
kafka-broker-topic-replica- 保存消息
一、存储方式
一个topic 分成一个或多个 patition(对应 server.properties 中的 num.partitions=3 配置),而每一个 patition 物理上对应一个文件夹(该文件夹存储该 patition 的所有消息和索引文件)
二、存储策略
基于时间:log.retention.hours=168
基于大小:log.retention.bytes=1073741824
注:无论消息是否被消费,kafka 都会保留所有消息
三、创建和删除topic
controller 在 zookeeper 的 /brokers/ids/[brokerId] 节点注册 Watcher,当 topic 将要被创建时,controller收到信息,
创建topic:
1.读取分配信息:得到创建通知后,创建节点,会通过 watch 读取得到该 topic 的 partition/replica 分配。
2.获得可用的broker列表:controller从 /brokers/ids 读取当前所有可用的 broker 列表
3.选取leader和维护ISR: 从分配给该 partition 的所有 replica(称为AR)中任选一个可用的 broker 作为新的 leader,并将AR设置为新的 ISR
4.将新 leader、ISR、controller_epoch 和 leader_epoch 等信息写入 state 节点
5.controller 通过 RPC 向相关的 broker 发送 LeaderAndISRRequest。
创建topic的时序图: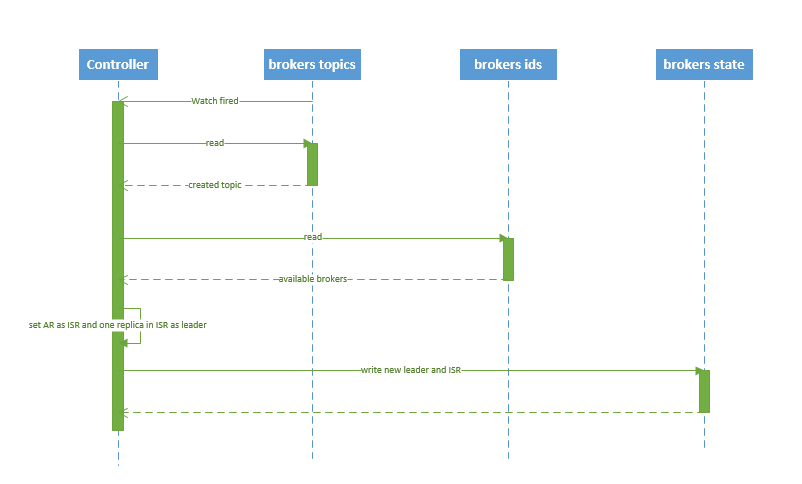
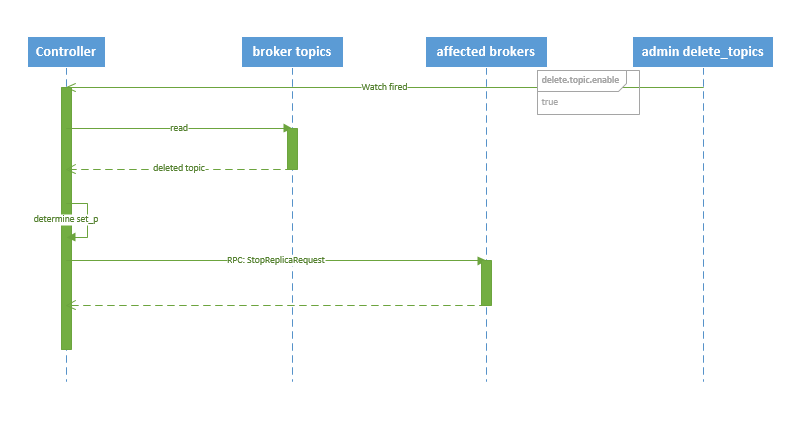
删除topic:
若配置中:delete.topic.enable=false,则结束,操作无效;否则 controller 注册在 /admin/delete_topics 上的 watch 被 fire,controller将会得到通知;
1.读取分配信息:得到通知后,删除节点,会通过 watch 读取得到该 topic 的 partition/replica 分配。
2.告知更新:controller 通过回调向对应的 broker 发送 StopReplicaRequest。
删除topic的时序图:
Kafak分配Replica的算法:
随机选取一个Broker(StartingBroker)和递增量(IncreasingShift)
开始round-robin(轮询的方式)方式分配:Partition的第一个Replica分配至StartingBroker,剩余replica以递增量(IncreasingShift)计算出所在的broker位置;
注:如果Brokers已经被轮询完一次,则IncreasingShift递增一;
所有replica都不工作时:
有两种可行的方案:
1. 等待 ISR 中的任一个 replica 活过来,并选它作为 leader。可保障数据不丢失,但时间可能相对较长。
2. 选择第一个活过来的 replica(不一定是 ISR 成员)作为 leader。无法保障数据不丢失,但相对不可用时间较短。」
注:kafka 0.8.* 使用第二种方式。
broker failover (宕机)
1. 当 broker 宕机时 zookeeper 会 fire watch,controller会收到通知;
2. controller 从 /brokers/ids 节点读取可用broker;
3. controller决定set_p,该集合包含宕机 broker 上的所有 partition
4. 对 set_p 中的每一个 partition
4.1 从/brokers/topics/[topic]/partitions/[partition]/state 节点读取 ISR
4.2 决定新 leader(如4.3节所描述)
4.3 将新 leader、ISR、controller_epoch 和 leader_epoch 等信息写入 state 节点
5. 通过 RPC 向相关 broker 发送 leaderAndISRRequest 命令
controller failover(宕机)
1.每个 broker 都会在 zookeeper 的 "/controller" 节点注册 watcher,当 controller 宕机时 zookeeper 中的临时节点消失,所有存活的 broker 收到 fire 的通知
2.每个 broker 都尝试创建新的 controller path,只有一个竞选成功并当选为 controller。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号