


安装部署Apache Hadoop (完全分布式模式并且实现NameNode HA和ResourceManager HA)
本节内容:
- 环境规划
- 配置集群各节点hosts文件
- 安装JDK1.7
- 安装依赖包ssh和rsync
- 各节点时间同步
- 安装Zookeeper集群
- 添加Hadoop运行用户
- 配置主节点登录自己和其他节点不需要输入密码
- 安装hadoop
- 启动hadoop
- 停止hadoop
一、环境规划
| 主机名 | IP地址 | 操作系统版本 | 安装软件 |
| hadoop16 | 172.16.206.16 | CentOS 7.2 | JDK1.7、hadoop-2.7.2 |
| hadoop26 | 172.16.206.26 | CentOS 7.2 | JDK1.7、hadoop-2.7.2 |
| hadoop27 | 172.16.206.27 | CentOS 7.2 | JDK1.7、hadoop-2.7.2、Zookeeper |
| hadoop28 | 172.16.206.28 | CentOS 7.2 | JDK1.7、hadoop-2.7.2、Zookeeper |
| hadoop29 | 172.16.206.29 | CentOS 7.2 | JDK1.7、hadoop-2.7.2、Zookeeper |
由于机器资源紧张,将NameNode和ResourceManager安装在一台机器上。在hadoop16主机上安装NameNode和ResourceManager使其处于active状态,在hadoop26上安装NameNode和ResourceManager使其处于standby状态。
环境拓扑:
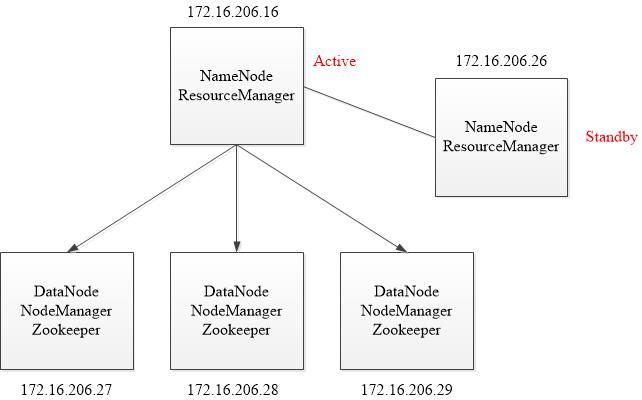
由于是实验环境,所以将NameNode和ResourceManager放在了一起,生产环境下应该将NameNode和ResourceManager放在单独的机器上。
Hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这两种共享数据的方案,NFS是操作系统层面的,JournalNode是hadoop层面的,这里我们使用简单的QJM集群进行数据共享。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode。
另外还配置了一个zookeeper集群(27,28,29主机),用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode和ResourceManager为standby状态。同时27,28,29主机作为DataNode节点。
二、配置集群各节点hosts文件
在集群各节点,编辑hosts文件,配置好各节点主机名和ip地址的对应关系:
# vim /etc/hosts 172.16.206.16 hadoop16 172.16.206.26 hadoop26 172.16.206.27 hadoop27 172.16.206.28 hadoop28 172.16.206.29 hadoop29
三、安装JDK1.7
Hadoop Java Versions
Version 2.7 and later of Apache Hadoop requires Java 7. It is built and tested on both OpenJDK and Oracle (HotSpot)'s JDK/JRE. <br />
Earlier versions (2.6 and earlier) support Java 6.


