

基于tensorflow的神经网络与深度学习实践
最近在deeplearning.ai上学习神经网络,做了一些试验,有一些感悟,记录下来,学习分享:
一、神经网络
神经网络:Neural Networks,是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型
1,神经元
神经元能感受环境的变化,并传递信息到下一个神经元;人脑有860亿个神经元
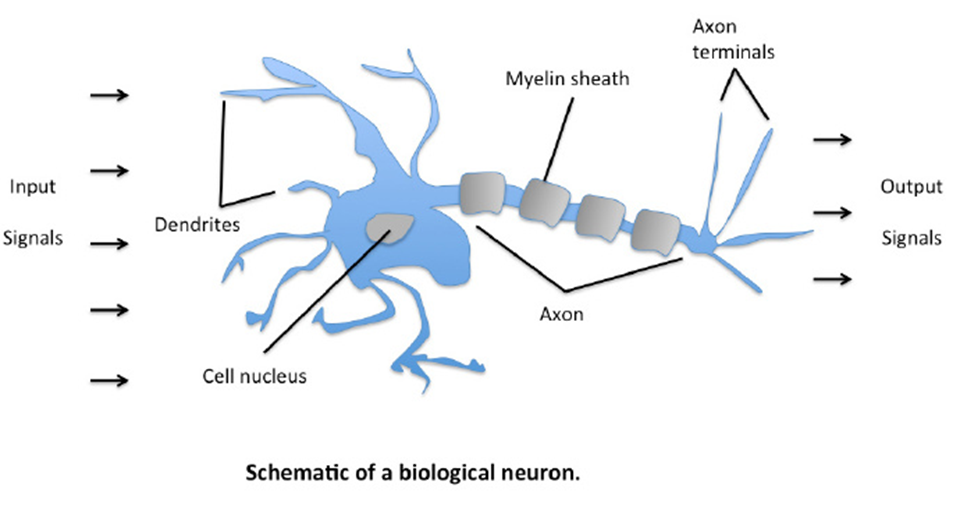
2,进化理论

6亿年前,地球上开始出现生物,但什么都做不了,问题在于大家都没有神经
没有神经,不能动,也处理不了任何信息,只能默默存在,直到死去
后来,水母出现了,水母发现必须要有神经,于是它拥有了世界上第一套神经系统——神经网络
水母的神经网络使它可以从周围世界里收集重要信息,比如哪里有掠食者和食物,然后把这一信息传到身体的各个部位
这意味着水母可以应对环境的变化来提高生存几率,而不仅仅是漫无目的漂着,祈求好运
3,深度学习

介绍一位先驱:2006年,Geoffrey Hinton等人率先提出了深度学习,使用“深度”这个词。
引入一个叫greedy layer wise pre-training策略,其他研究者发现这个对训练更深层度的神经网络很有效,由此引发了一波热潮。
不过业界有一种观点是——他们这样做是为了申请科研经费
4,吴恩达的观点

大神观点也有矛盾的时候,当然,这一定是有原因的:
这就是深度学习,Ng实践了深度学习的效果,认识到深度学习的基础“神经网络”的重要性。这就是他在后面重点介绍神经网络的原因。
二、深度学习的兴起

原因是:数据、计算力、算法
(1)算法:近20年不断创新,很多创新是为了计算的更快(比如sigmoid函数演进为Relu函数)
(2)sigmoid函数在尾端,梯度非常小,近似为0,这样采用梯度下降法的时候,参数的变化会非常小,训练非常慢
(3)快速计算很重要:idea--code--experiment,快速验证迭代
传统机器学习方法,如向量机SVM,在处理少量数据时,随着数据量增加,性能会增加;但是达到一定数据量的时候就会遇到瓶颈;
那如何达到很好的“表现性能“呢:第一需要大型的神经网络,第二需要许多的数据
训练数据集大小对性能的影响:
1,当数据集小:如svm表现的好,很可能是手工设计组件的技能比较高
2,当数据集大:神经网络才会稳定的领先其他算法
三、行业应用
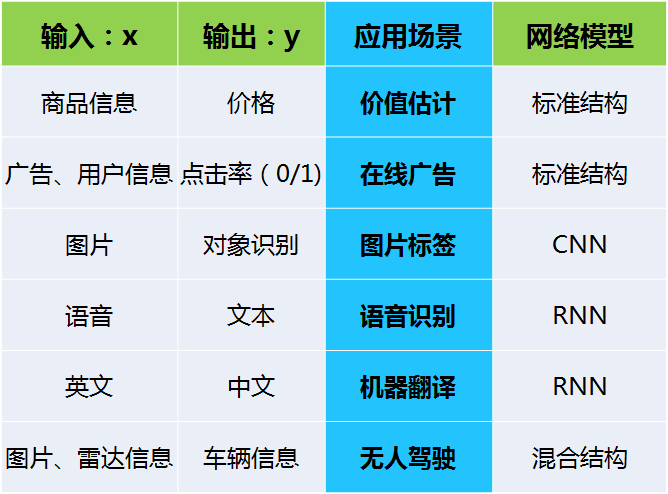
(1)监督学习
夸大深度学习的声音从未停止,但其中产生经济效益的目前只有机器学习中的监督学习
