Spark Yarn模式部署集群
目录
1 安装地址
http://archive.apache.org/dist/spark/spark-2.4.0/
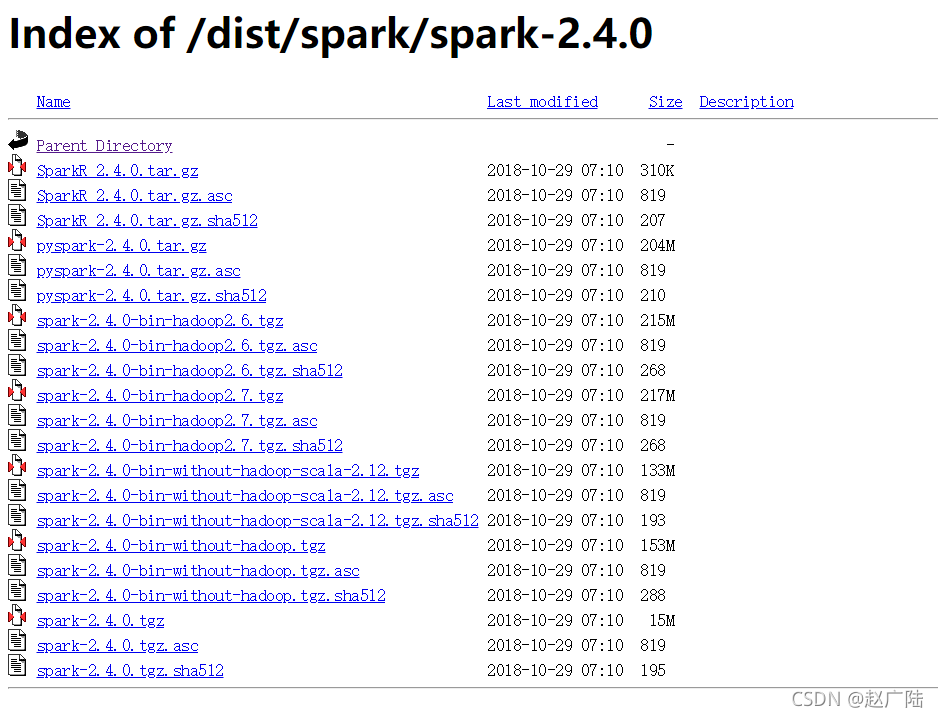
2 解压安装
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz


2.1 配置Linux环境变量
#spark
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
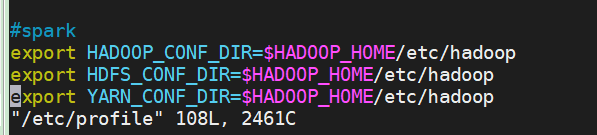
source /etc/profile
export SPARK_MASTER_IP=192.168.99.129
export JAVA_HOME=/usr/local/jdk1.8.0_171/
export SCALA_HOME=/home/csu/scala-2.11.8/
2.2 scala环境配置
tar -zxvf scala-2.11.8.tgz
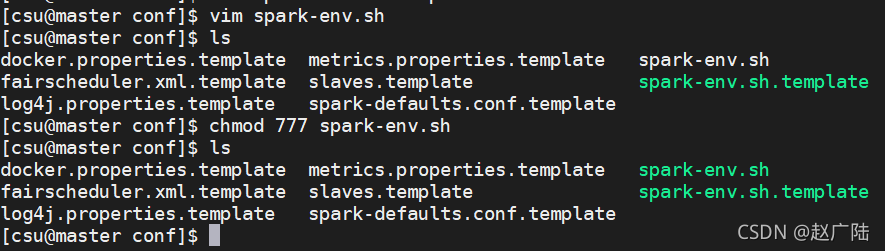
2.3 配置spark-env.sh环境变量
vim spark-env.sh
chmod 777 spark-env.sh