# mkdir /usr/java # tar zxf /usr/local/jdk-7u80-linux-x64.gz -C /usr/java/ # vim /etc/profile export JAVA_HOME=/usr/java/jdk1.7.0_80 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar # source /etc/profile
四、安装依赖包ssh和rsync
对于Redhat/CentOS系列的,安装系统时一般都会默认安装openssh软件,里面包含了ssh客户端和ssh服务端,所以先检查下这个软件包是否安装了:
# yum list all openssh
如果没有安装,安装:
# yum install -y openssh
在检查rsync软件包是否安装:
# yum list all rsync
五、各节点时间同步
采用NTP(Network Time Protocol)方式来实现, 选择一台机器, 作为集群的时间同步服务器, 然后分别配置服务端和集群其他机器。我这里以hadoop16机器时间为准,其他机器同这台机器时间做同步。
1. NTP服务端
(1)安装ntp服务
# yum install ntp -y
(2)配置/etc/ntp.conf,这边采用本地机器作为时间的原点
注释server列表:
server 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst server 3.centos.pool.ntp.org iburst
添加如下内容:
server 127.127.1.0 prefer fudge 127.127.1.0 stratum 8 logfile /var/log/ntp.log
(3)启动ntpd服务
# systemctl start ntpd
(4)查看ntp服务状态
# systemctl status ntpd
(5)加入开机启动
# systemctl enable ntpd
2. NTP客户端
(1)安装ntp
# yum install ntpdate
(2)配置crontab任务主动同步
# crontab -e */10 * * * * /usr/sbin/ntpdate 172.16.206.16;hwclock -w
六、安装Zookeeper集群
对于Zookeeper集群的话,官方推荐的最小节点数为3个。
1. 安装配置zk
(1)配置zk节点的hosts文件
配置zk节点的hosts文件:配置3台机器的ip地址和主机名的对应关系。上面已经做过了。这里选择3台安装zk:hadoop27,hadoop28,hadoop29。
(2)解压安装配置第一台zk
# cd /usr/local/ # tar zxf zookeeper-3.4.6.tar.gz # cd zookeeper-3.4.6 创建快照日志存放目录: # mkdir dataDir 创建事务日志存放目录: # mkdir dataLogDir
注意:如果不配置dataLogDir,那么事务日志也会写在dataDir目录中。这样会严重影响zk的性能。因为在zk吞吐量很高的时候,产生的事务日志和快照日志太多。
# cd conf # mv zoo_sample.cfg zoo.cfg # vim zoo.cfg # 存放数据文件 dataDir=/usr/local/zookeeper-3.4.6/dataDir # 存放日志文件 dataLogDir=/usr/local/zookeeper-3.4.6/dataLogDir # zookeeper cluster,2888为选举端口,3888为心跳端口 server.1=hadoop27:2888:3888 server.2=hadoop28:2888:3888 server.3=hadoop29:2888:3888

在我们配置的dataDir指定的目录下面,创建一个myid文件,里面内容为一个数字,用来标识当前主机,conf/zoo.cfg文件中配置的server.X中X为什么数字,则myid文件中就输入这个数字:
hadoop27主机:
# echo "1" > /usr/local/zookeeper-3.4.6/dataDir/myid
(3)远程复制第一台的zk到另外两台上,并修改myid文件为2和3
# cd /usr/local/ # scp -rp zookeeper-3.4.6 root@172.16.206.28:/usr/local/ # echo "2" > /usr/local/zookeeper-3.4.6/dataDir/myid # scp -rp zookeeper-3.4.6 root@172.16.206.29:/usr/local/ # echo "3" > /usr/local/zookeeper-3.4.6/dataDir/myid
2. 启动和关闭Zookeeper
在ZooKeeper集群的每个结点上,执行启动ZooKeeper服务的脚本,如下所示:
[root@hadoop27 ~]# /usr/local/zookeeper-3.4.6/bin/zkServer.sh start [root@hadoop28 ~]# /usr/local/zookeeper-3.4.6/bin/zkServer.sh start [root@hadoop29 ~]# /usr/local/zookeeper-3.4.6/bin/zkServer.sh start
停止zk的命令:
# /usr/local/zookeeper-3.4.6/bin/zkServer.sh stop
3. 测试zk集群
可以通过ZooKeeper的脚本来查看启动状态,包括集群中各个结点的角色(或是Leader,或是Follower):