(2)非结构化数据
早期产生经济效益的场景是结构化数据的领域;需要感谢深度学习和神经网络,让人们可以在图像、语音领域(非结构化数据)取得进展
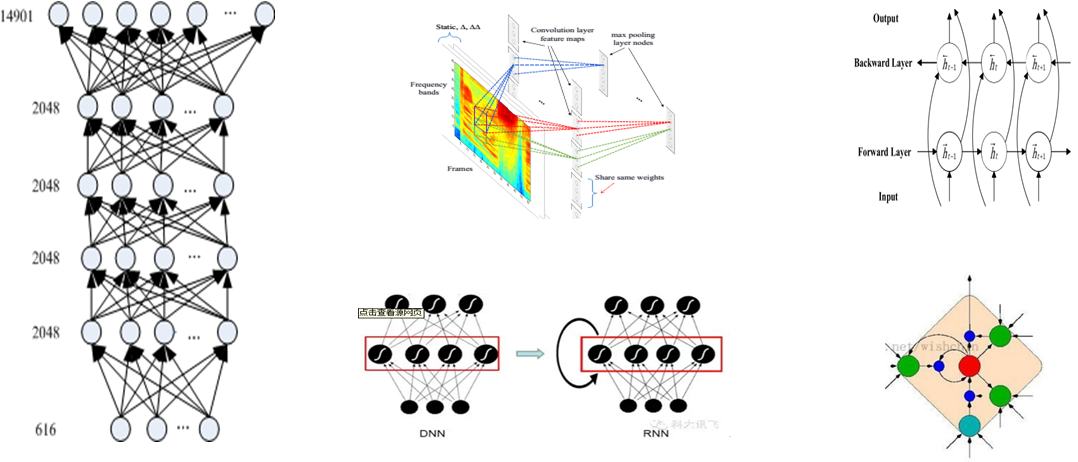
四、神经网络的常见结构
这一块大家应该比较熟悉,仅作复习展示:
深度神经网络结构:DNN,CNN,RNN,LSTM,BLSTM
五、应用神经网络的深度学习系统是如何工作的
举一个价格预测的例子:
已知房屋的面积,希望预测房屋的价格,房屋面积-价格:通过一个线性函数来拟合;
神经网络的神奇之处在于:只要给到足够的(x,y),就能计算出精准的映射函数。
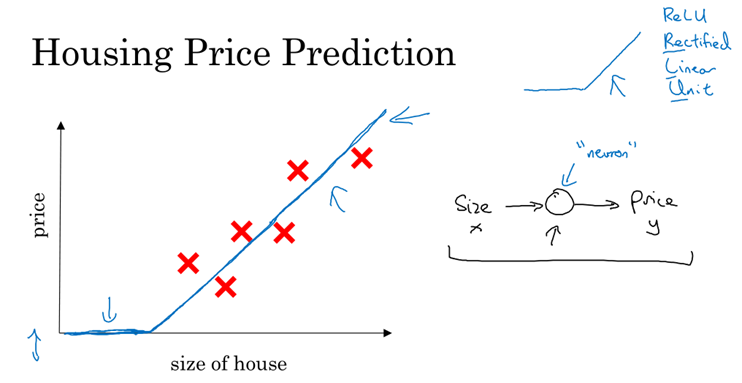
我们的任务是:对于给定的x和y,找到拟合函数
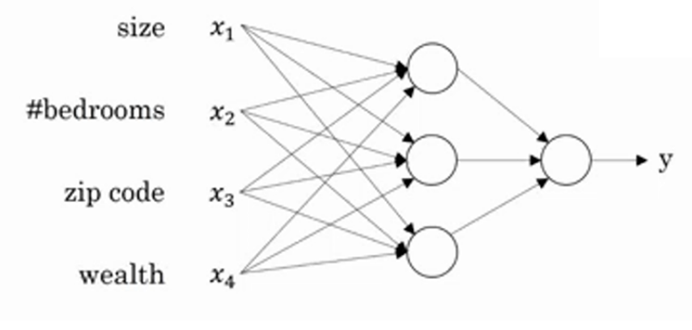
下面我们扩大房屋价格的影响因素:面积、房型、地段、周边配套
X:x1、x2、x3、x4…… 当输入条件变的更多:n维向量
隐藏层:如果仅仅做线性映射,输出永远是X的线性变换,表达能力不够
激活函数:非线性变换函数,目的是为了提取更高维度的特征,see more
为了保证输出的有意义:二元分类应用,会在输出层做归一化(softmax函数)
六、demo验证
我们基于下列实验环境:python+tensorflow,验证上述预测模型是否可以正确的工作,工具环境:
1,tensorflow
Google推出的、开源深度学习工具
第二代学习平台,提升工作的效率(第一代系统DistBelief在可扩缩性上表现很好,但在用于研究时灵活性达不到预期)
分成CPU和GPU两个版本
底层C++来写的,前端支持C++、Python,内部已开始支持Go
支持运行在各个硬件平台上,包括手机、PC、服务器集群上
工具:Tensorboard,web界面,调试工具
2,Anaconda
Anaconda 是一种Python语言的开源发行版,用于进行大规模数据处理, 预测分析, 和科学计算, 简化包的管理和部署
官网:https://www.anaconda.com/download/
预装了很多第三方库,比如pip
推荐Python 3.6,包含科学计算环境,Python 2.x包中没有
pip命令安装tensorflow注意事项:安装anaconda之后,使用pip工具安装tensorflow的命令:pip --proxy 10.14.87.100:8080 install tensorflow (安装cpu版本);需在http://auth-proxy.oa.com/DevNetTempVisit.aspx申请临时外网权限