2.4 配置slaves文件

cp slaves.template slaves
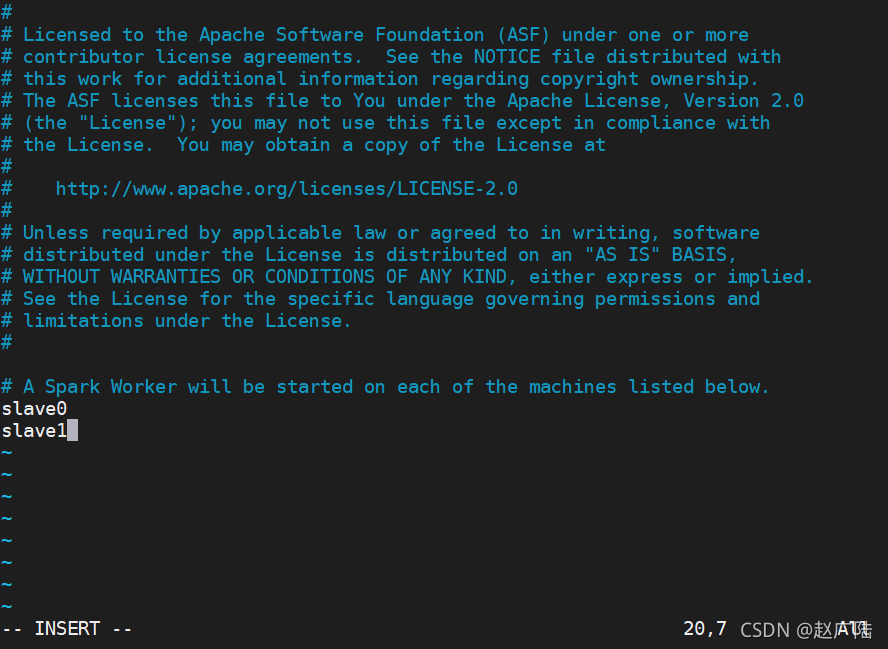
slave0
slave1
2.5 将安装好的Spark复制到Slave
执行scp -r ~/spark-2.4.0-bin-hadoop2.7 slave0:~/命令,将Master上的Spark安装目录复制到Slave和Slave 1
3 启动并验证Spark
在Master上,进入Spark安装目录,执行“sbin/start-all.sh”命令即可启动Spark。
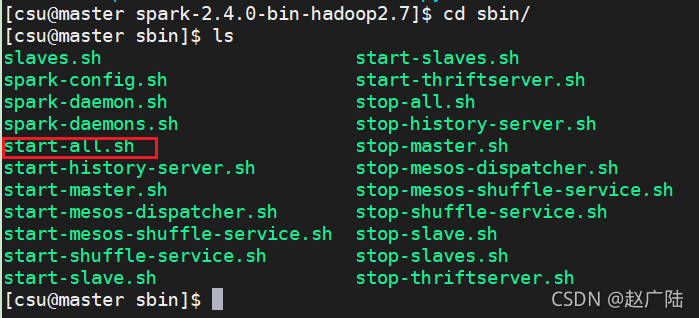
读者可能注意到,启动Spark的命令与启动Hadoop的命令一样,都是“start-all.sh”。但是,当用户明确指定目录时,就可以区分这两个不同的命令了。由于这里已经进入了Spark的安装目录,并且在“start-all.sh”前面加上了“sbin”,这就确保了执行的是启动Spark的命令;如果没有“sbin”目录的限制,而是简单地使用“start-all.sh”,则是启动Hadoop的命令。
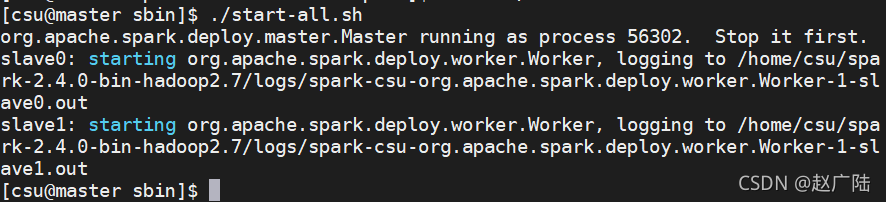
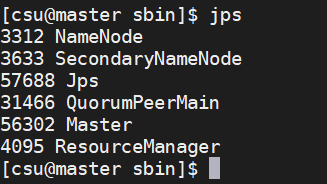
启动后,我们可以通过“jps”命令查看Master和Slave上Spark的进程,可以看到,在Master上增加了一个Master进程,它就是Spark的主控进程。
Slave0上的Spark的Worker进程
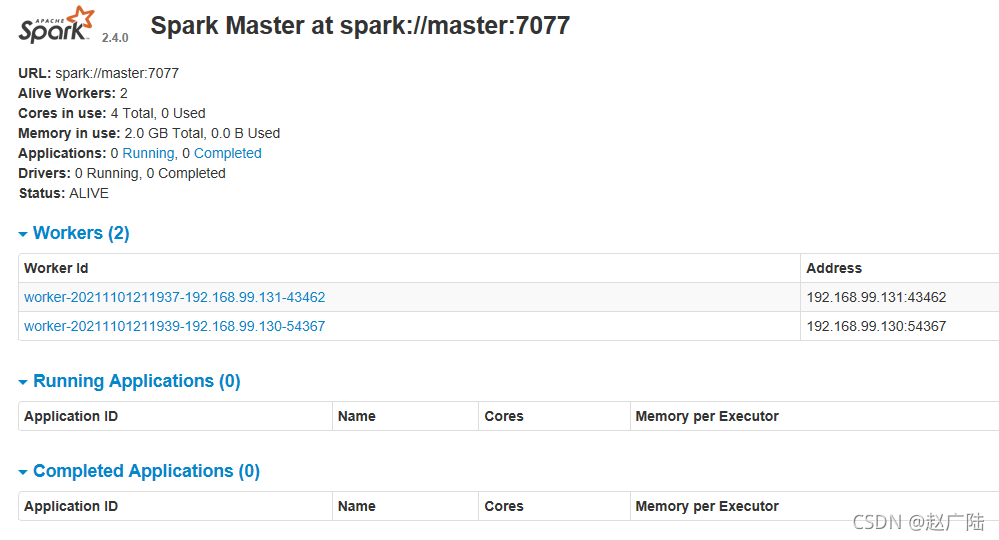
我们也可以通过Spark提供的Web接口查看系统状态。打开Master(也可以是任何其他节点)上的浏览器,在地址栏输入“http://master:8080”,可看到的监控界面。
http://192.168.99.129:8080/
要退出Spark,可以在进入Spark安装目录后执行“sbin/stop-all.sh”命令。
stop-all.sh