[root@hadoop27 ~]# /usr/local/zookeeper-3.4.6/bin/zkServer.sh status JMX enabled by default Using config: /usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg Mode: follower [root@hadoop28 ~]# /usr/local/zookeeper-3.4.6/bin/zkServer.sh status JMX enabled by default Using config: /usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg Mode: leader [root@hadoop29 ~]# /usr/local/zookeeper-3.4.6/bin/zkServer.sh status JMX enabled by default Using config: /usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg Mode: follower
通过上面状态查询结果可见,hadoop28是集群的Leader,其余的两个结点是Follower。
另外,可以通过客户端脚本,连接到ZooKeeper集群上。对于客户端来说,ZooKeeper是一个整体,连接到ZooKeeper集群实际上感觉在独享整个集群的服务,所以,你可以在任何一个结点上建立到服务集群的连接。
[root@hadoop29 ~]# /usr/local/zookeeper-3.4.6/bin/zkCli.sh -server hadoop27:2181 Connecting to localhost:2181 2016-07-18 21:26:57,647 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 2016-07-18 21:26:57,650 [myid:] - INFO [main:Environment@100] - Client environment:host.name=hadoop29 2016-07-18 21:26:57,650 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.7.0_80 2016-07-18 21:26:57,652 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation 2016-07-18 21:26:57,652 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/usr/java/jdk1.7.0_80/jre 2016-07-18 21:26:57,652 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/usr/local/zookeeper-3.4.6/bin/../build/classes:/usr/local/zookeeper-3.4.6/bin/../build/lib/*.jar:/usr/local/zookeeper-3.4.6/bin/../lib/slf4j-log4j12-1.6.1.jar:/usr/local/zookeeper-3.4.6/bin/../lib/slf4j-api-1.6.1.jar:/usr/local/zookeeper-3.4.6/bin/../lib/netty-3.7.0.Final.jar:/usr/local/zookeeper-3.4.6/bin/../lib/log4j-1.2.16.jar:/usr/local/zookeeper-3.4.6/bin/../lib/jline-0.9.94.jar:/usr/local/zookeeper-3.4.6/bin/../zookeeper-3.4.6.jar:/usr/local/zookeeper-3.4.6/bin/../src/java/lib/*.jar:/usr/local/zookeeper-3.4.6/bin/../conf:.:/usr/java/jdk1.7.0_80/lib/dt.jar:/usr/java/jdk1.7.0_80/lib/tools.jar 2016-07-18 21:26:57,652 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib 2016-07-18 21:26:57,653 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp 2016-07-18 21:26:57,653 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=<NA> 2016-07-18 21:26:57,653 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux 2016-07-18 21:26:57,653 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64 2016-07-18 21:26:57,653 [myid:] - INFO [main:Environment@100] - Client environment:os.version=2.6.32-431.el6.x86_64 2016-07-18 21:26:57,653 [myid:] - INFO [main:Environment@100] - Client environment:user.name=root 2016-07-18 21:26:57,653 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/root 2016-07-18 21:26:57,653 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/root 2016-07-18 21:26:57,654 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=localhost:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@279ac931 [root@hadoop29 ~]# /usr/local/zookeeper-3.4.6/bin/zkCli.sh -server hadoop27:2181 Connecting to hadoop27:2181 2016-07-18 21:29:48,216 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 2016-07-18 21:29:48,219 [myid:] - INFO [main:Environment@100] - Client environment:host.name=hadoop29 2016-07-18 21:29:48,219 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.7.0_80 2016-07-18 21:29:48,221 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation 2016-07-18 21:29:48,221 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/usr/java/jdk1.7.0_80/jre 2016-07-18 21:29:48,221 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/usr/local/zookeeper-3.4.6/bin/../build/classes:/usr/local/zookeeper-3.4.6/bin/../build/lib/*.jar:/usr/local/zookeeper-3.4.6/bin/../lib/slf4j-log4j12-1.6.1.jar:/usr/local/zookeeper-3.4.6/bin/../lib/slf4j-api-1.6.1.jar:/usr/local/zookeeper-3.4.6/bin/../lib/netty-3.7.0.Final.jar:/usr/local/zookeeper-3.4.6/bin/../lib/log4j-1.2.16.jar:/usr/local/zookeeper-3.4.6/bin/../lib/jline-0.9.94.jar:/usr/local/zookeeper-3.4.6/bin/../zookeeper-3.4.6.jar:/usr/local/zookeeper-3.4.6/bin/../src/java/lib/*.jar:/usr/local/zookeeper-3.4.6/bin/../conf:.:/usr/java/jdk1.7.0_80/lib/dt.jar:/usr/java/jdk1.7.0_80/lib/tools.jar 2016-07-18 21:29:48,221 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib 2016-07-18 21:29:48,221 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp 2016-07-18 21:29:48,221 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=<NA> 2016-07-18 21:29:48,221 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux 2016-07-18 21:29:48,221 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64 2016-07-18 21:29:48,222 [myid:] - INFO [main:Environment@100] - Client environment:os.version=2.6.32-431.el6.x86_64 2016-07-18 21:29:48,222 [myid:] - INFO [main:Environment@100] - Client environment:user.name=root 2016-07-18 21:29:48,222 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/root 2016-07-18 21:29:48,222 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/root 2016-07-18 21:29:48,223 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=hadoop27:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@194d62f1 Welcome to ZooKeeper! 2016-07-18 21:29:48,245 [myid:] - INFO [main-SendThread(hadoop27:2181):ClientCnxn$SendThread@975] - Opening socket connection to server hadoop27/172.16.206.27:2181. Will not attempt to authenticate using SASL (unknown error) 2016-07-18 21:29:48,249 [myid:] - INFO [main-SendThread(hadoop27:2181):ClientCnxn$SendThread@852] - Socket connection established to hadoop27/172.16.206.27:2181, initiating session JLine support is enabled [zk: hadoop27:2181(CONNECTING) 0] 2016-07-18 21:29:48,356 [myid:] - INFO [main-SendThread(hadoop27:2181):ClientCnxn$SendThread@1235] - Session establishment complete on server hadoop27/172.16.206.27:2181, sessionid = 0x155fc2e082e0000, negotiated timeout = 30000 WATCHER:: WatchedEvent state:SyncConnected type:None path:null [zk: hadoop27:2181(CONNECTED) 0]
