Zeppelin调试Spark程序
目录
1 什么是Zeppelin
详细安装入门概述:https://blog.csdn.net/ZGL_cyy/article/details/119342340
a. Apache Zeppelin 是一个基于网页的交互式数据分析开源框架。Zeppelin提供了数据分析、数据可
视化等功能, 支持的图表如下图所示
b. Zeppelin 也是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可
协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、
SparkSQL、Hive、hbase、elasticsearch、JDBC等等;
## 参数说明
# spark-submit 把程序提交到spark集群的命令, 可以配置PATH, 使用相对路径或者绝对路径使用该命
令
# --class 程序运行主类
# --master spark master地址( 集群地址 )
# wordcount.jar 你的程序
# --jars 指定依赖
spark-submit --class cn.itcast.xc.first.WordCount --master spark://xc-online-
spark:7077 wordcount.jar
2 Zeppelin配置spark
启动zeppein容器, 如果已启动, 此步可跳过, 继续下一步
# 在docker-compose.yml文件目录执行bash命令, 这里的路径是: /opt/cdh5.14.0
docker-compose up -d xc-online-zeppelin
访问地址: http://xc-online:18080/
配置spark属性
3 Zeppein运行spark程序
3.1 创建spark notebook
1, 点击左上角Notebook --> 弹出窗口点击 Create new note --> 弹出窗口找到spark,名字任意起个就
行 点击Create创建即可 , 操作如下:
3.2 使用SparkSQL查看有多少数据库:
这里使用的是spark sql进行查询数据库操作!
3.3 使用SparkCore执行word count
这里使用的是 spark core 代码如下:
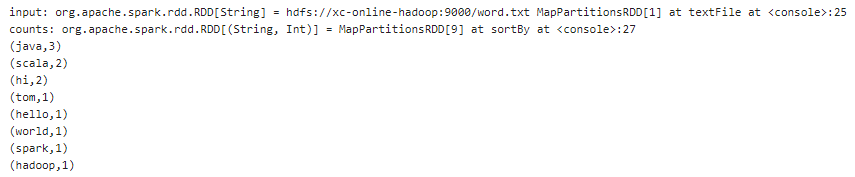
%spark
val input = sc.textFile("hdfs://xc-online-hadoop:9000/word.txt")
val counts = input.flatMap(line => line.split("\t")).map(word => {(word,
1)}).reduceByKey(_ + _).sortBy(_._2, false)
counts.collect().foreach(println(_))
结果如下: