prometheus学习系列十四: Prometheus和AlertManager的高可用
前面的系列中, prometheus和alertmanager都是单机部署的,会有单机宕机导致系统不可用情况发生。本文主要介绍下prometheus和alertmanager的高可用方案。
服务的高可靠性架构(基本ha)
promehtues是以pull方式进行设计的,因此手机时序资料都是通过prometheus本身主动发起的,而为了保证prometheus服务能够正常运行,只需要创建多个prometheus节点来收集同样的metrics即可。
架构图:
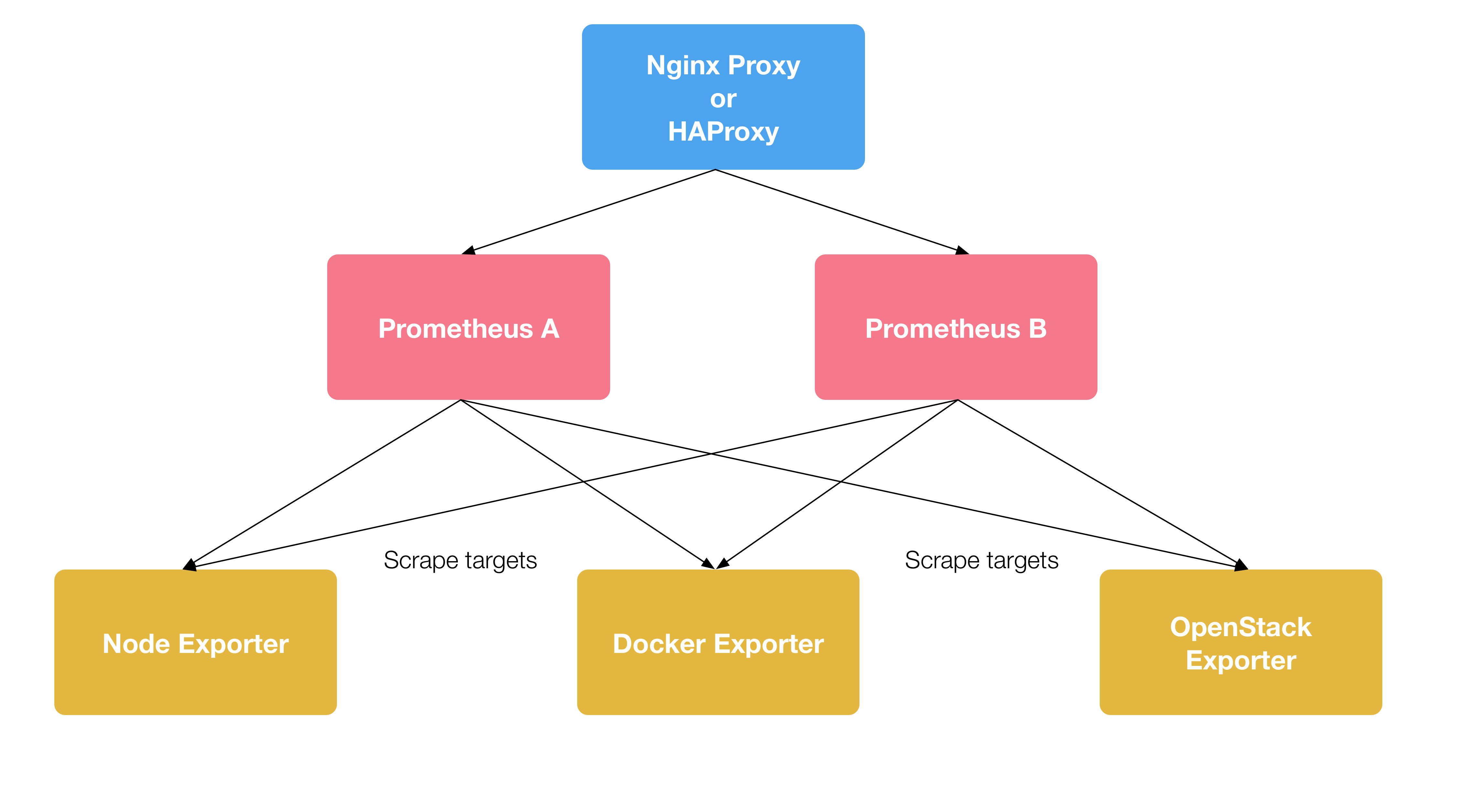
这个架构可以保证服务的高可靠性,但是并不能解决多个prometheus实例之间的资料一致性问题,也无法数据进行长期存储,且单一实例无法负荷的时候,将延伸出性能瓶颈问题,因此这种架构适合小规模进行监控。
优点:
- 服务能够提供基本的可靠性
- 适合小规模监控,只需要短期存储。
缺点:
- 无法扩展
- 数据有不一致问题
- 无法长时间保持
- 当承载量过大时,单一prometheus无法负荷。
服务高可靠性结合远端存储(基本ha + remote storage)
这种架构是在基本ha的基础上面,加入远端存储的,将数据存储在第三方的存储系统中。
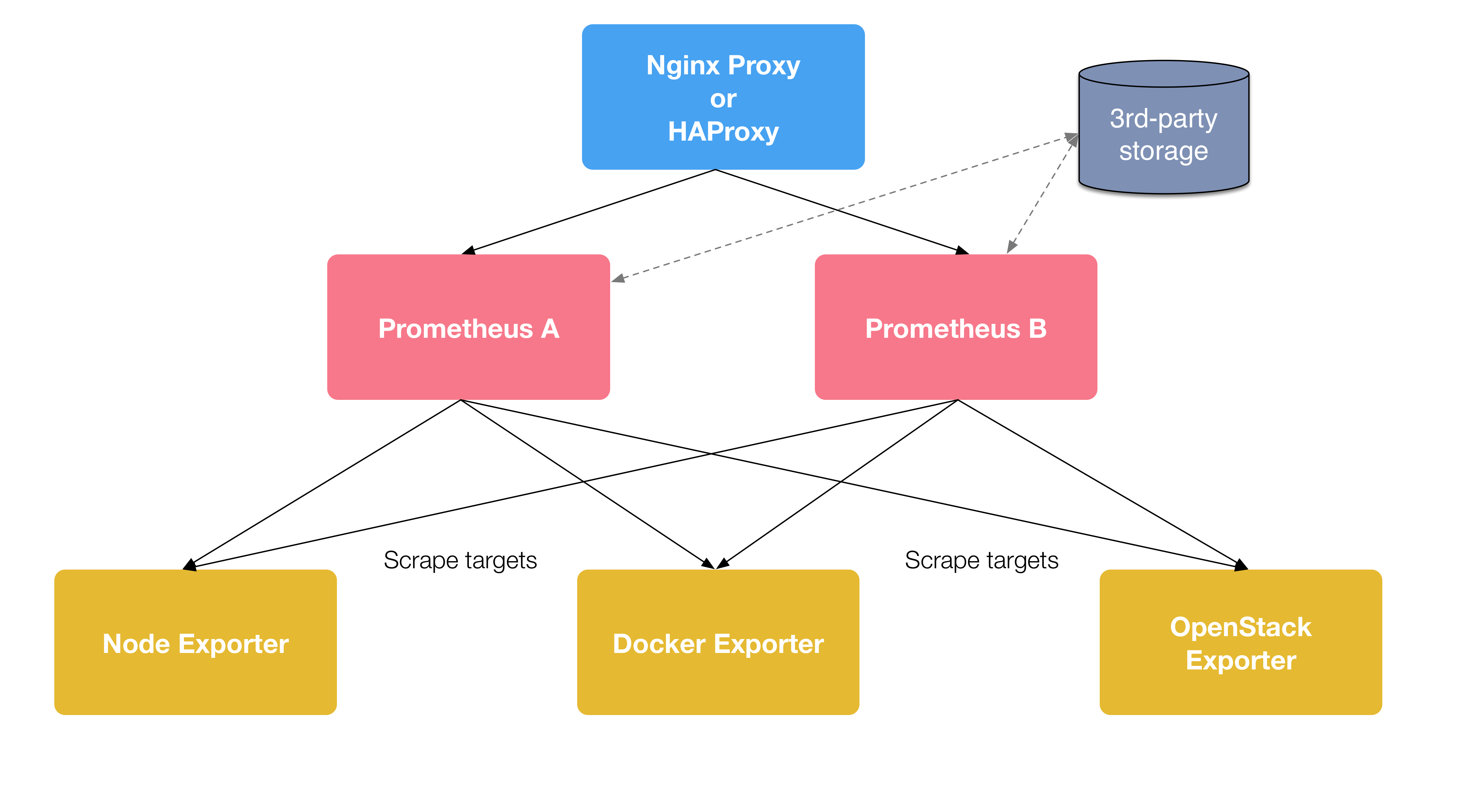
该架构解决了数据持久性问题, 当prometheus server发生故障、重启的时候可以快速恢复数据,同时prometheus可以很好的进行迁移,但是这也只适合小规模的监测使用。
优点:
- 服务能够提供可靠性
- 适合小规模监测
- 数据能够持久化存储
- prometheus可以灵活迁移
- 能够得到数据还原
缺点:
- 不适合大规模监控
- 当承载量过大时,单一prometheus server无法负荷
服务高可靠性结合远端存储和联邦(基本ha + remote storage + federation)