输入quit,可以退出。
4. 脚本定期清理zk快照和日志文件
正常运行过程中,ZK会不断地把快照数据和事务日志输出到dataDir和dataLogDir这两个目录,并且如果没有人为操作的话,ZK自己是不会清理这些文件的。
我这里采用脚本切割。将脚本上传到/usr/local/zookeeper-3.4.6/目录下。脚本内容如下:
#!/bin/bash ###Description:This script is used to clear zookeeper snapshot file and transaction logs. ###Written by: jkzhao - jkzhao@wisedu.com ###History: 2016-04-08 First release. # Snapshot file dir. dataDir=/usr/local/zookeeper-3.4.6/dataDir/version-2 # Transaction logs dir. dataLogDir=/usr/local/zookeeper-3.4.6/dataLogDir/version-2 # Reserved 5 files. COUNT=5 ls -t $dataDir/snapshot.* | tail -n +$[$COUNT+1] | xargs rm -f ls -t $dataLogDir/log.* | tail -n +$[$COUNT+1] | xargs rm -f
# chmod +x clean_zklog.sh
# crontab -e 0 0 * * 0 /usr/local/zookeeper-3.4.6/clean_zklog.sh
所有zk节点都得配置脚本和周期性任务。
七、添加Hadoop运行用户
# groupadd hadoop # useradd -g hadoop hadoop # echo "wisedu" | passwd --stdin hadoop &> /dev/null
所有节点都得添加hadoop用户。
八、配置主节点登录自己和其他节点不需要输入密码
这里的主节点指的是NameNode,ResourceManager。配置hadoop16主机(Active)登录hadoop16,hadoop26,hadoop27,hadoop28,hadoop29主机免密码。还要配置hadoop26主机(Standby)登录hadoop16,hadoop26,hadoop27,hadoop28,hadoop29主机免密码。 (也可以不配置,每个节点一个一个启动服务,最好不要这样做)。
hadoop用户登录shell:
1. 配置hadoop16主机(Active)登录hadoop16,hadoop26,hadoop27,hadoop28,hadoop29主机免密码
[hadoop@hadoop16 ~]$ ssh-keygen -t rsa -P '' [hadoop@hadoop16 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop16 [hadoop@hadoop16 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop26 [hadoop@hadoop16 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop27 [hadoop@hadoop16 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop28 [hadoop@hadoop16 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop29
2. 配置hadoop26主机(Standby)登录hadoop16,hadoop26,hadoop27,hadoop28,hadoop29主机免密码
[hadoop@hadoop26 ~]$ ssh-keygen -t rsa -P '' [hadoop@hadoop26 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop16 [hadoop@hadoop26 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop26 [hadoop@hadoop26 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop27 [hadoop@hadoop26 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop28 [hadoop@hadoop26 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop29
九、安装hadoop
1. 安装配置master节点(hadoop16主机)
(1)将安装包上传至/usr/local目录下并解压
[root@hadoop16 ~]# cd /usr/local/ [root@hadoop16 local]# tar zxf hadoop-2.7.2.tar.gz [root@hadoop16 local]# ln -sv hadoop-2.7.2 hadoop [root@hadoop16 local]# cd hadoop [root@hadoop16 hadoop]# mkdir logs [root@hadoop16 hadoop]# chmod g+w logs [root@hadoop16 hadoop]# chown -R hadoop:hadoop ./* [root@hadoop16 hadoop]# chown -R hadoop:hadoop /usr/local/hadoop-2.7.2
