
SpringBoot实现Mysql读写分离
前言
在高并发的场景中,关于数据库都有哪些优化的手段?
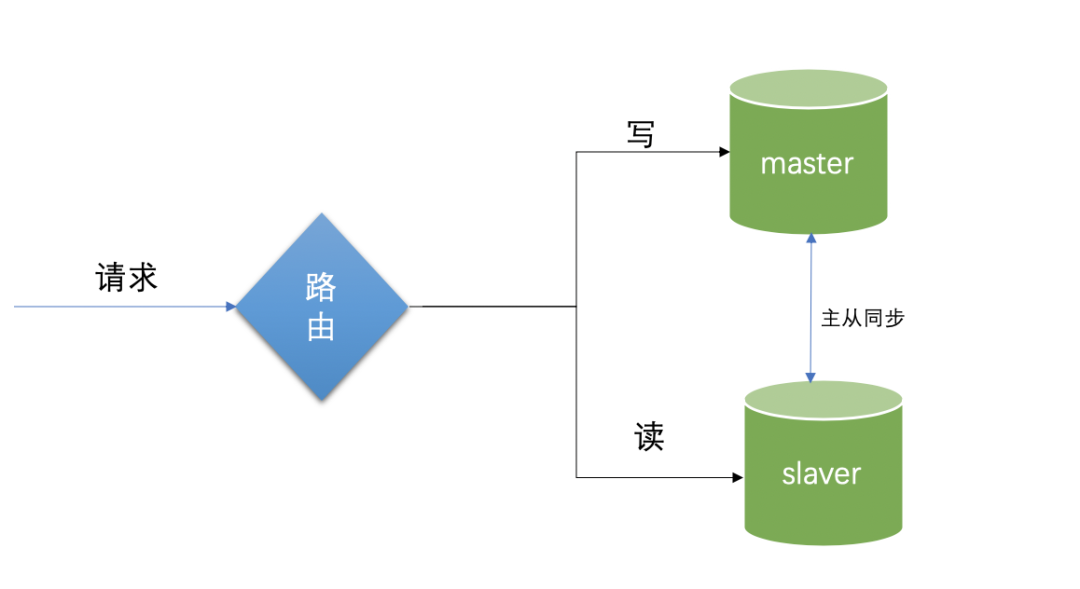
常用的有以下的实现方法:读写分离、加缓存、主从架构集群、分库分表等,在互联网应用中,大部分都是读多写少的场景,设置两个库,主库和读库。
主库的职能是负责写,从库主要是负责读,可以建立读库集群,通过读写职能在数据源上的隔离达到减少读写冲突、释压数据库负载 、保护数据库的目的。在实际的使用中,凡是涉及到写的部分直接切换到主库,读的部分直接切换到读库,这就是典型的读写分离技术。
主从同步的局限性
这里分为主数据库和从数据库,主数据库和从数据库保持数据库结构的一致,主库负责写,当写入数据的时候,会自动同步数据到从数据库;从数据库负责读,当读请求来的时候,直接从读库读取数据,主数据库会自动进行数据复制到从数据库中。不过本篇博客不介绍这部分配置的知识,因为它更偏运维工作一点。
这里涉及到一个问题:主从复制的延迟问题,当写入到主数据库的过程中,突然来了一个读请求,而此时数据还没有完全同步,就会出现读请求的数据读不到或者读出的数据比原始值少的情况。具体的解决方法最简单的就是将读请求暂时指向主库,但是同时也失去了主从分离的部分意义。也就是说在严格意义上的数据一致性场景中,读写分离并非是完全适合的,注意更新的时效性是读写分离使用的缺点。
引入依赖
<!-- SpringBoot 拦截器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<!-- 阿里数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
</dependency>
数据源配置
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
druid:
# 主库数据源
master:
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=Asia/Shanghai
username: root
password: 123456
# 从库数据源
slave:
# 从数据源开关/默认关闭
enabled: true
url: jdbc:mysql://localhost:3306/test2?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=Asia/Shanghai
username: root
password: 123456
主从数据源的配置
当前采用了阿里的 druid 数据库连接池,使用 build 建造者模式创建 DataSource 对象,DataSource 就是代码层面抽象出来的数据源。
/**
* druid 配置多数据源
*
* @author hviger
*/
@Configuration
public class DruidConfig
{
@Bean
@ConfigurationProperties("spring.datasource.druid.master")
public DataSource masterDataSource(DruidProperties druidProperties)
{
DruidDataSource dataSource = DruidDataSourceBuilder.create().build();
return druidProperties.dataSource(dataSource);
}
@Bean
@ConfigurationProperties("spring.datasource.druid.slave")
@ConditionalOnProperty(prefix = "spring.datasource.druid.slave", name = "enabled", havingValue = "true")
public DataSource slaveDataSource(DruidProperties druidProperties)
{
DruidDataSource dataSource = DruidDataSourceBuilder.create().build();
return druidProperties.dataSource(dataSource);
}
@Bean(name = "dynamicDataSource")
@Primary
public DynamicDataSource dataSource(DataSource masterDataSource)
{
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceType.MASTER.name(), masterDataSource);
setDataSource(targetDataSources, DataSourceType.SLAVE.name(), "slaveDataSource");
return new DynamicDataSource(masterDataSource, targetDataSources);
}
/**
* 设置数据源
*
* @param targetDataSources 备选数据源集合
* @param sourceName 数据源名称
* @param beanName bean名称
*/
public void setDataSource(Map<Object, Object> targetDataSources, String sourceName, String beanName)
{
try
{
DataSource dataSource = SpringUtils.getBean(beanName);
targetDataSources.put(sourceName, dataSource);
}
catch (Exception e)
{
}
}
}
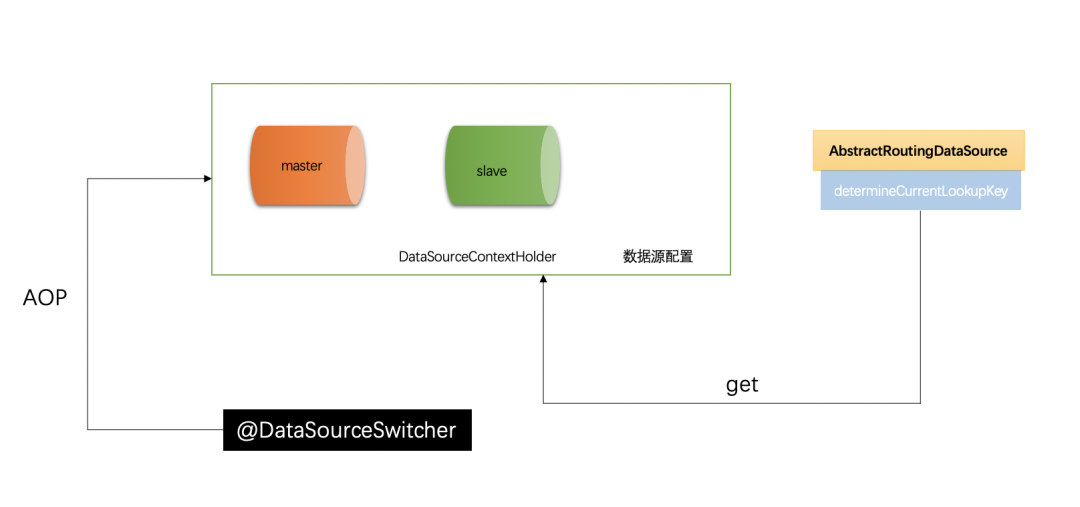
数据源路由的配置
路由在主从分离是非常重要的,基本是读写切换的核心。Spring 提供了 AbstractRoutingDataSource 根据用户定义的规则选择当前的数据源,作用就是在执行查询之前,设置使用的数据源,实现动态路由的数据源,在每次数据库查询操作前执行它的抽象方法 determineCurrentLookupKey() 决定使用哪个数据源。
为了能有一个全局的数据源管理器,此时我们需要引入 DataSourceContextHolder 这个数据库上下文管理器,可以理解为全局的变量,随时可取(见下面详细介绍),它的主要作用就是保存当前的数据源;
/**
* 动态数据源
*
* @author hviger
*/
public class DynamicDataSource extends AbstractRoutingDataSource
{
public DynamicDataSource(DataSource defaultTargetDataSource, Map<Object, Object> targetDataSources)
{
super.setDefaultTargetDataSource(defaultTargetDataSource);
super.setTargetDataSources(targetDataSources);
super.afterPropertiesSet();
}
@Override
protected Object determineCurrentLookupKey()
{
return DataSourceContextHolder.getDataSourceType();
}
}
数据源上下文环境
数据源上下文保存器,便于程序中可以随时取到当前的数据源,它主要利用 ThreadLocal 封装,因为 ThreadLocal 是线程隔离的,天然具有线程安全的优势。这里暴露了 set 和 get、clear 方法,set 方法用于赋值当前的数据源名,get 方法用于获取当前的数据源名称,clear 方法用于清除 ThreadLocal 中的内容,因为 ThreadLocal 的 key 是 weakReference 是有内存泄漏风险的,通过 remove 方法防止内存泄漏;
/**
* 数据源切换处理
*
* @author hviger
*/
public class DataSourceContextHolder
{
public static final Logger log = LoggerFactory.getLogger(DataSourceContextHolder.class);
/**
* 使用ThreadLocal维护变量,ThreadLocal为每个使用该变量的线程提供独立的变量副本,
* 所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
*/
private static final ThreadLocal<String> CONTEXT_HOLDER = new ThreadLocal<>();
/**
* 设置数据源的变量
*/
public static void setDataSourceType(String dsType)
{
log.info("切换到{}数据源", dsType);
CONTEXT_HOLDER.set(dsType);
}
/**
* 获得数据源的变量
*/
public static String getDataSourceType()
{
return CONTEXT_HOLDER.get();
}
/**
* 清空数据源变量
*/
public static void clearDataSourceType()
{
CONTEXT_HOLDER.remove();
}
}
定义切换注解
定义一个@DataSourceSwitcher 注解,拥有一个属性:指当前的数据源,并且只能放在方法上,(不可以放在类上,也没必要放在类上,因为我们在进行数据源切换的时候肯定是方法操作),该注解的主要作用就是进行数据源的切换,在 dao 层进行操作数据库的时候,可以在方法上注明表示的是当前使用哪个数据源;
/**
* 自定义多数据源切换注解
*
* 优先级:先方法,后类,如果方法覆盖了类上的数据源类型,以方法的为准,否则以类上的为准
*
* @author hviger
*/
@Target({ ElementType.METHOD, ElementType.TYPE })
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface DataSourceSwitcher
{
/**
* 切换数据源名称
*/
