


大数据Spark+Kafka实时数据分析案例
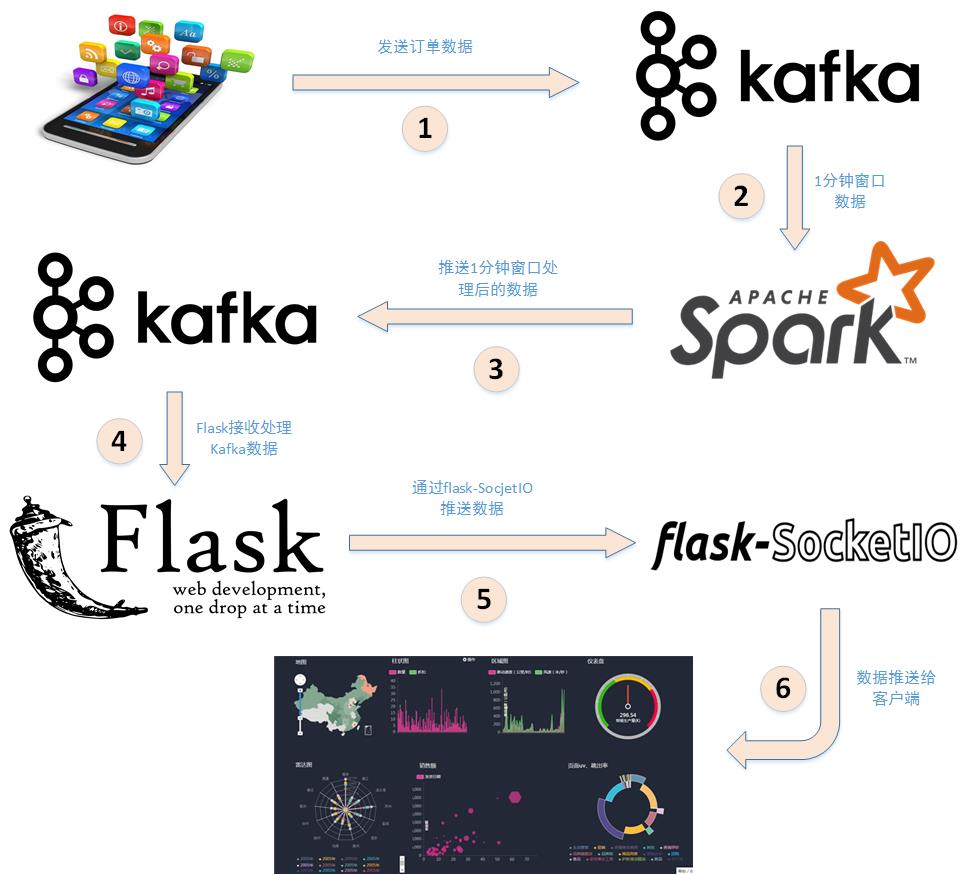
下面分析详细分析下上述步骤:
- 应用程序将购物日志发送给Kafka,topic为”sex”,因为这里只是统计购物男女生人数,所以只需要发送购物日志中性别属性即可。这里采用模拟的方式发送购物日志,即读取购物日志数据,每间隔相同的时间发送给Kafka。
- 接着利用Spark Streaming从Kafka主题”sex”读取并处理消息。这里按滑动窗口的大小按顺序读取数据,例如可以按每5秒作为窗口大小读取一次数据,然后再处理数据。
- Spark将处理后的数据发送给Kafka,topic为”result”。
- 然后利用Flask搭建一个web应用程序,接收Kafka主题为”result”的消息。
- 利用Flask-SocketIO将数据实时推送给客户端。
- 客户端浏览器利用js框架socketio实时接收数据,然后利用js可视化库hightlights.js库动态展示。
至此,本案例的整体架构已介绍完毕。
一、实验环境准备
实验系统和软件要求
Ubuntu: 16.04
Spark: 2.1.0
Scala: 2.11.8
kafka: 0.8.2.2
Python: 3.x(3.0以上版本)
Flask: 0.12.1
Flask-SocketIO: 2.8.6
kafka-python: 1.3.3
系统和软件的安装
Spark安装(前续文档已经安装)
Kafka安装
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。下面介绍有关Kafka的简单安装和使用, 简单介绍参考KAFKA简介, 想全面了解Kafka,请访问Kafka的官方博客。
我选择的是kafka_2.11-0.10.1.0.tgz(注意,此处版本号,在后面spark使用时是有要求的,见集成指南)版本。
sudo tar -zxf kafka_2.11-0.10.1.0.tgz -C /usr/local
cd /usr/local
sudo mv kafka_2.11-0.10.1.0/ ./kafka
sudo chown -R hadoop ./kafka接下来在Ubuntu系统环境下测试简单的实例。Mac系统请自己按照安装的位置,切换到相应的指令。按顺序执行如下命令:
cd /usr/local/kafka # 进入kafka所在的目录
bin/zookeeper-server-start.sh config/zookeeper.properties命令执行后不会返回Shell命令输入状态,zookeeper就会按照默认的配置文件启动服务,请千万不要关闭当前终端.启动新的终端,输入如下命令:
cd /usr/local/kafka
bin/kafka-server-start.sh config/server.propertieskafka服务端就启动了,请千万不要关闭当前终端。启动另外一个终端,输入如下命令:
cd /usr/local/kafka
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic dblabtopic是发布消息发布的category,以单节点的配置创建了一个叫dblab的topic.可以用list列出所有创建的topics,来查看刚才创建的主题是否存在。
bin/kafka-topics.sh --list --zookeeper localhost:2181 可以在结果中查看到dblab这个topic存在。接下来用producer生产点数据:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic dblab并尝试输入如下信息:
hello hadoop
hello xmu
hadoop world然后再次开启新的终端或者直接按CTRL+C退出。然后使用consumer来接收数据,输入如下命令:
cd /usr/local/kafka
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic dblab --from-beginning 便可以看到刚才产生的三条信息。说明kafka安装成功。
Python安装
Ubuntu16.04系统自带Python2.7和Python3.5,本案例直接使用Ubuntu16.04自带Python3.5;
Python依赖库
案例主要使用了两个Python库,Flask和Flask-SocketIO,这两个库的安装非常简单,请启动进入Ubuntu系统,打开一个命令行终端。
Python之所以强大,其中一个原因是其丰富的第三方库。pip则是python第三方库的包管理工具。Python3对应的包管理工具是pip3。因此,需要首先在Ubuntu系统中安装pip3,命令如下:
sudo apt-get install python3-pip安装完pip3以后,可以使用如下Shell命令完成Flask和Flask-SocketIO这两个Python第三方库的安装以及与Kafka相关的Python库的安装:
