《深入理解计算机系统》阅读笔记--程序的机器级表示(上)
一、为什么要学习和了解汇编
编译器基于编程语言的规则,目标机器的指令集和操作系统遵循的惯例,经过一系列的阶段生成机器代码。GCC c语言编译器以汇编代码的形式产生输出,汇编代码是机器代码的文本表示,给出程序中的每一条指令。然后GCC调用汇编和链接器,根据汇编代码生成可执行的机器代码。这一章节其实就是来更加深入的认识和理解汇编代码
现在我们更多接触的都是一些高级语言,如JAVA,GO,Python,其实用这些语言的时候,更大程度上,已经屏蔽了一些程序的细节,即机器级的实现。但是如果是用汇编语言,程序员就必须制定程序用来执行计算的低级指令。
那么为什么我们还要学习和了解汇编呢? 虽然现在编译器已经替我们做了生成汇编代码的大部分工作,但是作为程序员,如果我们能够阅读和理解汇编代码将是一个非常重要的技能,好处是:
能够理解编译器的优化能力分析代码中隐含的低效率
如我们通过线程包写并发程序时,了解不同线程是如何共享程序数据或保持数据私有的,以及准确知道如何在哪里访问共享数据,这些在机器代码都是可见的
二、历史
Inter的处理器系统俗称x86,第一代处理器是8086,一个单芯片,16位微处理器,主要为 IBM PC 和 DOS 设计,有 1MB 的地址空间。八年后的 1985,第一个 32 位 Intel 处理器(IA32) 386 诞生。2004 年,奔腾(Pentium) 4E 成为了第一个 64 位处理器(x86-64)。2006 年 Core 2 成为了第一个多核 Intel 处理器。
三、程序编码
假如我们有一个c程序,有两个文件p1.c 和p2.c 我们通常编译的时候是通过如下命令:
gcc -0g -o p p1.c p2.c
GCC是linux上默认的编译器,-0g 告诉编译器使用会生成符合原始C代码整体结构的机器代码来优化等级。
GCC命令调用了一整套的程序,将源代码转换为可执行代码:
C预处理器扩展源代码,插入所有用#include 命令指定的文件,并扩展所有用#define声明制定的宏。
编译器产生两个源文件的汇编代码,名字分别为p1.s 和p2.s
汇编器会将汇编代码转换为二进制目标文件p1.o 和p2.o
链接器将两个目标代码文件与实现库函数的代码合并,并最终生成可执行文件p
对于机器级编程,有两个重要的抽象:
由指令集体系结构或指令集架构(Instruction Set Architecture, ISA)来定义机器级程序的格式和行为,它定义了处理器状态,指令的格式,以及每条指令对状态的影响。
机器级程序使用的内存地址是虚拟地址,提供的内存模型看上去是一个非常大的数组。
x86-64的机器代码和原始的C代码差别非常大,一些通常对C语言程序隐藏处理状态都是可见的:
程序计数器(PC,在x86-64中用%rip表示)给出将要执行的下一条指令在内存中的地址
整数寄存器文件包含16个命令的位置,分别存储64位的值,这些寄存器可以存储地址或者整数数据。有的寄存器用于记录某些重要的程序状态,而其他的寄存器用来保存临时数据。
条件码寄存器保存着最近执行的算术或逻辑指令的状态信息。用来实现控制或数据流中的条件变化
一组向量寄存器可以存放一个或多个整数或者浮点数值
程序内存包含:程序的可执行机器代码,操作系统需要一些信息,用来管理过程调用和返回的运行时栈,以及用户分配的内存块
先看一个代码编译实例:
long mult2(long,long); void multstore(long x, long y, long *dest){ long t = mult2(x, y); *dest = t; }
通过gcc -Og -S mstore.c, 我们就得到了一个mstore.s
mstore.s的内容如下:
pushq %rbx movq %rdx, %rbx call mult2 movq %rax, (%rbx) popq %rbx ret
通过gcc -Og -c mstore.c 我们可以得到它的二进制格式,其实这个我们无法直接查看,要查看机器代码文件的内容,可以通过objdump查看,如下所示:
root@localhost /app/c_codes objdump -d mstore.o mstore.o: file format elf64-x86-64 Disassembly of section .text: 0000000000000000 <multstore>: 0: 53 push %rbx 1: 48 89 d3 mov %rdx,%rbx 4: e8 00 00 00 00 callq 9 <multstore+0x9> 9: 48 89 03 mov %rax,(%rbx) c: 5b pop %rbx d: c3 retq
上述一些关于机器代码和它的反汇编表示的特性值得注意:
x86-64的指令长度从1-15个不等
设计指令格式的方式是,从某个给定位置开始,可以将字节唯一地解码成机器指令,如上述中,只有指令pushq %rbx 是以字节值53开头