public DataSourceType value() default DataSourceType.MASTER;
}
/**
* 数据源
*
* @author hviger
*/
public enum DataSourceType
{
/**
* 主库
*/
MASTER,
/**
* 从库
*/
SLAVE
}
DataSourceAop 配置
为了赋予@DataSourceSwitcher 注解能够切换数据源的能力,我们需要使用 AOP,然后使用@Aroud 注解找到方法上有@DataSourceSwitcher.class 的方法,然后取注解上配置的数据源的值,设置到 DynamicDataSourceContextHolder 中,就实现了将当前方法上配置的数据源注入到全局作用域当中;
/**
* 多数据源处理
*
* @author hviger
*/
@Aspect
@Order(1)
@Component
public class DataSourceContextAop
{
protected Logger logger = LoggerFactory.getLogger(getClass());
@Pointcut("@annotation(com.cn.common.annotation.DataSourceSwitcher)"
+ "|| @within(com.cn.common.annotation.DataSourceSwitcher)")
public void dsPointCut()
{
}
@Around("dsPointCut()")
public Object around(ProceedingJoinPoint point) throws Throwable
{
DataSourceSwitcher dataSource = getDataSource(point);
if (StringUtils.isNotNull(dataSource))
{
DataSourceContextHolder.setDataSourceType(dataSource.value().name());
}
try
{
return point.proceed();
}
finally
{
// 销毁数据源 在执行方法之后
DataSourceContextHolder.clearDataSourceType();
}
}
/**
* 获取需要切换的数据源
*/
public DataSourceSwitcher getDataSource(ProceedingJoinPoint point)
{
MethodSignature signature = (MethodSignature) point.getSignature();
DataSourceSwitcher dataSource = AnnotationUtils.findAnnotation(signature.getMethod(), DataSourceSwitcher.class);
if (Objects.nonNull(dataSource))
{
return dataSource;
}
return AnnotationUtils.findAnnotation(signature.getDeclaringType(), DataSourceSwitcher.class);
}
}
修改启动类
exclude,排除此类的AutoConfig,即禁止 SpringBoot 自动注入数据源配置。
DataSourceAutoConfiguration.class 会自动查找 application.yml 或者 properties 文件里的 spring.datasource.* 相关属性并自动配置单数据源「注意这里提到的单数据源」。
因为DataSourceAutoConfiguration.class默认会帮我们自动配置单数据源,所以,如果想在项目中使用多数据源就需要排除它,手动指定多数据源。
@SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })
public class WebApplication
{
public static void main(String[] args)
{
SpringApplication.run(WebApplication.class, args);
}
}
用法以及测试
在配置好了读写分离之后,就可以在代码中使用了,一般而言我们使用在 service 层或者 dao 层。
在需要查询的方法上添加@DataSourceSwitcher(DataSourceType.SLAVE),它表示该方法下所有的操作都走的是读库;
在需要 update 或者 insert 的时候使用@DataSourceSwitcher(DataSourceType.MASTER)表示接下来将会走写库。
@Service
public class OrderService {
@Resource
private OrderMapper orderMapper;
/**
* 读操作
*
* @param orderId
* @return
*/
@DataSourceSwitcher(DataSourceType.SLAVE)
public List<Order> getOrder(String orderId) {
return orderMapper.listOrders(orderId);