3,Jupyter Notebook
Jupyter Notebook(此前被称为 IPython notebook)是一个交互式笔记本,支持运行 40 多种编程语言。
适合数据分析的 处理-计算-分析 的过程
Python带来的丰富的第三方包支持,不需要自己再重复造轮子
正在逐步丰富的功能,比如多个cell的剪切/粘贴,PPT放映, cell tag
4,神经网络设计
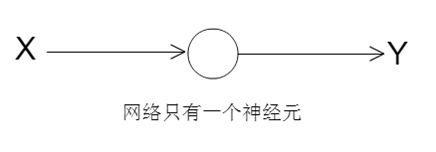
训练一个最简单的神经网络
只有一个神经元
输入:X(1,n)
输出:Y(1,n)
目标:是通过training迭代训练,让拟合函数的参数(w、b)收敛
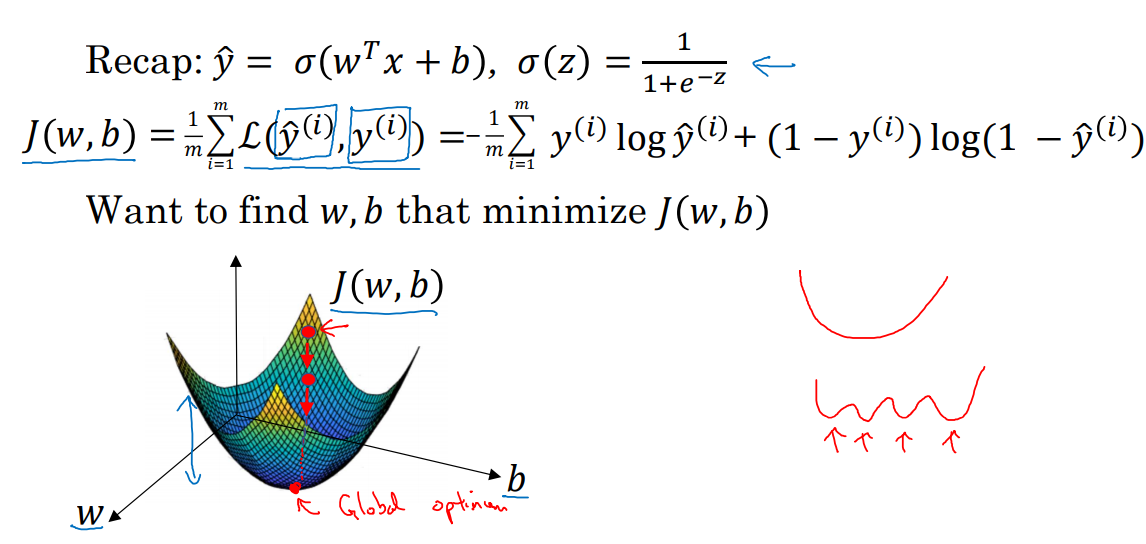
在一个比较深的神经网络下,参数w、b按照每次正向传播的结果计算出L,
求导(使得梯度下降最快)后再通过反向传播,逐层更新(反向),
完成一次迭代(或者叫训练)西格玛激活函数,m个样本;
梯度下降法求的是极小值,而不是最小值;
注意:步长的选取很关键,步长过长达不到极值点甚至会发散,步长太短导致收敛时间过长。
参数更新:
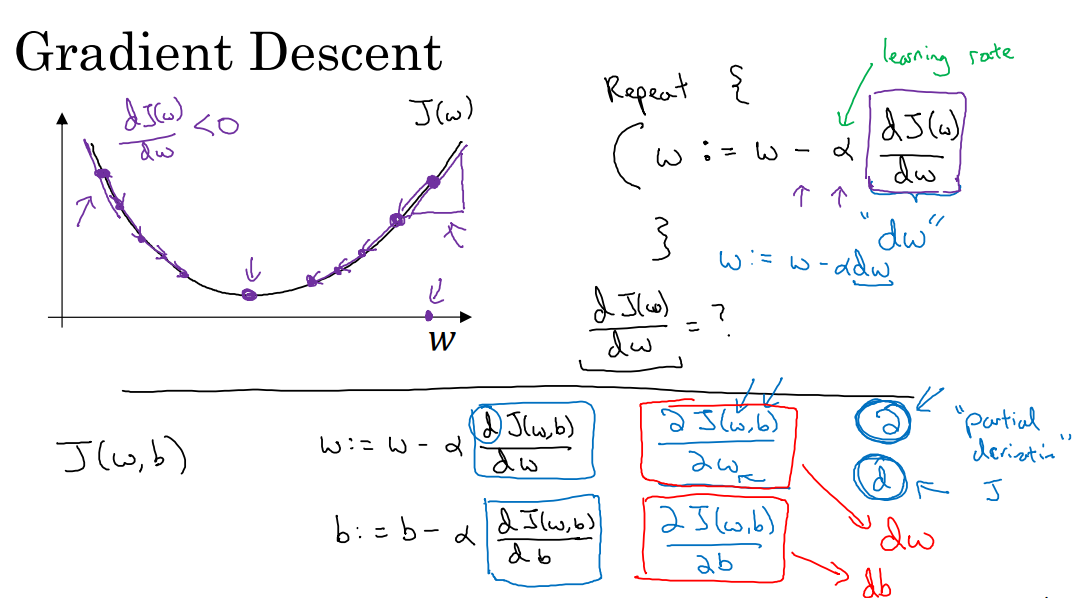
一般训练过程小结:

总结一下:应用神经网络的深度学习系统的大致工作步骤分为:
1,正向传播:计算损失函数
2,反向传播更新网络参数
3,重复1/2环节,不断迭代实现的
附:另一个demo,Mnist手写数字分类预测
上述实验觉得不过瘾,再来看一个MNIST实验:
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据。
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:
Training set images: train-images-idx3-ubyte.gz ( 60,000 个样本)
Training set labels: train-labels-idx1-ubyte.gz ( 60,000 个标签)
Test set images: t10k-images-idx3-ubyte.gz ( 10,000 个样本)
Test set labels: t10k-labels-idx1-ubyte.gz ( 10,000 个标签)
我们可以对这些图片进行可视化处理:

以数字6举例,大概长这个样子:

我们的任务是训练神经网络,用来识别手写数字。
下面是jupyter环境下的mnist实验的实际代码,具体参数可调,有兴趣的可以下载数据集后参照调试:
#!/usr/bin/python3.5
# -*- coding: utf-8 -*-
#上述代码的实现思路如下:
#1.读入mnist手写体数据;
#2.把数据的值从[0,1]浮点范围转化为黑白格式(背景为0-黑色,前景为255-白色);
#3.根据mnist.train.labels的内容,生成数字索引,也就是建立每一张图片和其所代表数字的关联,由此创建对应的保存目录;
#4.循环遍历mnist.train.images,把每张图片的像素赋值给PIL的Image类实例,再调用Image类的save方法把图片保存在第3步骤中创建的对应目录。
#运行结果:在当前目录下生成mnist_digits_images目录,里面包含了mnist的真实图片
import os
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from PIL import Image
# 声明图片宽高
rows = 28
cols = 28
# 要提取的图片数量
images_to_extract = 8000
# 当前路径下的保存目录
save_dir = "./mnist_digits_images"
# 读入mnist数据
mnist = input_data.read_data_sets("/ai-data/mnist", one_hot=False)
# 创建会话
sess = tf.Session()
# 获取图片总数
shape = sess.run(tf.shape(mnist.train.images))
images_count = shape[0]
pixels_per_image = shape[1]
# 获取标签总数
shape = sess.run(tf.shape(mnist.train.labels))
labels_count = shape[0]
# mnist.train.labels是一个二维张量,为便于后续生成数字图片目录名,有必要一维化(后来发现只要把数据集的one_hot属性设为False,mnist.train.labels本身就是一维)
#labels = sess.run(tf.argmax(mnist.train.labels, 1))
labels = mnist.train.labels
# 检查数据集是否符合预期格式
if (images_count == labels_count) and (shape.size == 1):
print ("数据集总共包含 %s 张图片,和 %s 个标签" % (images_count, labels_count))
