
大数据Hadoop集群的启动
目录
1 启动准备工作
通过前面的配置现在可以启动Hadoop集群了,但是在首次启动Hadoop时还需要做一些准备工作。
1.1 配置操作系统的环境变量
由于我们是在Linux集群上安装Hadoop集群的,所以需要配置Linux操作系统的环境变量。注意,这里的配置需要在集群的所有计算机上进行,并且使用普通用户权限。下面演示在Master上的配置。
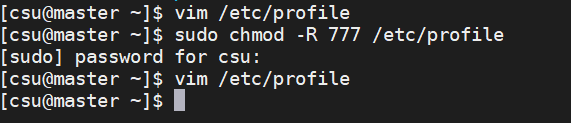
将下面的代码追加到文件的尾部:
遇到文件只读开放所有权限:命令行执行 sudo chmod -R 777 路径
#HADOOP
export HADOOP_HOME=/home/csu/hadoop-3.1.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

保存退出后,执行source /etc/profile命令使上述配置生效。
1.2 创建Hadoop数据目录
本节的操作也必须在所有的节点上进行。我们计划在普通用户(这里是csu)主目录下创建数据目录,命令是“mkdir /home/csu/hadoopdata”。

请读者注意,这里的数据目录名hadoopdata与前面Hadoop核心组件文件core-site.xml中的配置:
<name>hadoop.tmp.dir</name>
<value>/home/csu/hadoopdata</value>
是一致的
1.3 格式化文件系统
该操作只需要在Master上进行,命令是“hdfs namenode -format”。
注意,如果系统提示没有这个命令,读者可以尝试进入hadoop-3.1.0下的bin子目录,里面的hdfs文件就是该命令程序,这时可直接执行上述命令。之所以会出现这种情况,可能是由于用户没有使用“source”命令使操作系统环境配置文件生效。
按下Enter键后,如果出现滚动显示信息,则表明格式化文件系统成功;如果抛出了Exception/Error信息,则表示格式化文件系统出现了问题。

如果在格式化文件系统时遇到问题,可以先删除dfs.name.dir参数指定的目录,确保该目录不存在,再进行格式化。Hadoop这样做的目的是防止错误地将已存在的集群格式化了。
通常,格式化操作本身不会遇到什么问题。但是,也有不少用户可能会由于种种原因而多次进行格式化,结果导致Hadoop集群不能工作。例如,执行MapReduce程序时会遇到类似“There are 0 datanode(s) running and no node(s) are excluded in this operation.”这样的异常信息。
实际上,这样的状况在早期的Hadoop版本中是存在的,主要原因是多次格式化后,导致NameNode中“hadoopdata/dfs/name/current/”下VERSION文件的内容与DataNode中的同名文件内容不一致(具体是ClusterID不一致),解决办法就是通过人工编辑使两个文件的内容一致即可,或者强制删除这些文件后再重新格式化(当然要先关闭Hadoop)。但是,2.6.0版本以后的Hadoop已经不需要这样做了,用户可以多次格式化文件系统,并不会导致VERSION文件内容的不一致,因为在新的Hadoop平台中,DataNode上已经没有VERSION文件了。但是,重新格式化是需要慎重对待的,因为格式化毕竟会将数据删除,所以,有一些维护人员建议只进行一次格式化操作。
1.4 启动和关闭Hadoop
完成上述准备后就可启动Hadoop了。早期版本的Hadoop可以使用“start-all.sh”命令启动Hadoop集群。首先进入Hadoop安装主目录,然后执行sbin/start-all.sh命令。