}
/**
* 写操作
*
* @param orderId
* @return
*/
@DataSourceSwitcher(DataSourceType.MASTER)
public List<Order> insertOrder(Long orderId) {
Order order = new Order();
order.setOrderId(orderId);
return orderMapper.saveOrder(order);
}
}
总结流程图
如何实现数据库读写分离,注意读写分离的核心点就是数据路由,需要继承 AbstractRoutingDataSource,复写它的 determineCurrentLookupKey 方法,同时需要注意全局的上下文管理器 DataSourceContextHolder,它是保存数据源上下文的主要类,也是路由方法中寻找的数据源取值,相当于数据源的中转站,我们的数据库读写分离就完美实现了。
druid 配置(扩展)
# 数据源配置
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
druid:
# 主库数据源
master:
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: 123456
# 从库数据源
slave:
# 从数据源开关/默认关闭
enabled: false
url:
username:
password:
# 初始连接数
initialSize: 5
# 最小连接池数量
minIdle: 10
# 最大连接池数量
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
# 配置一个连接在池中最大生存的时间,单位是毫秒
maxEvictableIdleTimeMillis: 900000
# 配置检测连接是否有效
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
webStatFilter:
enabled: true
statViewServlet:
enabled: true
# 设置白名单,不填则允许所有访问
allow:
url-pattern: /druid/*
# 控制台管理用户名和密码
login-username: hviger
login-password: 123456
filter:
stat:
enabled: true
# 慢SQL记录
log-slow-sql: true
slow-sql-millis: 1000
merge-sql: true
wall:
config:
multi-statement-allow: true
配置类:
/**
* druid 配置属性
*
* @author hviger
*/
@Configuration
public class DruidProperties
{
@Value("${spring.datasource.druid.initialSize}")
private int initialSize;
@Value("${spring.datasource.druid.minIdle}")
private int minIdle;
@Value("${spring.datasource.druid.maxActive}")
private int maxActive;
@Value("${spring.datasource.druid.maxWait}")
private int maxWait;
@Value("${spring.datasource.druid.timeBetweenEvictionRunsMillis}")
private int timeBetweenEvictionRunsMillis;
@Value("${spring.datasource.druid.minEvictableIdleTimeMillis}")
private int minEvictableIdleTimeMillis;
@Value("${spring.datasource.druid.maxEvictableIdleTimeMillis}")
private int maxEvictableIdleTimeMillis;
@Value("${spring.datasource.druid.validationQuery}")
private String validationQuery;
@Value("${spring.datasource.druid.testWhileIdle}")
private boolean testWhileIdle;
@Value("${spring.datasource.druid.testOnBorrow}")
private boolean testOnBorrow;
@Value("${spring.datasource.druid.testOnReturn}")
private boolean testOnReturn;
public DruidDataSource dataSource(DruidDataSource datasource)
{
/** 配置初始化大小、最小、最大 */
datasource.setInitialSize(initialSize);