pip3 install flask
pip3 install flask-socketio
pip3 install kafka-python这些安装好的库在我们的程序文件的开头可以直接用来引用。比如下面的例子。
from flask import Flask
from flask_socketio import SocketIO
from kafka import KafkaConsumerfrom import 跟直接import的区别举个例子来说明。
import socket的话,要用socket.AF_INET,因为AF_INET这个值在socket的名称空间下。
from socket import* 是把socket下的所有名字引入当前名称空间。
二、数据处理和Python操作Kafka
本案例采用的数据集压缩包为data_format.zip点击这里下载data_format.zip数据集,该数据集压缩包是淘宝2015年双11前6个月(包含双11)的交易数据(交易数据有偏移,但是不影响实验的结果),里面包含3个文件,分别是用户行为日志文件user_log.csv 、回头客训练集train.csv 、回头客测试集test.csv. 在这个案例中只是用user_log.csv这个文件,下面列出文件user_log.csv的数据格式定义:
用户行为日志user_log.csv,日志中的字段定义如下:
- user_id | 买家id
- item_id | 商品id
- cat_id | 商品类别id
- merchant_id | 卖家id
- brand_id | 品牌id
- month | 交易时间:月
- day | 交易事件:日
- action | 行为,取值范围{0,1,2,3},0表示点击,1表示加入购物车,2表示购买,3表示关注商品
- age_range | 买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
- gender | 性别:0表示女性,1表示男性,2和NULL表示未知
- province| 收获地址省份
数据具体格式如下:
user_id,item_id,cat_id,merchant_id,brand_id,month,day,action,age_range,gender,province
328862,323294,833,2882,2661,08,29,0,0,1,内蒙古
328862,844400,1271,2882,2661,08,29,0,1,1,山西
328862,575153,1271,2882,2661,08,29,0,2,1,山西
328862,996875,1271,2882,2661,08,29,0,1,1,内蒙古
328862,1086186,1271,1253,1049,08,29,0,0,2,浙江
这个案例实时统计每秒中男女生购物人数,因此针对每条购物日志,我们只需要获取gender即可,然后发送给Kafka,接下来Spark Streaming再接收gender进行处理。
数据预处理
接着可以写如下Python代码,文件名为producer.py:(具体的工程文件结构参照步骤一)
mkdir -p ~/kafka-exp/scripts
cd ~/kafka-exp/scripts
vim producer.py添加如入内容:
# coding: utf-8
import csv
import time
from kafka import KafkaProducer
# 实例化一个KafkaProducer示例,用于向Kafka投递消息
producer = KafkaProducer(bootstrap_servers='localhost:9092')
# 打开数据文件
csvfile = open("../data/user_log.csv","r")
# 生成一个可用于读取csv文件的reader
reader = csv.reader(csvfile)
for line in reader:
gender = line[9] # 性别在每行日志代码的第9个元素
if gender == 'gender':
continue # 去除第一行表头
time.sleep(0.1) # 每隔0.1秒发送一行数据
# 发送数据,topic为'sex'
producer.send('sex',line[9].encode('utf8'))上述代码很简单,首先是先实例化一个Kafka生产者。然后读取用户日志文件,每次读取一行,接着每隔0.1秒发送给Kafka,这样1秒发送10条购物日志。这里发送给Kafka的topic为’sex’。
Python操作Kafka
我们可以写一个KafkaConsumer测试数据是否投递成功,代码如下,文件名为consumer.py
from kafka import KafkaConsumer
consumer = KafkaConsumer('sex')
for msg in consumer:
print((msg.value).decode('utf8'))在开启上述KafkaProducer和KafkaConsumer之前,需要先开启Kafka。然后再开两个终端,分别用作发布消息与消费消息,执行命令如下:
cd ~/kafka-exp/scripts
python3 producer.py #启动生产者发送消息给Kafaka打开另外一个命令行 终端窗口,消费消息,执行如下命令:
cd ~/kafka-exp/scripts
python3 consumer.py #启动消费者从Kafaka接收消息运行上面这条命令以后,这时,你会看到屏幕上会输出一行又一行的数字,类似下面的样子:
2
1
1
1
.......三、Spark Streaming实时处理数据
本案例在于实时统计每秒中男女生购物人数,而Spark Streaming接收的数据为1,1,0,2…,其中0代表女性,1代表男性,所以对于2或者null值,则不考虑。其实通过分析,可以发现这个就是典型的wordcount问题,而且是基于Spark流计算。女生的数量,即为0的个数,男生的数量,即为1的个数。
因此利用Spark Streaming接口reduceByKeyAndWindow,设置窗口大小为1,滑动步长为1,这样统计出的0和1的个数即为每秒男生女生的人数。
Spark准备工作
Kafka和Flume等高级输入源,需要依赖独立的库(jar文件)。按照我们前面安装好的Spark版本,这些jar包都不在里面,为了证明这一点,我们现在可以测试一下。请打开一个新的终端,然后启动spark-shell:
cd /usr/local/spark/spark-2.3.0-bin-hadoop2.7
./bin/spark-shell启动成功后,在spark-shell中执行下面import语句:
scala> import org.apache.spark.streaming.kafka010._
<console>:25: error: object kafka is not a member of package org.apache.spark.streaming
import org.apache.spark.streaming.kafka010._
^你可以看到,马上会报错,因为找不到相关的jar包。然后我们退出spark-shell。
根据Spark官网的说明,对于Spark2.3.0版本,如果要使用Kafka,则需要下载spark-streaming-kafka-0-10_2.11相关jar包。
现在请在Linux系统中,打开一个火狐浏览器,请点击这里访问Spark官网,里面有提供spark-streaming-kafka-0-10_2.11-2.3.0.jar文件的下载,其中,2.11表示scala的版本,2.3.0表示Spark版本号。下载后的文件会被默认保存在当前Linux登录用户的下载目录下,本教程统一使用hadoop用户名登录Linux系统,所以,我们就把这个文件复制到Spark目录的jars目录下。请新打开一个终端,输入下面命令:
mkdir /usr/local/spark/spark-2.3.0-bin-hadoop2.7/jars/kafka
cp ./spark-streaming-kafka-0-10_2.11-2.3.0.jar /usr/local/spark/spark-2.3.0-bin-hadoop2.7/jars/kafka下面还要继续把Kafka安装目录的libs目录下的所有jar文件复制到“/usr/local/spark/jars/kafka”目录下,请在终端中执行下面命令:
cd /usr/local/kafka/libs
ls
cp ./* /usr/local/spark/spark-2.3.0-bin-hadoop2.7/jars/kafka建立Spark项目
之前有很多教程都有说明如何创建Spark项目,这里再次说明。首先在/usr/local/spark/mycode新建项目主目录kafka,然后在kafka目录下新建scala文件存放目录以及scala工程文件
mkdir -p /usr/local/spark/mycode/kafka/src/main/scala接着在src/main/scala文件下创建两个文件,一个是用于设置日志,一个是项目工程主文件,设置日志文件为StreamingExamples.scala
package org.apache.spark.examples.streaming
import org.apache.spark.internal.Logging
import org.apache.log4j.{Level, Logger}
/** Utility functions for Spark Streaming examples. */
object StreamingExamples extends Logging {
/** Set reasonable logging levels for streaming if the user has not configured log4j. */