这种架构主要是解决单一 prometheus server无法处理大量数据收集的问题,而且加强了prometheus的扩展性,通过将不同手机任务分割到不同的prometheus实力上去。
该架构通常有2种使用场景:
单一资料中心,但是有大量收集任务,这种场景行prometheus server 可能会发生性能上的瓶颈,主要是单一prometheus server 要承载大量资料书籍任务, 这个时候通过federation来将不同类型的任务分到不同的prometheus 子server 上, 再有上层完成资料聚合。
多资料中心, 在多资料中心下,这种架构也能够使用,当不同资料中心的exporter无法让最上层的prometheus 去拉取资料是, 就能通过federation来进行分层处理, 在每个资料中心建立一组收集该资料中心的prometheus server , 在由上层的prometheus 来进行抓取, 并且也能够依据每个收集任务的承载量来部署分级,但是需要确保上下层的prometheus server 是互通的。
优点
服务能够提供可靠性
资料能够被持久性保持在第三方存储系统中
promethues server 能够迁移
能够得到资料还原
能够依据不同任务进行层级划分
适合不同规模监控
能够很好的扩展
缺点
部署架构负载
维护困难性增加
在kubernetes部署不易
------------------------------------------------------------------------------------------------------------------- 未完待续--------------------------------------------------------------------------------------------------------------
posted on 2019-10-11 15:32 LinuxPanda 阅读(2084) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号