datasource.setMaxActive(maxActive);
datasource.setMinIdle(minIdle);
/** 配置获取连接等待超时的时间 */
datasource.setMaxWait(maxWait);
/** 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 */
datasource.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis);
/** 配置一个连接在池中最小、最大生存的时间,单位是毫秒 */
datasource.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis);
datasource.setMaxEvictableIdleTimeMillis(maxEvictableIdleTimeMillis);
/**
* 用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。
*/
datasource.setValidationQuery(validationQuery);
/** 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 */
datasource.setTestWhileIdle(testWhileIdle);
/** 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 */
datasource.setTestOnBorrow(testOnBorrow);
/** 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 */
datasource.setTestOnReturn(testOnReturn);
return datasource;
}
}
/**
* druid 配置多数据源
*
* @author hviger
*/
@Configuration
public class DruidConfig
{
/**
* 去除监控页面底部的广告
*/
@SuppressWarnings({ "rawtypes", "unchecked" })
@Bean
@ConditionalOnProperty(name = "spring.datasource.druid.statViewServlet.enabled", havingValue = "true")
public FilterRegistrationBean removeDruidFilterRegistrationBean(DruidStatProperties properties)
{
// 获取web监控页面的参数
DruidStatProperties.StatViewServlet config = properties.getStatViewServlet();
// 提取common.js的配置路径
String pattern = config.getUrlPattern() != null ? config.getUrlPattern() : "/druid/*";
String commonJsPattern = pattern.replaceAll("\\*", "js/common.js");
final String filePath = "support/http/resources/js/common.js";
// 创建filter进行过滤
Filter filter = new Filter()
{
@Override
public void init(javax.servlet.FilterConfig filterConfig) throws ServletException
{
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException
{
chain.doFilter(request, response);
// 重置缓冲区,响应头不会被重置
response.resetBuffer();
// 获取common.js
String text = Utils.readFromResource(filePath);
// 正则替换banner, 除去底部的广告信息
text = text.replaceAll("<a.*?banner\"></a><br/>", "");
text = text.replaceAll("powered.*?shrek.wang</a>", "");
response.getWriter().write(text);
}
@Override
public void destroy()
{
}
};
FilterRegistrationBean registrationBean = new FilterRegistrationBean();
registrationBean.setFilter(filter);
registrationBean.addUrlPatterns(commonJsPattern);
return registrationBean;
}
}




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步