大数据Hive函数高阶
1 UDTF之explode函数
1.1 explode语法功能
对于UDTF表生成函数,很多人难以理解什么叫做输入一行,输出多行。
为什么叫做表生成?能够产生表吗?下面我们就来学习Hive当做内置的一个非常著名的UDTF函数,名字叫做explode函数,中文戏称之为“爆炸函数”,可以炸开数据。
explode函数接收map或者array类型的数据作为参数,然后把参数中的每个元素炸开变成一行数据。一个元素一行。这样的效果正好满足于输入一行输出多行。
explode函数在关系型数据库中本身是不该出现的。
因为他的出现本身就是在操作不满足第一范式的数据(每个属性都不可再分)。本身已经违背了数据库的设计原理,但是在面向分析的数据库或者数据仓库中,这些规范可以发生改变。
explode(a) - separates the elements of array a into multiple rows, or the elements of a map into multiple rows and columns 
explode(array)将array列表里的每个元素生成一行;
explode(map)将map里的每一对元素作为一行,其中key为一列,value为一列;
一般情况下,explode函数可以直接使用即可,也可以根据需要结合lateral view侧视图使用。
1.2 explode函数的使用
select explode(array(11,22,33)) as item;
select explode(map(“id”,10086,“name”,“zhangsan”,“age”,18));

1.3 案例:NBA总冠军球队名单
1.3.1 业务需求
有一份数据《The_NBA_Championship.txt》,关于部分年份的NBA总冠军球队名单:

第一个字段表示的是球队名称,第二个字段是获取总冠军的年份,字段之间以,分割;
获取总冠军年份之间以|进行分割。
需求:使用Hive建表映射成功数据,对数据拆分,要求拆分之后数据如下所示:

并且最好根据年份的倒序进行排序。
1.3.2 代码实现
--step1:建表
create table the_nba_championship(
team_name string,
champion_year array<string>
) row format delimited
fields terminated by ','
collection items terminated by '|';
--step2:加载数据文件到表中
load data local inpath '/root/hivedata/The_NBA_Championship.txt' into table the_nba_championship;
--step3:验证
select *
from the_nba_championship;

下面使用explode函数:
–step4:使用explode函数对champion_year进行拆分 俗称炸开
select explode(champion_year) from the_nba_championship;
select team_name,explode(champion_year) from the_nba_championship;

1.3.3 explode使用限制
在select条件中,如果只有explode函数表达式,程序执行是没有任何问题的;
但是如果在select条件中,包含explode和其他字段,就会报错。错误信息为:
org.apache.hadoop.hive.ql.parse.SemanticException:UDTF’s are not supported outside the SELECT clause, nor nested in expressions
那么如何理解这个错误呢?为什么在select的时候,explode的旁边不支持其他字段的同时出现?
1.3.4 explode语法限制原因
1、 explode函数属于UDTF函数,即表生成函数;
2、 explode函数执行返回的结果可以理解为一张虚拟的表,其数据来源于源表;
3、 在select中只查询源表数据没有问题,只查询explode生成的虚拟表数据也没问题
4、 但是不能在只查询源表的时候,既想返回源表字段又想返回explode生成的虚拟表字段
5、 通俗点讲,有两张表,不能只查询一张表但是返回分别属于两张表的字段;
6、 从SQL层面上来说应该对两张表进行关联查询
7、 Hive专门提供了语法lateral View侧视图,专门用于搭配explode这样的UDTF函数,以满足上述需要。

