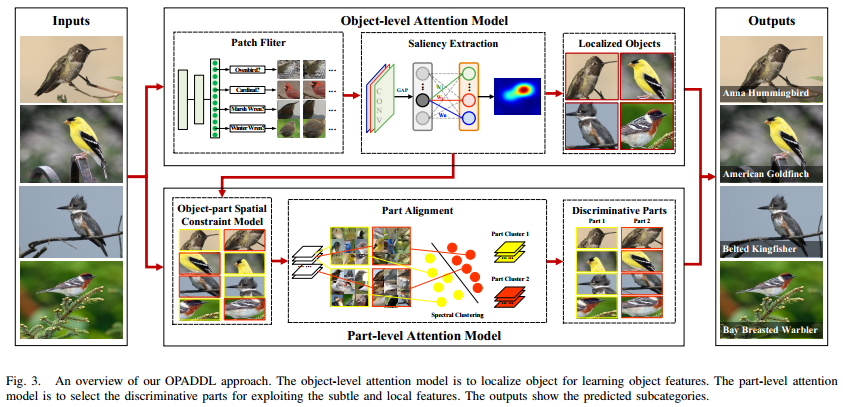
- OPADDL模型的全部结构正如上图所呈示,咋一看模型十分复杂,接下来我们把模型进行拆分,一块一块地说明。
A. Object-level Attention Model
- 现有的很多弱监督模型着重于提取parts,而忽略了object的定位,事先提取object是可以除去很多背景噪声的。作者使用saliency extraction方法来自动定位object,其中分为两个内容:Patch Filter滤掉一张图中的背景patch,保留和object有关的patch来训练一个CNN网络ClassNet;Saliency Extraction通过全局平均池化(GAP)提取saliency map,完成object的定位。整个网络称为ObjectNet。
- Patch Filter:对于一张图,作者先用传统的selective search生成一堆patch,再用一个事先在ImageNet上预训练好的CNN(作者称之为FilterNet)进一步筛掉更多的背景patch。筛选的准则就是设置一个阈值,CNN的softmax层的输出(根据标签)高于阈值才保留。注意这个patch filter只在训练阶段使用,测试时就直接上ClassNet了。
- Saliency Extraction:Saliency map表明有在CNN子类别识别中做出贡献的区域(Fig.4第二行)。上一步用patch filter筛出一些包含pbject的patch后,用CAM来生成子类别c的saliency map 接着根据saliency map就可以生成定位框(Fig.4第三行)。具体生成M的公式如下:


B. Part-level Attention Model
和上面对应,B小节整个网络统称为“PartNet”。
Object-Part Spatial Constraint Model
- 本小节说的是object和part两个级别的空间约束。上面已经提到过了,没有object空间约束会使提取的parts包含大量背景,而没有parts空间约束会使提取的parts大量重叠,有些关键part被忽略。
- 给定一张图像,它的saliency map 和object边缘已经从小节A中获得。接下来以表示selective search生成的所有patch集合,代表选出来的n个parts。整个约束要做的事情就是实现如下最大值优化:

- 表示object的空间约束。具体定义如下图。从定义可以看出,该约束就是为了鼓励parts和object尽可能重叠,IOU过阈值的个数越多,分数越高。
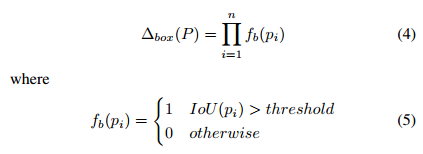
- 表示parts空间约束。既然saliency map可以表现出图像有区别的地方,作者就将saliency和parts的空间关系联合起来定义约束:


Part Alignment
- 通过上面约束模型求解出来的n个patch是无序的,在这一节里面将把它们按语义分类好(哪些是头,哪些是脚等等)。按语义分类的主要依据是CNN倒数第二层输出不同通道的响应区别,有些通道可能对头部有明显响应,有些则对脚有明显相应。
- 首先计算两个神经元的相似矩阵,接着用谱聚类把神经元分成m个簇。具体的操作步骤如下:
- 改变patch的尺寸,让它传播到网络倒数第二层时只有1*1大小(单值);
- 前向传播patch,每个通道都得到一个分数;
- 每个簇内的通道值相加得到簇的分数(共m个分数);
- 一个patch哪个簇分数最高,就把这个patch归到哪一类去,最后这些patch就能按语义被分成几类簇。整个算法如下描述:

C. Final Prediction
- 上面出现了许多网络,现在总结一下。ClassNet关注的是原始图像,ObjectNet关注的是目标object,PartNet关注的是局部parts。ObjectNet里面还有FilterNet。
- Object-level注意模型首先利用FilterNet生成与object相关的patch,这些patch又推动ClassNet更好地学习特征和目标定位。part-level注意模型选择出合适的局部信息。
- 最后的得分方式是:
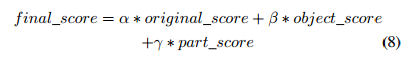
三个分数分别代表了ClassNet、ObjectNet、PartNet的softmax值,通过交叉验证来选择,以使final_score最高。
4 实验
数据集
- 文章中使用了三个常用细粒度图像数据集:CUB-200-2011(鸟类)、Cars-196(汽车)和Oxford-IIIT Pet(猫狗等宠物)。评价标准很简单,正确识别数除以总数。
网络细节
- 定位和分类网络都用VGGNET作为原型。定位网络中,VGG的conv5-3被移除,并且替换成3*3卷积核,1 padding,1024通道的卷积层,后面跟着GAP和softmax。修正后的VGGNET在ImageNet上预训练好。
- 分类网络还加上了batch normalization。由于要识别原始图像、object和parts三块,每个都用相同的CNN结构,只是训练数据不同。
分类结果
- CUB-200-2011上85.83%;Cars-196上92.19%;Oxford-IIIT Pet上93.81%。三个都是当前最高。
原文链接:https://blog.csdn.net/Cyiano/article/details/72081855
论文代码链接:https://github.com/PKU-ICST-MIPL/OPAM_TIP2018
转载别人对自己论文的笔记的滋味真是复杂啊。。
标签:
计算机视觉


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!