执行命令后,系统会提示“Are you sure want to continue connecting(yes/no)”,请输入yes,之后系统即可启动。
要关闭Hadoop集群,可以使用“sbin/stop-all.sh”命令。
但是,有必要指出,在下次启动Hadoop时,无须NameNode的初始化,只需要使用“start-dfs.sh”命令即可,然后接着使用start-yarn.sh命令来启动Yarn。实际上,早期版本的Hadoop系统(如2.6.0)已经建议放弃使用start-all.sh和stop-all.sh之类的命令,而改用start-dfs.sh和start-yarn.sh命令。
请读者务必注意,现在3.1版本的Hadoop则必须使用start-dfs.sh命令和start-yarn.sh命令来分别启动HDFS和Yarn。关闭Hadoop则首先使用stop-yarn.sh命令,然后使用stop-dfs.sh命令。
1.5 验证Hadoop是否成功启动
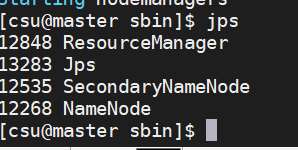
用户可以在终端执行“jps”命令验证Hadoop是否成功启动。在Master上,执行“jps”命令后如果显示的结果是4个进程的名称:ResourceManager、NameNode、Jps和SecondaryNameNode,则表明Master成功启动。
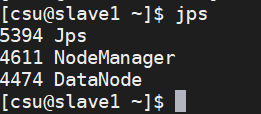
在Slave上执行“jps”命令后会显示三个进程,分别是NodeManager、DataNode和Jps,表明Slave(如slave1)成功启动。
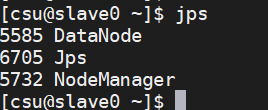
注意:有时候,用户会碰到不能执行“jps”命令的情况,系统给出的提示是“command not
found”。首先,我们要理解,“jps”实际上是一个位于JDK的bin目录下的Java命令,其作用是显示当前系统的Java进程情况及其ID。“jps”相当于Linux的进程工具“ps”,但和“pgrep java”或“ps -ef grep java”命令不一样,“jps”命令并不使用应用程序名来查找JVM实例。此外,“jps”只能查询当前用户的Java进程,而不是当前系统中的所有进程。重新配置java环境变量
在Hadoop集群的运维中,系统管理人员还常常使用Web界面监测Hadoop的运行状况。例如,在Master上启动Firefox浏览器,在浏览器地址栏输入http://master:9870/,可以看到如图4-34所示的结果。这是Hadoop系统自带的Web监测软件,能够提供丰富的系统状态信息。

HDFS的概要信息:

HDFS的启动过程:

值得指出的是,早先版本的Hadoop(3.0版本以前),其Web监测的URL是“http://master:50070/”,Hadoop 3.1的端口号更改为9870了。这种变化也给一些初学者带来了困惑,很多人继续使用“http://master:50070/”,结果打不开网页,还以为是在安装时出了问题。
SecondaryNameNode的Web Console:

另外,除了Hadoop自带的监测软件,在实际生产中,人们更多地使用专业的监测软件。例如,Ganglia 是 UC Berkeley 发起的一个开源监测项目,能够监测数以千计的节点,每台计算机都运行一个收集和发送度量数据(如处理器速度、内存使用量等)的名为 gmond 的守护进程;gmond的系统开销非常少,因此具有良好的可扩展性。又如,Hue是一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,目前已经由Cloudera公司贡献给Apache基金会的Hadoop社区,是基于Python Web框架Django实现的。Hue通过Web控制台与Hadoop集群进行交互,并提供数据处理与分析功能,如操作HDFS上的数据、运行MapReduce程序、执行Hive的SQL语句、浏览HBase数据库等。
同样,在Firefox浏览器的地址栏中输入http://master:18088,可以监测Yarn的运行情况,这实际上是Hadoop平台上对应用状态进行监测的基本组件。

利用Web界面监测Yarn的运行状态
注意:执行stop-yarn.sh命令来关闭Hadoop集群不要再使用stop-all.sh这样的命令了。切到对应的安装用户进行关闭
1.6 hadoop-daemon.sh的使用

启动文件“hadoop-daemon.sh”,使用“hadoop-daemon.sh“脚本启动和停止hadoop后台程序。它可以做到在A机器上启动”namenode“,B机器启动”secondarynamenode“ C机器启动”datanode“, ”tasktracker“,具体启动如下 :
./hadoop-daemon.sh start namenode
./hadoop-daemon.sh start secondarynamenode
./hadoop-daemon.sh start jobtracker
./hadoop-daemon.sh start datanode
./hadoop-daemon.sh start tasktracker
如果要停止可以运行如下命令
./hadoop-daemon.sh stop namenode
./hadoop-daemon.sh stop secondarynamenode
./hadoop-daemon.sh stop jobtracker
./hadoop-daemon.sh stop datanode
./hadoop-daemon.sh stop tasktracker
2 HDFS常用的操作命令
调用文件系统(FS)Shell命令应使用 bin/hadoop fs<args>的形式。 所有的的FS shell命令使用URI路径作为参数。URI格式是scheme://authority/path。对HDFS文件系统,scheme是hdfs,对本地文件系统,scheme是file。其中scheme和authority参数都是可选的,如果未加指定,就会使用配置中指定的默认scheme。一个HDFS文件或目录比如*/parent/child可以表示成hdfs://namenode:namenodeport/parent/child,或者更简单的/parent/child(假设你配置文件中的默认值是namenode:namenodeport*)。大多数FS Shell命令的行为和对应的Unix Shell命令类似,不同之处会在下面介绍各命令使用详情时指出。出错信息会输出到stderr,其他信息输出到stdout。