2 Lateral View侧视图
2.1 概念
Lateral View是一种特殊的语法,主要用于搭配UDTF类型功能的函数一起使用,用于解决UDTF函数的一些查询限制的问题。
侧视图的原理是将UDTF的结果构建成一个类似于视图的表,然后将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表。这样就避免了UDTF的使用限制问题。使用lateral view时也可以对UDTF产生的记录设置字段名称,产生的字段可以用于group by、order by 、limit等语句中,不需要再单独嵌套一层子查询。
一般只要使用UDTF,就会固定搭配lateral view使用。
官方链接:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LateralView
2.2 UDTF配合侧视图使用
针对上述NBA冠军球队年份排名案例,使用explode函数+lateral view侧视图,可以完美解决:
–lateral view侧视图基本语法如下
select …… from tabelA lateral view UDTF(xxx) 别名 as col1,col2,col3……;
select a.team_name ,b.year
from the_nba_championship a lateral view explode(champion_year) b as year
–根据年份倒序排序
select a.team_name ,b.year
from the_nba_championship a lateral view explode(champion_year) b as year
order by b.year desc;
3 Aggregation 聚合函数
3.1 基础聚合
HQL提供了几种内置的UDAF聚合函数,例如max(…),min(…)和avg(…)。这些我们把它称之为基础的聚合函数。
通常情况下,聚合函数会与GROUP BY子句一起使用。 如果未指定GROUP BY子句,默认情况下,它会汇总所有行数据。
--------------基础聚合函数-------------------
--1、测试数据准备
drop table if exists student;
create table student(
num int,
name string,
sex string,
age int,
dept string)
row format delimited
fields terminated by ',';
--加载数据
load data local inpath '/root/hivedata/students.txt' into table student;
--验证
select * from student;
--场景1:没有group by子句的聚合操作
select count(*) as cnt1,count(1) as cnt2 from student; --两个一样
--场景2:带有group by子句的聚合操作 注意group by语法限制
select sex,count(*) as cnt from student group by sex;
--场景3:select时多个聚合函数一起使用
select count(*) as cnt1,avg(age) as cnt2 from student;
--场景4:聚合函数和case when条件转换函数、coalesce函数、if函数使用
select
sum(CASE WHEN sex = '男'THEN 1 ELSE 0 END)
from student;
select
sum(if(sex = '男',1,0))
from student;
--场景5:聚合参数不支持嵌套聚合函数
select avg(count(*)) from student;
--聚合参数针对null的处理方式
--null null 0
select max(null), min(null), count(null);
--下面这两个不支持null
select sum(null), avg(null);
--场景5:聚合操作时针对null的处理
CREATE TABLE tmp_1 (val1 int, val2 int);
INSERT INTO TABLE tmp_1 VALUES (1, 2),(null,2),(2,3);
select * from tmp_1;
--第二行数据(NULL, 2) 在进行sum(val1 + val2)的时候会被忽略
select sum(val1), sum(val1 + val2) from tmp_1;
--可以使用coalesce函数解决
select
sum(coalesce(val1,0)),
sum(coalesce(val1,0) + val2)
from tmp_1;
--场景6:配合distinct关键字去重聚合
--此场景下,会编译期间会自动设置只启动一个reduce task处理数据 性能可能会不会 造成数据拥堵
select count(distinct sex) as cnt1 from student;
--可以先去重 在聚合 通过子查询完成
--因为先执行distinct的时候 可以使用多个reducetask来跑数据
select count(*) as gender_uni_cnt
from (select distinct sex from student) a;
--案例需求:找出student中男女学生年龄最大的及其名字
--这里使用了struct来构造数据 然后针对struct应用max找出最大元素 然后取值
select sex,
max(struct(age, name)).col1 as age,