(2)配置hadoop环境变量
[root@hadoop16 hadoop]# vim /etc/profile # HADOOP export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
(3)修改文件hadoop-env.sh
Hadoop的各守护进程依赖于JAVA_HOME环境变量,可在这两个文件中配置特定的JAVA环境。此处仅需要修改hadoop-env.sh文件。此外,Hadoop大多数守护进程默认使用的堆大小为1GB,但现实应用中,可能需要对其各类进程的堆内存大小做出调整,这只需要编辑这两个文件中的相关环境变量值即可,例如HADOOP_HEAPSIZE、HADOOP_JOB_HISTORY_HEAPSIZE、JAVA_HEAP_SIZE和YARN_HEAP_SIZE等。
hadoop用户登录shell,或者root用户登录,su - hadoop。
[hadoop@hadoop16 ~]$ vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh

(4)修改配置文件
hadoop用户登录shell,或者root用户登录,su - hadoop。
[hadoop@hadoop16 ~]$ cd /usr/local/hadoop/etc/hadoop/
修改core-site.xml:该文件包含了NameNode主机地址以及其监听RPC端口等信息,对于伪分布式模式的安装来说,其主机地址是localhost;对于完全分布式中master节点的主机名称或者ip地址;如果配置NameNode是HA,指定HDFS的nameservice为一个自定义名称,然后在hdfs-site.xml配置NameNode节点的主机信息。NameNode默认的RPC端口是8020。
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop27:2181,hadoop28:2181,hadoop29:2181</value>
</property>
</configuration>
修改hdfs-site.xml:该文件主要用于配置HDFS相关的属性,例如复制因子(即数据块的副本数)、NN和DN用于存储数据的目录等。数据块的副本数对于伪分布式的Hadoop应该为1,完全分布式模式下默认数据副本是3份。在这个配置文件中还可以配置NN和DN用于存储的数据的目录。
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hadoop16:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hadoop16:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hadoop26:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hadoop26:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop27:8485;hadoop28:8485;hadoop29:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
注意:如果需要其它用户对hdfs有写入权限,还需要在hdfs-site.xml添加一项属性定义。
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
修改mapred-site.xml:该文件用于配置集群的MapReduce framework,此处应该指定yarn,另外的可用值还有local和classic。mapred-site.xml默认是不存在,但有模块文件mapred-site.xml.template,只需要将其复制mapred-site.xml即可。
[hadoop@hadoop16 hadoop]$ cp mapred-site.xml.template mapred-site.xml [hadoop@hadoop16 hadoop]$ vim mapred-site.xml <configuration> <!-- 指定mr框架为yarn方式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
修改yarn-site.xml:该文件用于配置YARN进程及YARN的相关属性。首先需要指定ResourceManager守护进程的主机和监听的端口,对于伪分布式模型来来讲,其主机为localhost,默认的端口是8032;其次需要指定ResourceManager使用的scheduler,以及NodeManager的辅助服务。
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop16</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop26</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop27:2181,hadoop28:2181,hadoop29:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改slaves:该文件存储了当前集群的所有slave节点的列表,对于伪分布式模型,其文件内容仅应该是你localhost,这也的确是这个文件的默认值。
[hadoop@hadoop16 hadoop]$ vim slaves
hadoop27
hadoop28
hadoop29
Hadoop启动后,会把进程的PID号存储在一个文件中,这样执行stop-dfs脚本时就可以按照进程PID去关闭进程了。而这个默认路径就是/tmp,/tmp目录下的文件系统会定期清理,所以需要修改pid存放的路径:
[hadoop@hadoop16 ~]$ cd /usr/local/hadoop/sbin/ [hadoop@hadoop16 sbin]$ vim hadoop-daemon.sh HADOOP_PID_DIR=/usr/local/hadoop