cat
使用方法:hadoop fs -cat URI [URI …]
将路径指定文件的内容输出到stdout。
示例:
- hadoop fs -cat hdfs://host1:port1/file1 hdfs://host2:port2/file2
- hadoop fs -cat file:///file3 /user/hadoop/file4
返回值:
成功返回0,失败返回-1。
chgrp
使用方法:hadoop fs -chgrp [-R] GROUP URI [URI …] Change group association of files. With -R, make the change recursively through the directory structure. The user must be the owner of files, or else a super-user. Additional information is in the Permissions User Guide. -->
改变文件所属的组。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见HDFS权限用户指南。
chmod
使用方法:hadoop fs -chmod [-R] <MODE[,MODE]… | OCTALMODE> URI [URI …]
改变文件的权限。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见HDFS权限用户指南。
chown
使用方法:hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
改变文件的拥有者。使用-R将使改变在目录结构下递归进行。命令的使用者必须是超级用户。更多的信息请参见HDFS权限用户指南。
copyFromLocal
使用方法:hadoop fs -copyFromLocal URI
除了限定源路径是一个本地文件外,和put命令相似。
copyToLocal
使用方法:hadoop fs -copyToLocal [-ignorecrc] [-crc] URI
除了限定目标路径是一个本地文件外,和get命令类似。
cp
使用方法:hadoop fs -cp URI [URI …]
将文件从源路径复制到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。
示例:
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
返回值:
成功返回0,失败返回-1。
du
使用方法:hadoop fs -du URI [URI …]
显示目录中所有文件的大小,或者当只指定一个文件时,显示此文件的大小。
示例:
hadoop fs -du /user/hadoop/dir1 /user/hadoop/file1 hdfs://host:port/user/hadoop/dir1
返回值:
成功返回0,失败返回-1。
dus
使用方法:hadoop fs -dus
显示文件的大小。
expunge
使用方法:hadoop fs -expunge
清空回收站。请参考HDFS设计文档以获取更多关于回收站特性的信息。
get
使用方法:hadoop fs -get [-ignorecrc] [-crc]
复制文件到本地文件系统。可用-ignorecrc选项复制CRC校验失败的文件。使用-crc选项复制文件以及CRC信息。
示例:
- hadoop fs -get /user/hadoop/file localfile
- hadoop fs -get hdfs://host:port/user/hadoop/file localfile
返回值:
成功返回0,失败返回-1。
getmerge
使用方法:hadoop fs -getmerge [addnl]
接受一个源目录和一个目标文件作为输入,并且将源目录中所有的文件连接成本地目标文件。addnl是可选的,用于指定在每个文件结尾添加一个换行符。
ls
使用方法:hadoop fs -ls
如果是文件,则按照如下格式返回文件信息:
文件名 <副本数> 文件大小 修改日期 修改时间 权限 用户ID 组ID
如果是目录,则返回它直接子文件的一个列表,就像在Unix中一样。目录返回列表的信息如下:
目录名
示例:
hadoop fs -ls /user/hadoop/file1 /user/hadoop/file2 hdfs://host:port/user/hadoop/dir1 /nonexistentfile
返回值:
成功返回0,失败返回-1。
lsr
使用方法:hadoop fs -lsr
ls命令的递归版本。类似于Unix中的ls -R。
mkdir
使用方法:hadoop fs -mkdir
接受路径指定的uri作为参数,创建这些目录。其行为类似于Unix的mkdir -p,它会创建路径中的各级父目录。
示例:
- hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
- hadoop fs -mkdir hdfs://host1:port1/user/hadoop/dir hdfs://host2:port2/user/hadoop/dir
返回值:
成功返回0,失败返回-1。
movefromLocal
使用方法:dfs -moveFromLocal
输出一个”not implemented“信息。
mv
使用方法:hadoop fs -mv URI [URI …]
将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。不允许在不同的文件系统间移动文件。
示例:
- hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -mv hdfs://host:port/file1 hdfs://host:port/file2 hdfs://host:port/file3 hdfs://host:port/dir1