max(struct(age, name)).col2 as name
from student
group by sex;
select struct(age, name) from student;
select struct(age, name).col1 from student;
select max(struct(age, name)) from student;
3.2 增强聚合
3.2.1 概述与表数据环境准备
增强聚合的grouping_sets、cube、rollup这几个函数主要适用于OLAP多维数据分析模式中,多维分析中的维指的分析问题时看待问题的维度、角度。
下面我们来准备一下数据,通过案例更好的理解函数的功能含义
字段:月份、天、用户cookieid
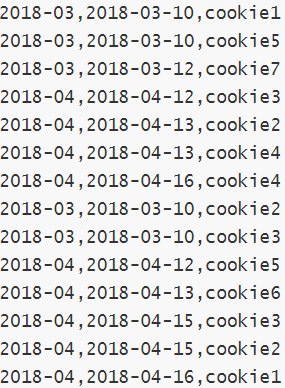
--表创建并且加载数据
CREATE TABLE cookie_info(
month STRING,
day STRING,
cookieid STRING
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
load data local inpath '/root/hivedata/cookie_info.txt' into table cookie_info;
select * from cookie_info;
3.2.2 Grouping sets
grouping sets是一种将多个group by逻辑写在一个sql语句中的便利写法。
等价于将不同维度的GROUP BY结果集进行UNION ALL。
GROUPING__ID表示结果属于哪一个分组集合。
---group sets---------
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
GROUPING SETS (month,day)
ORDER BY GROUPING__ID;
--grouping_id表示这一组结果属于哪个分组集合,
--根据grouping sets中的分组条件month,day,1是代表month,2是代表day
--等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL as month,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day;
--再比如
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
GROUPING SETS (month,day,(month,day))
ORDER BY GROUPING__ID;
--等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS nums,3 AS GROUPING__ID FROM cookie_info GROUP BY month,day;
3.2.3 Cube
cube的语法功能指的是:根据GROUP BY的维度的所有组合进行聚合。
对于cube,如果有n个维度,则所有组合的总个数是:2^n。
比如Cube有a,b,c3个维度,则所有组合情况是:
((a,b,c),(a,b),(b,c),(a,c),(a),(b),©,())。
------cube---------------
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;
--等价于
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS nums,0 AS GROUPING__ID FROM cookie_info
UNION ALL
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS nums,3 AS GROUPING__ID FROM cookie_info GROUP BY month,day;
3.2.4 Rollup
cube的语法功能指的是:根据GROUP BY的维度的所有组合进行聚合。
rollup是Cube的子集,以最左侧的维度为主,从该维度进行层级聚合。
比如ROLLUP有a,b,c3个维度,则所有组合情况是:
((a,b,c),(a,b),(a),())。
--rollup-------------
--比如,以month维度进行层级聚合:
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
WITH ROLLUP
ORDER BY GROUPING__ID;
--把month和day调换顺序,则以day维度进行层级聚合:
SELECT
day,
month,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM cookie_info
GROUP BY day,month
WITH ROLLUP
ORDER BY GROUPING__ID;
4 Window functions 窗口函数
4.1 窗口函数概述
窗口函数(Window functions)是一种SQL函数,非常适合于数据分析,因此也叫做OLAP函数,其最大特点是:输入值是从SELECT语句的结果集中的一行或多行的“窗口”中获取的。你也可以理解为窗口有大有小(行有多有少)。
通过OVER子句,窗口函数与其他SQL函数有所区别。如果函数具有OVER子句,则它是窗口函数。如果它缺少OVER子句,则它是一个普通的聚合函数。
窗口函数可以简单地解释为类似于聚合函数的计算函数,但是通过GROUP BY子句组合的常规聚合会隐藏正在聚合的各个行,最终输出一行,窗口函数聚合后还可以访问当中的各个行,并且可以将这些行中的某些属性添加到结果集中。

