Python爬虫番外篇之关于登录
常见的登录方式有以下两种:
- 查看登录页面,csrf,cookie;授权;cookie
- 直接发送post请求,获取cookie
上面只是简单的描述,下面是详细的针对两种登录方式的时候爬虫的处理方法
第一种情况
这种例子其实也比较多,现在很多网站的登录都是第一种的方法,这里通过以github为例子:
分析页面
获取authenticity_token信息
我们都知道登录页面这里都是一个form表单提交,我可以可以通过谷歌浏览器对其进行分析
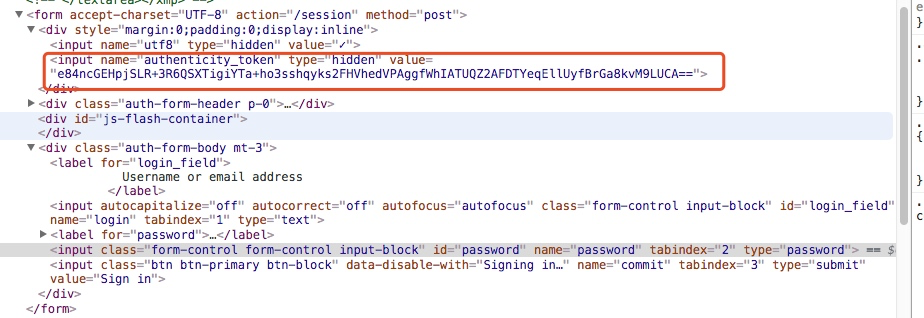
如上图我们找到了这个token信息
所以我们在登录之前应该先通过代码访问这个登录页面获取这个authenticity_token信息
获取登陆页面的cookie信息
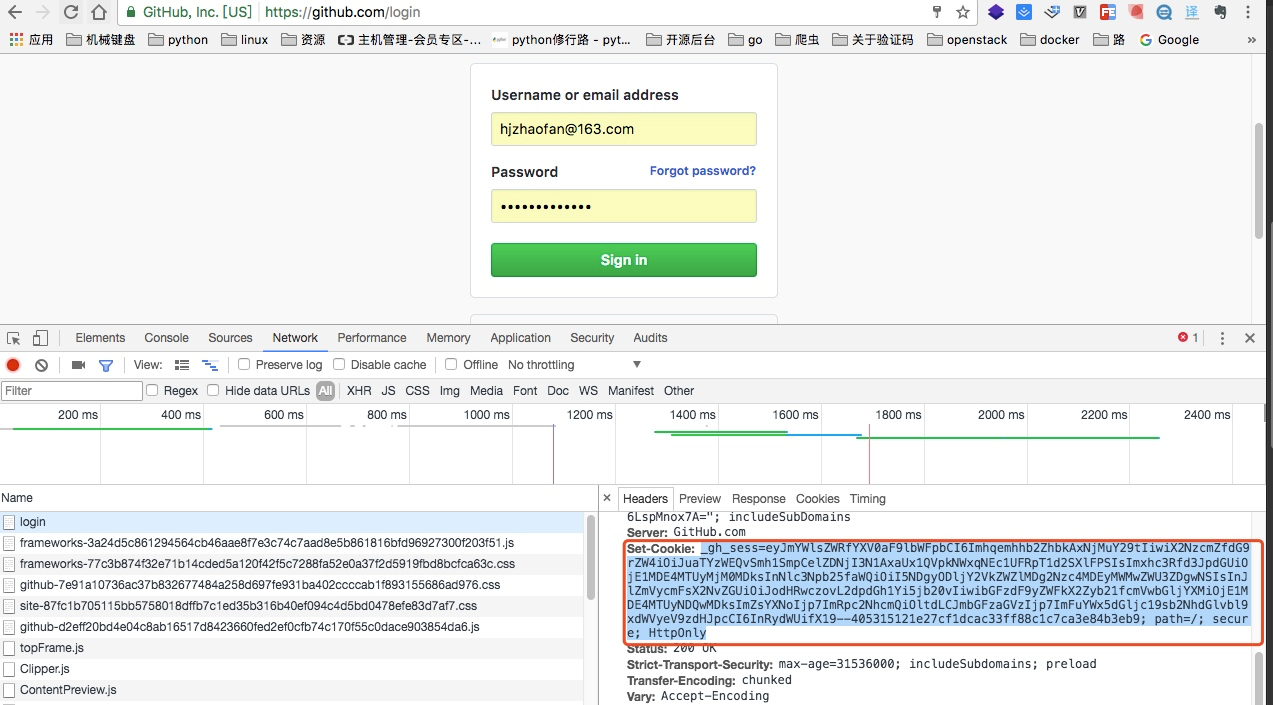
set-cookie这里是登录页面的cookie
分析登录包获取提交地址
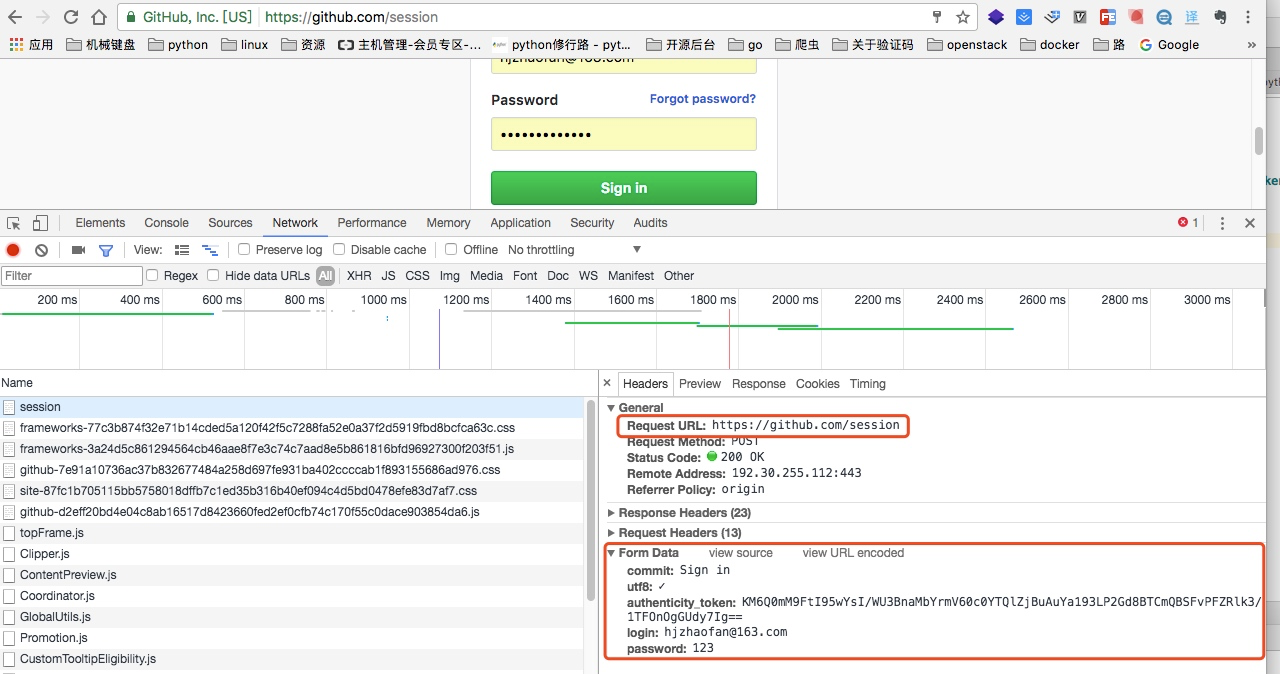
当我们输入用户名和密码之后点击提交,我们可以从包里找到如上图的地址,就是post请求提交form的信息
请求的地址:https://github.com/session
请求的参数有:
"commit": "Sign in",
"utf8":"✓",
"authenticity_token":“KM6Q0mM9FtI95wYsI/WU3BnaMbYrmV60c0YTQlZjBuAuYa193LP2Gd8BTCmQBSFvPFZRlk3/1TFOnOgGUdy7Ig==”,
"login":"hjzhaofan@163.com",
"password":"123"
从这里我们也可以看出提交参数中的“authenticity_token”,而这个参数就是需要我们从登陆页面先获取到。
当我们登录成功后:

再次访问github,这个时候cookie里就增加了两个cookie信息,而这个信息是登录后在增加的信息
所以如果我们想要通过程序登录,我们就需要在登录成功后再次获取cookie信息
然后通过这个cookie去访问我们github的其他信息例如我们的个人信息设置页面:
https://github.com/settings/profile
代码实现
下面代码实现了登录并访问https://github.com/settings/repositories
import requests from bs4 import BeautifulSoup Base_URL = "https://github.com/login" Login_URL = "https://github.com/session" def get_github_html(url): ''' 这里用于获取登录页的html,以及cookie :param url: https://github.com/login :return: 登录页面的HTML,以及第一次的cooke ''' response = requests.get(url) first_cookie = response.cookies.get_dict() return response.text,first_cookie def get_token(html): ''' 处理登录后页面的html :param html: :return: 获取csrftoken ''' soup = BeautifulSoup(html,'lxml') res = soup.find("input",attrs={"name":"authenticity_token"}) token = res["value"] return token def gihub_login(url,token,cookie): ''' 这个是用于登录 :param url: https://github.com/session :param token: csrftoken :param cookie: 第一次登录时候的cookie :return: 返回第一次和第二次合并后的cooke ''' data= { "commit": "Sign in", "utf8":"✓", "authenticity_token":token, "login":"你的github账号", "password":"*****" } response = requests.post(url,data=data,cookies=cookie) print(response.status_code) cookie = response.cookies.get_dict() #这里注释的解释一下,是因为之前github是通过将两次的cookie进行合并的 #现在不用了可以直接获取就行 # cookie.update(second_cookie) return cookie if __name__ == '__main__': html,cookie = get_github_html(Base_URL) token = get_token(html) cookie = gihub_login(Login_URL,token,cookie) response = requests.get("https://github.com/settings/repositories",cookies=cookie) print(response.text)
第二种情况
这里通过伯乐在线为例子,这个相对于第一种就比较简单了,没有太多的分析过程直接发送post请求,然后获取cookie,通过cookie去访问其他页面,下面直接是代码实现例子:
http://www.jobbole.com/bookmark/ 这个地址是只有登录之后才能访问的页面,否则会直接返回登录页面
这里说一下:http://www.jobbole.com/wp-admin/admin-ajax.php是登录的请求地址这个可以在抓包里可以看到
import requests def login(): url = "http://www.jobbole.com/wp-admin/admin-ajax.php" data = { "action": "user_login", "user_login":"zhaofan1015", "user_pass": '******', } response = requests.post(url,data) cookie = response.cookies.get_dict() print(cookie) url2 ="http://www.jobbole.com/bookmark/" response2 = requests.get(url2,cookies=cookie) print(response2.text) login()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号