返回值:
成功返回0,失败返回-1。
put
使用方法:hadoop fs -put …
从本地文件系统中复制单个或多个源路径到目标文件系统。也支持从标准输入中读取输入写入目标文件系统。
- hadoop fs -put localfile /user/hadoop/hadoopfile
- hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
- hadoop fs -put localfile hdfs://host:port/hadoop/hadoopfile
- hadoop fs -put - hdfs://host:port/hadoop/hadoopfile
从标准输入中读取输入。
返回值:
成功返回0,失败返回-1。
rm
使用方法:hadoop fs -rm URI [URI …]
删除指定的文件。只删除非空目录和文件。请参考rmr命令了解递归删除。
示例:
- hadoop fs -rm hdfs://host:port/file /user/hadoop/emptydir
返回值:
成功返回0,失败返回-1。
rmr
使用方法:hadoop fs -rmr URI [URI …]
delete的递归版本。
示例:
- hadoop fs -rmr /user/hadoop/dir
- hadoop fs -rmr hdfs://host:port/user/hadoop/dir
返回值:
成功返回0,失败返回-1。
setrep
使用方法:hadoop fs -setrep [-R]
改变一个文件的副本系数。-R选项用于递归改变目录下所有文件的副本系数。
示例:
- hadoop fs -setrep -w 3 -R /user/hadoop/dir1
返回值:
成功返回0,失败返回-1。
stat
使用方法:hadoop fs -stat URI [URI …]
返回指定路径的统计信息。
示例:
- hadoop fs -stat path
返回值:
成功返回0,失败返回-1。
tail
使用方法:hadoop fs -tail [-f] URI
将文件尾部1K字节的内容输出到stdout。支持-f选项,行为和Unix中一致。
示例:
- hadoop fs -tail pathname
返回值:
成功返回0,失败返回-1。
test
使用方法:hadoop fs -test -[ezd] URI
选项:
-e 检查文件是否存在。如果存在则返回0。
-z 检查文件是否是0字节。如果是则返回0。
-d 如果路径是个目录,则返回1,否则返回0。
示例:
- hadoop fs -test -e filename
text
使用方法:hadoop fs -text
将源文件输出为文本格式。允许的格式是zip和TextRecordInputStream。
touchz
使用方法:hadoop fs -touchz URI [URI …]
创建一个0字节的空文件。
示例:
- hadoop -touchz pathname
返回值:
成功返回0,失败返回-1。
3 hdfs的高级使用命令
3.1 HDFS文件限额配置
在多人共用HDFS的环境下,配置设置非常重要。特别是在Hadoop处理大量资料的环境,如
果没有配额管理,很容易把所有的空间用完造成别人无法存取。Hdfs的配额设定是针对目录
而不是针对账号,可以 让每个账号仅操作某一个目录,然后对目录设置配置。
hdfs文件的限额配置允许我们以文件个数,或者文件大小来限制我们在某个目录下上传的文
件数量或者文件内容总量,以便达到我们类似百度网盘网盘等限制每个用户允许上传的最大
的文件的量。
hdfs dfs -count -q -h /user/root/dir1 #查看配额信息
3.2 数量限额
hdfs dfs -mkdir -p /user/root/dir #创建hdfs文件夹
hdfs dfsadmin -setQuota 2 dir # 给该文件夹下面设置最多上传两个文件,发现只能上传一个文件
3.3 空间大小限额
在设置空间配额时,设置的空间至少是block_size * 3大小
hdfs dfsadmin -setSpaceQuota 4k /user/root/dir # 限制空间大小4KB
hdfs dfs -put /root/a.txt /user/root/dir
生成任意大小文件的命令:
dd if=/dev/zero of=1.txt bs=1M count=2 #生成2M的文件
清除空间配额限制
hdfs dfsadmin -clrSpaceQuota /user/root/dir
3.4 HDFS的管理命令

3.5 hdfs的安全模式
安全模式是hadoop的一种保护机制,用于保证集群中的数据块的安全性。当集群启动的时候,会首先进入安全模式。当系统处于安全模式时会检查数据块的完整性。假设我们设置的副本数(即参数dfs.replication)是3,那么在datanode上就应该有3个副本存在,假设只存在2个副本,那么比例就是2/3=0.666。hdfs默认的副本率0.999。我们的副本率0.666明显小于0.999,因此系统会自动的复制副本到其他dataNode,使得副本率不小于0.999。如果系统中有5个副本,超过我们设定的3个副本,那么系统也会删除多于的2个副本。在安全模式状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。在,当整个系统达到安全标准时,HDFS自动离开安全模式。安全模式操作命令
hdfs dfsadmin -safemode get #查看安全模式状态
hdfs dfsadmin -safemode enter #进入安全模式
hdfs dfsadmin -safemode leave #离开安全模式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号