为了更加直观感受窗口函数,我们通过sum聚合函数进行普通常规聚合和窗口聚合,一看效果。
----sum+group by普通常规聚合操作------------
select sum(salary) as total from employee group by dept;
----sum+窗口函数聚合操作------------
select id,name,deg,salary,dept,sum(salary) over(partition by dept) as total from employee;



4.2 窗口函数语法
Function(arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_expression>])
--其中Function(arg1,..., argn) 可以是下面分类中的任意一个
--聚合函数:比如sum max avg等
--排序函数:比如rank row_number等
--分析函数:比如lead lag first_value等
--OVER [PARTITION BY <...>] 类似于group by 用于指定分组 每个分组你可以把它叫做窗口
--如果没有PARTITION BY 那么整张表的所有行就是一组
--[ORDER BY <....>] 用于指定每个分组内的数据排序规则 支持ASC、DESC
--[<window_expression>] 用于指定每个窗口中 操作的数据范围 默认是窗口中所有行
4.3 案例:网站用户页面浏览次数分析
在网站访问中,经常使用cookie来标识不同的用户身份,通过cookie可以追踪不同用户的页面访问情况,有下面两份数据:
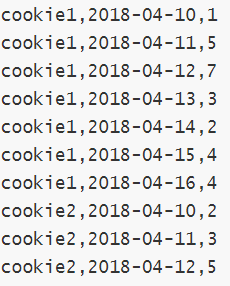
字段含义:cookieid 、访问时间、pv数(页面浏览数)
字段含义:cookieid、访问时间、访问页面url
在Hive中创建两张表表,把数据加载进去用于窗口分析。
---建表并且加载数据
create table website_pv_info(
cookieid string,
createtime string, --day
pv int
) row format delimited
fields terminated by ',';
create table website_url_info (
cookieid string,
createtime string, --访问时间
url string --访问页面
) row format delimited
fields terminated by ',';
load data local inpath '/root/hivedata/website_pv_info.txt' into table website_pv_info;
load data local inpath '/root/hivedata/website_url_info.txt' into table website_url_info;
select * from website_pv_info;
select * from website_url_info;
4.3.1 窗口聚合函数
从Hive v2.2.0开始,支持DISTINCT与窗口函数中的聚合函数一起使用。
这里以sum()函数为例,其他聚合函数使用类似。
-----窗口聚合函数的使用-----------
--1、求出每个用户总pv数 sum+group by普通常规聚合操作
select cookieid,sum(pv) as total_pv from website_pv_info group by cookieid;
--2、sum+窗口函数 总共有四种用法 注意是整体聚合 还是累积聚合
--sum(...) over( )对表所有行求和
--sum(...) over( order by ... ) 连续累积求和
--sum(...) over( partition by... ) 同组内所有行求和
--sum(...) over( partition by... order by ... ) 在每个分组内,连续累积求和
--需求:求出网站总的pv数 所有用户所有访问加起来
--sum(...) over( )对表所有行求和
select cookieid,createtime,pv,
sum(pv) over() as total_pv
from website_pv_info;
--需求:求出每个用户总pv数
--sum(...) over( partition by... ),同组内所行求和
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid) as total_pv
from website_pv_info;
--需求:求出每个用户截止到当天,累积的总pv数
--sum(...) over( partition by... order by ... ),在每个分组内,连续累积求和
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime) as current_total_pv
from website_pv_info;


4.3.2 窗口表达式
我们知道,在sum(…) over( partition by… order by … )语法完整的情况下,进行的累积聚合操作,默认累积聚合行为是:从第一行聚合到当前行。
Window expression窗口表达式给我们提供了一种控制行范围的能力,比如向前2行,向后3行。
语法如下:
关键字是rows between,包括下面这几个选项
- preceding:往前
- following:往后
- current row:当前行
- unbounded:边界
- unbounded preceding 表示从前面的起点
- unbounded following:表示到后面的终点
---窗口表达式
--第一行到当前行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from website_pv_info;
--向前3行至当前行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and current row) as pv4
from website_pv_info;
--向前3行 向后1行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5
from website_pv_info;
--当前行至最后一行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from website_pv_info;
--第一行到最后一行 也就是分组内的所有行
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and unbounded following) as pv6
from website_pv_info;
4.3.3 窗口排序函数
窗口排序函数用于给每个分组内的数据打上排序的标号。注意窗口排序函数不支持窗口表达式。总共有4个函数需要掌握:
row_number:在每个分组中,为每行分配一个从1开始的唯一序列号,递增,不考虑重复;
rank: 在每个分组中,为每行分配一个从1开始的序列号,考虑重复,挤占后续位置;
dense_rank: 在每个分组中,为每行分配一个从1开始的序列号,考虑重复,不挤占后续位置;
-----窗口排序函数
SELECT
cookieid,
createtime,
pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM website_pv_info
WHERE cookieid = 'cookie1';