反汇编器只是基于机器代码文件中的字节序列来确定汇编码,不需要访问该程序的源代码或汇编代码
反汇编器使用指令命令规则与GCC生成的汇编代码使用的有些区别,在上面的示例中,它省略了很多指令结尾的q,这些后缀是大小指示符,可以省略
四、数据格式
由于是从16位体系结构扩展成32位的,字(word)表示16位数据类型,因此,32位数为双子,64位称为四字
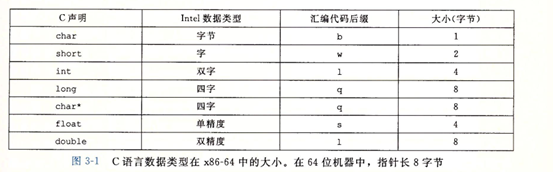
浮点数主要有两种形式:单精度(4字节)值,。对应C语言数据类型float;双精度(8字节)值,对应于c语言数据类型double
五、访问信息
一个x86-64的中央处理单元包含一组16个存储64位值的通用目的寄存器。这些寄存器用来存储整数数据和指针如下图:

这里的名字都是以%r开头 ,不过后面也包含了一些不同的命名规则,这是历史演化造成的。
最早的8086中有8个16位的寄存器,即上图中的%ax到%bp,当扩展到IA32架构时,这些寄存器也扩展成了32位寄存器,标号从%eax到%ebp,当扩展到x86-64后,原来的8个寄存器扩展为64位,标号从%rax到%rbp,除此之外还增加了8个新的寄存器,标号从%r8到%r15
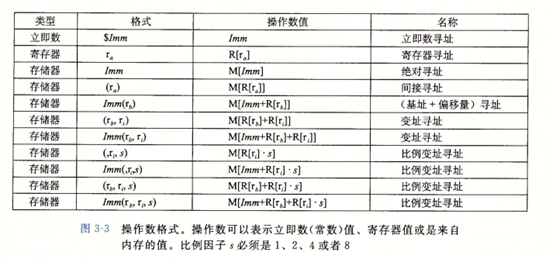
操作数指示符
大多数指令有一个或多个操作数,指示出执行一个操作中要使用的源数据值,以及放置结果的目的位置。源数据可以以常数形式给出,或者从寄存器或内存中读出,结果可以存放在寄存器或者内存中,因此各种不同的操作数的可能性被分为三种类型:
立即数:用来表示常数值。即$后面跟一个用标准C表示法表示的整数
寄存器:表示某个寄存器的内容,16个寄存器的低位1字节,2字节,4字节,或者8字节中的一个作为操作数分别对应于8位,16位,32位,或64位。
内存引用:根据计算出来的地址访问某个内存位置
下图是多种不同的寻址方式:
数据传送指令
最频繁使用的指令是将数据从一个位置复制到另一个位置的指令,最简单形式的数据传送指令是MOV类,MOV类由四条指令组成:movb,movw,movl和movq. b,w,l,q分别是1、2、4和8字节
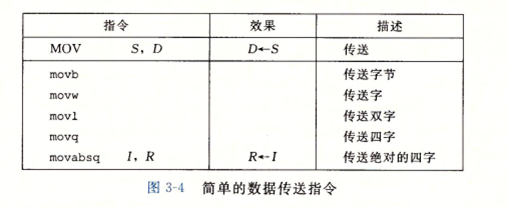
源操作数指定的值是一个立即数,存储在寄存器中或者内存中,目的操作数指定一个位置,要么是一个内存地址。而在x86-64中增加一个限制,传送指令的两个操作数不能都指向内存位置。
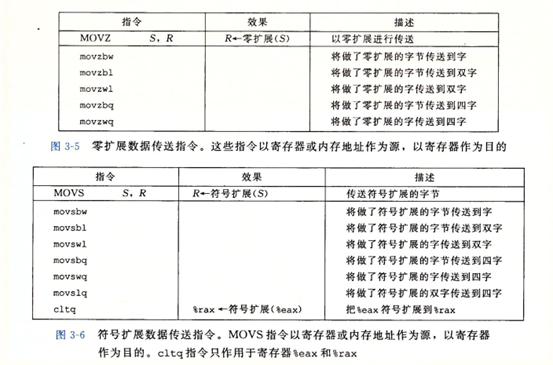
上图中记录的是两类数据移动指令,在将较小的源值赋值到较大的目的的时候使用,所有这些指令都把数据从源(在寄存器或内存中)复制到目的寄存器。MOVZ 类中的指令把目的中剩余的字节填充为0而MOVS类中的指令通过符号扩展来填充,把源操作的最高位进行复制
数据传送的代码示例
将下面代码,通过gcc -Og -S exchange.c 生成汇编代码
long exchange(long *xp,long y) { long x = *xp; *xp = y; return x; }
汇编代码如下:
exchange:
movq (%rdi), %rax
movq %rsi, (%rdi)
ret
从上面的汇编代码可以看出,函数exchange由三个指令实现:两个数据传送movq,加上一条返回函数被调用点的指令(ret).
过程描述为:
参数xp和y分别存储在寄存器%rdi 和%rsi中
movq (%rdi), %rax :这个指令是从内存中读x,把它放到寄存器%rax中,直接实现了c程序代码中x = *xp。稍后用寄存器%rax 从这个函数返回一个值,因而返回值就是x
movq %rsi, (%rdi):这个指令将y写入到寄存器%rdi 中的xp指向的内存位置,直接实现了代码中*xp=y
关于这段汇编代码有两个地方需要注意:C语言中所谓指针其实就是地址。间接引用指针就是将该指针放在一个寄存器中,然后在内存引用中使用这个寄存器。 其次像x这样的局部变量通常是保存在寄存器中,而不是内存中,访问寄存器比访问内存要快的多
压入和弹出栈数据
最后两个数据传送操作可以将数据压入程序栈中,以及从程序栈中弹出数据。
栈是一种数据结构,可以添加和删除值,不过要遵循后进先出的原则,通过push操作将数据压入栈中,通过pop删除数据。
它具有一个属性:弹出的值永远是最近被压入而且仍然在栈中的值。
pushq指令的功能是把数据压入栈上,而popq是弹出数据,这些指令都只有一个操作数--压入的数据源和弹出的数据目的
将一个四字值压入栈中,首先要将栈指针减8,然后将值写入到新的栈顶地址
因为栈和程序代码以及其他形式的程序数据都是存放在同一个内存中,所以程序可以用标准的内存寻址方法访问栈内的任意位置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号