《深入理解计算机系统》阅读笔记--计算机系统漫游
《深入理解计算机系统》,这本书,我多次想要好好完整的读一遍,每次都是没有坚持下去,但是作为一个开发者,自己想要成为为数不多的大牛之一,所以打算这次把这本书完整的好好读一遍,并整理为相关的博客!
书的开头说了一句话:计算机系统是由硬件和系统软件组成,他们共同工作来运行应用程序。
我们通常接触更多的是应用程序级别的,很少关注系统以及系统和硬件的交互,但是如果自己能完全理解计算机系统以及它对应用程序的影响,那将会让我们在软件开发的路上走的更远,也同时可以避免很多问题的发生。
拿最简单的hello.c 程序来说,我们看到的代码文件内容是:
#include <stdio.h> int main() { printf("hello,world\n"); return 0; }
但是对计算机来说其实就是由0和1组成的位(比特)序列,8个位组成一组,成为字节。
C程序的编译过程
通常我们写完C程序的代码,都会对程序进行编译,将代码文件编译成可执行程序,也就是我们在windows上通常看到的.exe文件,在Linux系统上我们通常通过gcc 来将c代码进行编译,其实当我们通过gcc 编译的时候,执行了四个阶段:预处理阶段,编译阶段,汇编阶段,链接阶段
执行这四个阶段的程序为:预处理器,编译器,汇编器,链接器,一起构成了编译系统
如下图是编译的过程表示:

预处理阶段:其实这个类似python中的import导入,将你要导入的代码文件放到这个文件中,而在C语言中,这里还是以hello.c 为例子,第一行的#include <stdio.h> 会告诉预处理器(cpp)读取系统的头文件中stdio.h的内容,并把它插入到程序文本中,结果是得到了另外一个C程序,生成的文件是以.i结尾
编译阶段:编译器(ccl) 将hello.c 翻译成hello.s ,成为一个汇编语言程序
汇编阶段:汇编器(as)将hello.s 翻译成机器指令,把这些指令打包成一个可重定位目标程序的格式,并将结果保存在hello.o中,hello.o文件其实已经是一个二进制文件。
链接阶段: 我们通常在代码中都会调用到标准库中的一些函数,就像我们hello.c代码中我们调用了printf函数,其实printf函数存在于一个名为printf.o 的单独预编译好的目标文件中,连接器ld 其实就是讲这个文件合并到我们的hello.o程序中。最终得到我们编译好的hello文件中或hello.exe 文件中,这就成了我们通常看到的可执行文件
了解这个编译过程对我们写代码来说的好处:
- 优化程序性能
- 理解链接时出现的错误
- 避免安全漏洞
系统硬件的组成
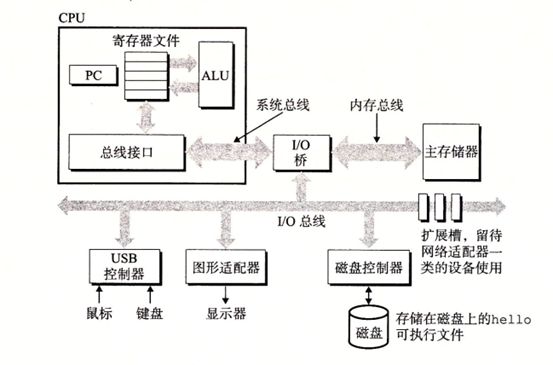
总线
我们从上图可以看出,整个系统是通过各种总线在连接,包括了:I/O总线,内存总线,系统总线
通常总线被设计成传送定长的字节块,也就是字(word),现在大多数及其的字长要么是4个字节(32位),要么是8个字节(64位),当然64为居多。
I/O设备
这个我们就比较熟悉了,主要就是用于系统和外部进行交互的,入鼠标键盘,显示器等
每个I/O设备通过一个控制器或适配器与I/O 总线相连。
控制器和适配器的区别:就是封装方式,控制器是主板上的芯片组,而适配器是一个插在主板插槽上的卡,如独立显卡和声卡等
主存
主存是一组动态随机存储器DRAM 芯片组成
主存是一个临时存储设备,用来存放程序和程序处理的数据
处理器
CPU 是解释或执行存储在主存中指令的引擎
处理器的核心是一个大小为一个字的存储设备或者寄存器,称为程序计数器(PC)
寄存器文件是一个小的存储设备,由一些单个字长的寄存器组成,每个寄存器都有唯一的名字,算数/逻辑单元(ALU)计算新的数据和地址。CPU 可能执行的操作:
加载: 从主存复制一个字节或者一个字到寄存器,以覆盖寄存器原来的值
存储: 从寄存器赋值一个字节或者一个字到主存的某个位置,以覆盖这个位置原来的内容
操作: 把两个寄存器的内容复制到ALU,ALU对这两个字做算数运算,并将结果放到一个寄存器中,覆盖该寄存器中原来的值
跳转:从指令本身中抽取一个字,并将这个字复制到程序计数器PC中,以覆盖PC中原来的值
上面大致理解了系统的各个组成部分,这次在回头看hello程序运行时在各个组件中传递过程
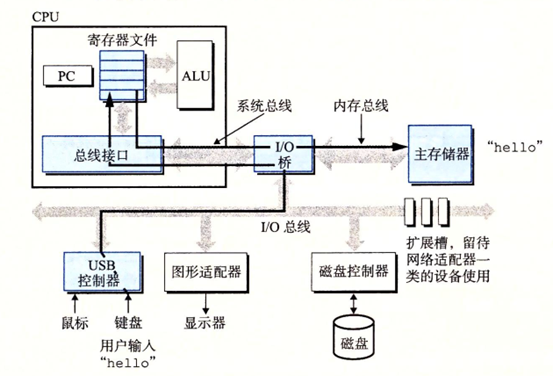
当我们开始通过键盘输入hello命令,程序就字符被逐一读到寄存器,然后放到内存中
回车之后系统将磁盘上我们的程序文件加载到主存中,然后处理器就会开始执行程序中的机器指令,并最终在显示器显示hello world
高速缓存的重要性
其实通过上面也看到了系统花费了大量的事件在各个组件之间拷贝来拷贝去,其实这些拷贝也是一种开销
并且在不同设备上运行的速度也是相差非常大,一般来说较大的存储设备要比较小的存储设备运行的慢,但是快速设备的造价会高很多比低速设备,这里就诞生了告诉缓存存储器cache memory
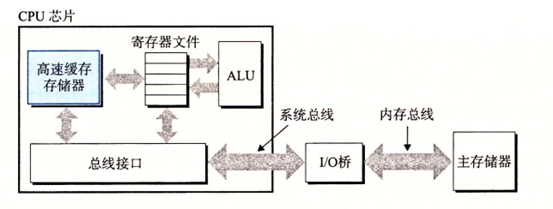
现在的处理器一般有三级高速缓存:L1,L2,L3, 当然可能更多
而这种高速缓存用的是一种叫做静态随机访问存储器(SRAM)的硬件技术实现的
这样就有了下面这个存储设备的层次结构:

存储器层次结构的主要思想是上一层的存储器作为低一层存储器的缓存
操作系统
当我们这会在回头来看操作系统,其实操作系统就是应用程序和硬件之间的中间层,应用程序通过操作系统来对硬件进行操作

操作系统的作用:防止硬件被失控的程序滥用;向应用程序提供一种机制用于操作硬件
而实现这两个功能是通过几个基本的抽象概念来实现:进程,虚拟内存和文件
文件是对I/O设备的抽象,虚拟内存是对主存和磁盘I/O 设备的抽象,进程则是对处理器、主存和IO设备的抽象
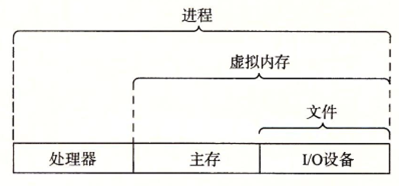
这里有几个关键词的概念需要理解:
进程:进程是操作系统对一个正在运行的程序的一种抽象。
并发运行:一个进程的指令和另外一个进程指令是交错执行
操作系统实现叫做执行的机制成为上下文切换
操作系统保持跟踪进程运行所需要的所有状态信息,就是上下文
其实我们在shell命令下执行我们的hello程序就是个并发的场景,这里有两个进程:shell进程和hello进程,而执行的过程可以通过如下图表示:
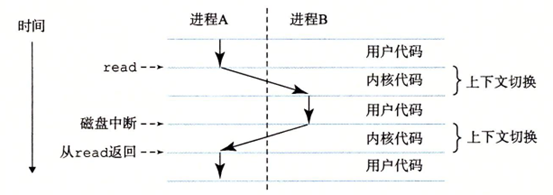
这里也要知道从一个进程到另外一个进程是有操作系统内核管理的,内核代码是操作系统代码常驻主存的部分
注意:内核不是一个独立的进程。它是系统管理全部进程所用代码和数据结构的集合
线程:一个进程通常可以由多个线程的执行单元组成,每个线程都运行在进程的上下文中,并共享同样的代码和全局数据
虚拟内存:虚拟内存是一个抽象概念,为每个进程提供了一个假象,好像每个进程都在独占的使用主存,每个进程看到的内存都是一致的,称为虚拟地址空间。下图是Linux的虚拟地址空间,地址是从下往上增大
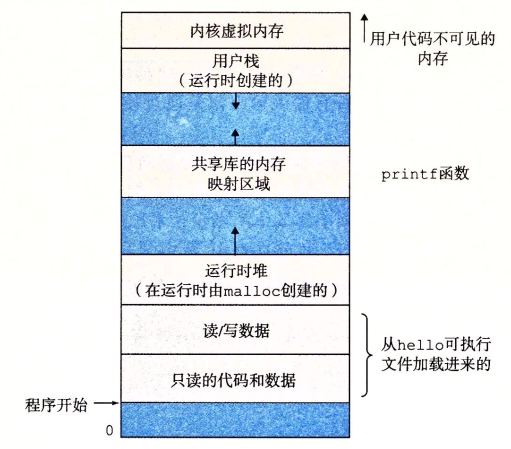
这里先简单的对着几个概念进行理解:
堆:代码和数据区在进程一开始运行就被指定了大小。同时堆可以在运行时动态的扩展和收缩
共享库: 在地址空间的中间部分是一块用来存放C标准库数学库这样的共享库代码和数据区域
栈:位于用户虚拟地址空间顶部的是用户栈,编译器用它实现函数的调用,同样栈在程序执行期间也可以动态的扩展和收缩
如:当我们执行函数时,栈就会增长,一个函数返回时,栈就会收缩
内核虚拟内存:地址空间的顶部区域是为内核保留的,不允许程序血祸者调用内核定义的函数,必须由内核来执行这些操作
Amdahl 定律
该定律的主要思想:当我们对系统的某个部分加速时,其对系统整体性能的影响取决于该部分的重要性和加速度
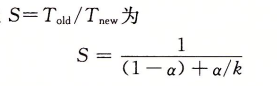
书中有个例子非常贴切,系统的某个部分的耗时比例是60%,也就是a = 0.6 其加速比例因子为3 k=3,我们可以获得的加速比为:
1/[0.4+0.6/3] = 1.67倍,即使对着一个部分做了重大概念,但获得系统加速比却明显小于这部分的加速比,所以想要显著加速整个系统,必须提升全系统中相当大的部分的速度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号