def setStreamingLogLevels() {
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if (!log4jInitialized) {
// We first log something to initialize Spark's default logging, then we override the
// logging level.
logInfo("Setting log level to [WARN] for streaming example." +
" To override add a custom log4j.properties to the classpath.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}这个文件不做过多解释,因为这只是一个辅助文件,下面着重介绍工程主文件,文件名为KafkaTest.scala
package org.apache.spark.examples.streaming
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.json4s._
import org.json4s.jackson.Serialization
import org.json4s.jackson.Serialization.write
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.Interval
import org.apache.spark.streaming.kafka010._
object KafkaWordCount {
implicit val formats = DefaultFormats//数据格式化时需要
def main(args: Array[String]): Unit={
if (args.length < 3) {
System.err.println("Usage: KafkaWordCount <brokers> <groupId> <topics>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val Array(brokers, groupId, topics) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
ssc.checkpoint("checkpoint")
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
// Get the lines, split them into words, count the words and print
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))//将输入的每行用空格分割成一个个word
// 对每一秒的输入数据进行reduce,然后将reduce后的数据发送给Kafka
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_+_,_-_, Seconds(1), Seconds(1), 1).foreachRDD(rdd => {
if(rdd.count !=0 ){
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092")
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
// 实例化一个Kafka生产者
val producer = new KafkaProducer[String, String](props)
// rdd.colect即将rdd中数据转化为数组,然后write函数将rdd内容转化为json格式
val str = write(rdd.collect)
// 封装成Kafka消息,topic为"result"
val message = new ProducerRecord[String, String]("result", null, str)
// 给Kafka发送消息
producer.send(message)
}
})
ssc.start()
ssc.awaitTermination()
}
}上述代码注释已经也很清楚了,下面在简要说明下:
- 首先按每秒的频率读取Kafka消息;
- 然后对每秒的数据执行wordcount算法,统计出0的个数,1的个数,2的个数;
- 最后将上述结果封装成json发送给Kafka。
另外,需要注意,上面代码中有一行如下代码:
ssc.checkpoint(".") 这行代码表示把检查点文件写入分布式文件系统HDFS,所以一定要事先启动Hadoop。如果没有启动Hadoop,则后面运行时会出现“拒绝连接”的错误提示。如果你还没有启动Hadoop,则可以现在在Ubuntu终端中,使用如下Shell命令启动Hadoop:
