
kafka-分布式发布订阅消息系统-入门词汇
专业词汇:
Producer(生产者):发布消息的对象
Consumer(消费者):订阅并处理消息的对象
Consumer group(消费者组): 每个 consumer 都属于一个 consumer group
注:每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。
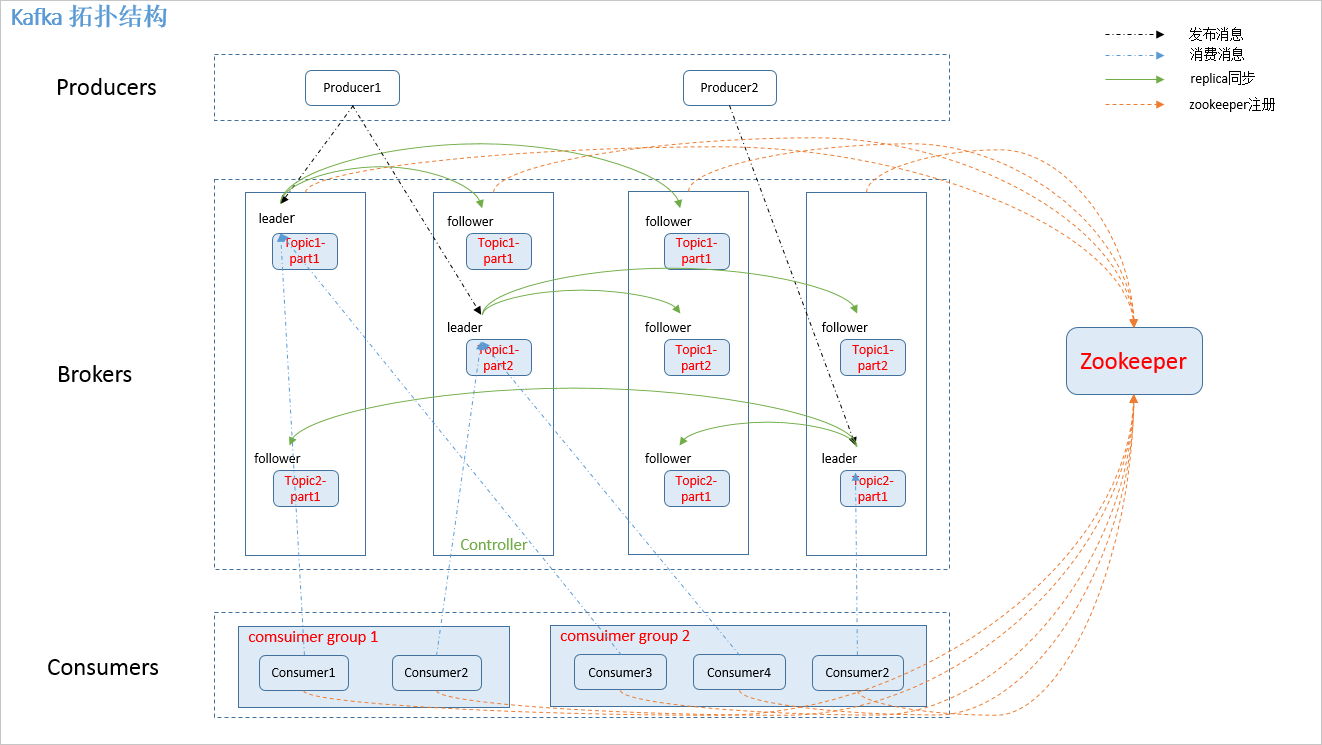
Broker(代理):kafka cluster(Kafka集群)中的每一个服务器
controller:kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover
Feed(消息种子):指代每一条消息
Topic(主题):消息的类别,指代一类消息
Partion(区):每个topic将被分成多个partition(区)---kafka 分配的单位。
replica(备份):partition 的副本,保障 partition 的高可用。
leader(主): producer 和 consumer 只跟 leader 交互。
follower(从): 从 leader 中复制数据。
注:同一个 partition 可能会有多个 replica(对应 server.properties 配置中的 default.replication.factor=N)。没有 replica 的情况下,一旦 broker 宕机,其上所有 patition 的数据都不可被消费,同时 producer 也不能再将数据存于其上的 patition。引入replication 之后,同一个 partition 可能会有多个 replica,而这时需要在这些 replica 之间选出一个 leader,producer 和 consumer 只与这个 leader 交互,其它 replica 作为 follower 从 leader 中复制数据
zookeeper:
kafka 通过 zookeeper 来存储集群的 meta 信息
深入讨论Topic机制:
每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。发布的消息都会被追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它唯一的标记一条消息。
注:kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。
扩展:
将一个topic将被分成多个partition(区)保存的原因:
最根本原因是kafka基于文件存储.通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限。.此外越多的partitions,还能有效提升消息 并发保存/消费的效率;
注:如果一个topic的名称为"my_topic",它有2个partitions,那么日志将会保存在my_topic_0和my_topic_1两个目录中;日志文件中保存了一序列"log entries"(日志条目),每个partition在物理存储层面,有多个log file组成(称为segment).segmentfile的命名为"最小offset".kafka.例如"00000000000.kafka";其中"最小offset"表示此segment中起始消息的offset.
说明:
每个log entry格式为"4个字节的数字N表示消息的长度" + "N个字节的消息内容";
每个日志都有一个offset来唯一的标记一条消息,offset的值为8个字节的数字,表示此消息在此partition中所处的起始位置.

消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号