print ("每张图片包含 %s 个像素" % (pixels_per_image))
print ("数据类型:%s" % (mnist.train.images.dtype))
# mnist图像数据的数值范围是[0,1],需要扩展到[0,255],以便于人眼观看
if mnist.train.images.dtype == "float32":
print ("准备将数据类型从[0,1]转为binary[0,255]...")
for i in range(0,images_to_extract):
for n in range(pixels_per_image):
if mnist.train.images[i][n] != 0:
mnist.train.images[i][n] = 255
# 由于数据集图片数量庞大,转换可能要花不少时间,有必要打印转换进度
if ((i+1)%50) == 0:
print ("图像浮点数值扩展进度:已转换 %s 张,共需转换 %s 张" % (i+1, images_to_extract))
# 创建数字图片的保存目录
for i in range(10):
dir = "%s/%s/" % (save_dir,i)
if not os.path.exists(dir):
print ("目录 ""%s"" 不存在!自动创建该目录..." % dir)
os.makedirs(dir)
# 通过python图片处理库,生成图片
indices = [0 for x in range(0, 10)]
for i in range(0,images_to_extract):
img = Image.new("L",(cols,rows))
for m in range(rows):
for n in range(cols):
img.putpixel((n,m), int(mnist.train.images[i][n+m*cols]))
# 根据图片所代表的数字label生成对应的保存路径
digit = labels[i]
path = "%s/%s/%s.bmp" % (save_dir, labels[i], indices[digit])
indices[digit] += 1
img.save(path)
# 由于数据集图片数量庞大,保存过程可能要花不少时间,有必要打印保存进度
if ((i+1)%50) == 0:
print ("图片保存进度:已保存 %s 张,共需保存 %s 张" % (i+1, images_to_extract))
else:
print ("图片数量和标签数量不一致!")