cd /usr/local/hadoop #这是hadoop的安装目录
./sbin/start-dfs.sh另外,如果不想把检查点写入HDFS,而是直接把检查点写入本地磁盘文件(这样就不用启动Hadoop),则可以对ssc.checkpoint()方法中的文件路径进行指定,比如下面这个例子:
ssc.checkpoint("file:///usr/local/spark/mycode/kafka/checkpoint")checkpoint的意思就是建立检查点,类似于快照,例如在spark计算里面 计算流程DAG特别长,服务器需要将整个DAG计算完成得出结果,但是如果在这很长的计算流程中突然中间算出的数据丢失了,spark又会根据RDD的依赖关系从头到尾计算一遍,这样子就很费性能,当然我们可以将中间的计算结果通过cache或者persist放到内存或者磁盘中,但是这样也不能保证数据完全不会丢失,存储的这个内存出问题了或者磁盘坏了,也会导致spark从头再根据RDD计算一遍,所以就有了checkpoint,其中checkpoint的作用就是将DAG中比较重要的中间数据做一个检查点将结果存储到一个高可用的地方(通常这个地方就是HDFS里面)
运行项目
编写好程序之后,下面介绍下如何打包运行程序。在/usr/local/spark/mycode/kafka目录下新建文件simple.sbt,输入如下内容:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.3.0"
libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.3.0"
libraryDependencies += "org.apache.spark" % "spark-streaming-kafka-0-10_2.11" % "2.3.0"
libraryDependencies += "org.json4s" %% "json4s-jackson" % "3.2.11"然后,即可编译打包程序,输入如下命令
/usr/local/sbt/sbt package打包成功之后,接下来编写运行脚本,在/usr/local/spark/mycode/kafka目录下新建startup.sh文件,输入如下内容:
/usr/local/spark/spark-2.3.0-bin-hadoop2.7/bin/spark-submit --driver-class-path /usr/local/spark/spark-2.3.0-bin-hadoop2.7/jars/*:/usr/local/spark/spark-2.3.0-bin-hadoop2.7/jars/kafka/* --class "org.apache.spark.examples.streaming.KafkaWordCount" /usr/local/spark/mycode/kafka/target/scala-2.11/simple-project_2.11-1.0.jar 127.0.0.1:9092 1 sex 其中最后四个为输入参数,含义如下
- 127.0.0.1:9092为brokerer地址
- 1 为consumer group标签
- sex为消费者接收的topic
最后在/usr/local/spark/mycode/kafka目录下,运行如下命令即可执行刚编写好的Spark Streaming程序
sh startup.sh程序运行成功之后,下面通过之前的KafkaProducer和KafkaConsumer来检测程序。
测试程序
下面开启之前编写的KafkaProducer投递消息,然后将KafkaConsumer中接收的topic改为result,验证是否能接收topic为result的消息,更改之后的KafkaConsumer为
from kafka import KafkaConsumer
consumer = KafkaConsumer('result')
for msg in consumer:
print((msg.value).decode('utf8'))在同时开启Spark Streaming项目,KafkaProducer以及KafkaConsumer之后,可以在KafkaConsumer运行窗口,出现以下类似数据:
[{"0":1},{"2":3},{"1":6}]
[{"0":5},{"2":2},{"1":3}]
[{"0":3},{"2":3},{"1":4}]
.......
四、结果展示
接下来做的事是,利用Flask-SocketIO实时推送数据,socket.io.js实时获取数据,highlights.js展示数据。
Flask-SocketIO实时推送数据
将介绍如何利用Flask-SocketIO将结果实时推送到浏览器。
下载代码,用python3.5 运行 app.py即可:
python app.py