述这三个函数用于分组TopN的场景非常适合。
--需求:找出每个用户访问pv最多的Top3 重复并列的不考虑
SELECT * from
(SELECT
cookieid,
createtime,
pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS seq
FROM website_pv_info) tmp where tmp.seq <4;

还有一个函数,叫做ntile函数,其功能为:将每个分组内的数据分为指定的若干个桶里(分为若干个部分),并且为每一个桶分配一个桶编号。
如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。
有时会有这样的需求:如果数据排序后分为三部分,业务人员只关心其中的一部分,如何将这中间的三分之一数据拿出来呢?NTILE函数即可以满足。
--把每个分组内的数据分为3桶
SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2
FROM website_pv_info
ORDER BY cookieid,createtime;

--需求:统计每个用户pv数最多的前3分之1天。
--理解:将数据根据cookieid分 根据pv倒序排序 排序之后分为3个部分 取第一部分
SELECT * from
(SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn
FROM website_pv_info) tmp where rn =1;

4.3.4 窗口分析函数
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL);
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL);
FIRST_VALUE 取分组内排序后,截止到当前行,第一个值;
LAST_VALUE 取分组内排序后,截止到当前行,最后一个值;
-----------窗口分析函数----------
--LAG
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAG(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS last_1_time,
LAG(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS last_2_time
FROM website_url_info;
--LEAD
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LEAD(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS next_1_time,
LEAD(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS next_2_time
FROM website_url_info;
--FIRST_VALUE
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS first1
FROM website_url_info;
--LAST_VALUE
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1
FROM website_url_info;

5 Sampling 抽样函数
5.1 抽样概述
当数据量过大时,我们可能需要查找数据子集以加快数据处理速度分析。 这就是抽样、采样,一种用于识别和分析数据中的子集的技术,以发现整个数据集中的模式和趋势。

在HQL中,可以通过三种方式采样数据:随机采样,存储桶表采样和块采样。
5.2 Random随机抽样
随机抽样使用rand()函数和LIMIT关键字来获取数据。 使用了DISTRIBUTE和SORT关键字,可以确保数据也随机分布在mapper和reducer之间,使得底层执行有效率。
ORDER BY 和rand()语句也可以达到相同的目的,但是表现不好。因为ORDER BY是全局排序,只会启动运行一个Reducer。
--数据表
select * from student;
--需求:随机抽取2个学生的情况进行查看
SELECT * FROM student
DISTRIBUTE BY rand() SORT BY rand() LIMIT 2;
--使用order by+rand也可以实现同样的效果 但是效率不高
SELECT * FROM student
ORDER BY rand() LIMIT 2;

5.3 Block块抽样
Block块采样允许select随机获取n行数据,即数据大小或n个字节的数据。
采样粒度是HDFS块大小。
---block抽样
--根据行数抽样
SELECT * FROM student TABLESAMPLE(1 ROWS);
--根据数据大小百分比抽样
SELECT * FROM student TABLESAMPLE(50 PERCENT);
--根据数据大小抽样
--支持数据单位 b/B, k/K, m/M, g/G
SELECT * FROM student TABLESAMPLE(1k);
5.4 Bucket table分桶表抽样
这是一种特殊的采样方法,针对分桶表进行了优化。
---bucket table抽样
--根据整行数据进行抽样
SELECT * FROM t_usa_covid19_bucket TABLESAMPLE(BUCKET 1 OUT OF 2 ON rand());
--根据分桶字段进行抽样 效率更高
describe formatted t_usa_covid19_bucket;
SELECT * FROM t_usa_covid19_bucket TABLESAMPLE(BUCKET 1 OUT OF 2 ON state);