[hadoop@hadoop16 ~]$ cd /usr/local/hadoop/sbin/ [hadoop@hadoop16 sbin]$ vim yarn-daemon.sh YARN_PID_DIR=/usr/local/hadoop
【注意】:每个节点的这两个文件都得修改。
(5)安装配置其他节点
这里由于实验节点数目少,没有使用ansible等自动化工具。
重复操作解压、配置环境变量,参照前面。
Hadoop集群的各节点配置文件都是一样的,我们可以将master节点上的配置文件scp到其他节点上:
[hadoop@hadoop16 ~]$ scp -p /usr/local/hadoop/etc/hadoop/* hadoop@hadoop26:/usr/local/hadoop/etc/hadoop/ [hadoop@hadoop16 ~]$ scp -p /usr/local/hadoop/etc/hadoop/* hadoop@hadoop27:/usr/local/hadoop/etc/hadoop/ [hadoop@hadoop16 ~]$ scp -p /usr/local/hadoop/etc/hadoop/* hadoop@hadoop28:/usr/local/hadoop/etc/hadoop/ [hadoop@hadoop16 ~]$ scp -p /usr/local/hadoop/etc/hadoop/* hadoop@hadoop29:/usr/local/hadoop/etc/hadoop/
十、启动hadoop
注意:请严格按照下面的步骤启动。
1. 启动Zookeeper集群
分别在hadoop27、hadoop28、hadoop29上启动zk,前面已经启动好了,不再重复。
2. 启动journalnode
hadoop用户登录shell,分别在在hadoop27、hadoop28、hadoop29上执行:
[hadoop@hadoop27 ~]$ /usr/local/hadoop/sbin/hadoop-daemon.sh start journalnode
运行jps命令检验,hadoop27、hadoop28、hadoop29上多了JournalNode进程。
3. 格式化HDFS
在HDFS的NN启动之前需要先初始化其用于存储数据的目录,可以在hdfs-site.xml配置文件中使用dfs.namenode.name.dir属性定义HDFS元数据持久存储路径,默认为${hadoop.tmp.dir}/dfs/name,这里是存放在JournalNode中;dfs.datanode.data.dir属性定义DataNode用于存储数据块的目录路径,默认为${hadoop.tmp.dir}/dfs/data。如果指定的目录不存在,格式化命令会自动创建之;如果事先存在,请确保其权限设置正确,此时格式化操作会清除其内部的所有数据并重新建立一个新的文件系统。
在hadoop16(Active)上执行命令:
[hadoop@hadoop16 ~]$ hdfs namenode -format

格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/usr/local/hadoop/tmp。
启动hadoop16主机上的NameNode:
[hadoop@hadoop16 ~]$ hadoop-daemon.sh start namenode
然后在hadoop26(Standby)主机上执行如下命令,同步hadoop16主机上的NameNode元数据信息:
[hadoop@hadoop26 ~]$ hdfs namenode –bootstrapStandby
同步完成后,停止hadoop16主机上的NameNode:
[hadoop@hadoop16 ~]$ hadoop-daemon.sh stop namenode
这里如果不启动Active的NameNode,就在Standby主机上同步,会报如下的错误:
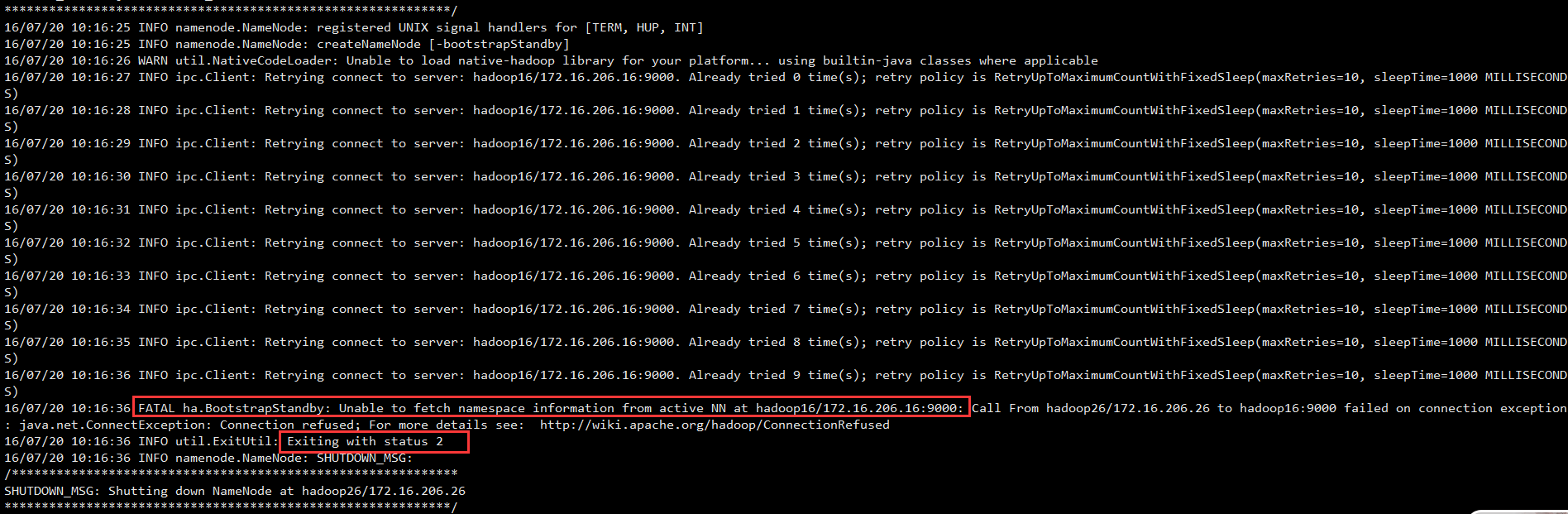
这是因为没有启动active namenode,因为standby namenode是通过active namenode的9000端口通讯的。若active namenode没有启动,则9000没有程序监听提供服务。
当然也可以不启动Active NameNode就进行同步元数据信息,就是直接用命令拷贝Active主机上的元数据信息目录到Standby主机上,但是不建议这么做:
[hadoop@hadoop16 hadoop]$ scp -r tmp/ hadoop@hadoop26:/usr/local/hadoop
4. 启动HDFS(在hadoop16上执行)
[hadoop@hadoop16 ~]$ /usr/local/hadoop/sbin/start-dfs.sh

可以在各主机执行jps,查看启动的进程:
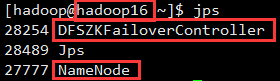

5. 启动YARN
注意:还是在hadoop16上执行start-yarn.sh,这是因为没有把namenode和resourcemanager分开,生产环境需要把他们分开,他们分开了就要分别在不同的机器上启动。
启动yarn(在hadoop16上):
[hadoop@hadoop16 ~]$ /usr/local/hadoop/sbin/start-yarn.sh

启动yarn standby(在hadoop26上):
[hadoop@hadoop26 ~]$ /usr/local/hadoop/sbin/yarn-daemon.sh start resourcemanager
十一、停止hadoop
停止HDFS集群:
[hadoop@hadoop16 ~]$ stop-dfs.sh
停止YARN集群:
[hadoop@hadoop16 ~]$ stop-yarn.sh
停止ResourceManager(Standby):
[hadoop@hadoop26 ~]$ yarn-daemon.sh stop resourcemanager
