paramiko模块,线程,进程
关于paramiko模块
paramiko是基于Python实现的ssh2远程安全连接,支持认证及密钥方式远程执行命令、文件传输,中间ssh代理等
paramiko的安装:
安装好之后,用paramiko模块写一个简单的远程ssh运行命令,代码如下:
1 import paramiko 2 ssh = paramiko.SSHClient() 3 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) 4 ssh.connect("192.168.1.23",22,username="root",password="123456") 5 stdin,stdout,stderr = ssh.exec_command("df -h") 6 result = stdout.read() 7 print(result.decode())
运行结果如下:
1 D:\python35\python.exe D:/python培训/s14/day9/ssh例子.py 2 Filesystem Size Used Avail Use% Mounted on 3 /dev/sda3 77G 1.6G 72G 3% / 4 tmpfs 495M 0 495M 0% /dev/shm 5 /dev/sda1 190M 36M 145M 20% /boot 6 7 8 Process finished with exit code 0
paramiko的核心组件:
SSHClient类,SFTPClient类
a. SSHClient类是一个SSH服务会话的高级表示,该类封装了传输(transport),通道(channel)及SFTPClient的校验,建立的方法,通常用于执行远程命令
connect方法
connect(self, hostkey=None, username='', password=None, pkey=None,gss_host=None, gss_auth=False, gss_kex=False, gss_deleg_creds=True)
参数说明:
hostname(str类型):连接的目标主机地址
port(int类型):连接目标主机的端口,默认为22
username(str类型):用户名
password(str类型):密码
pkey(PKey类型):私钥方式,用于身份验证
gass_host(str类型): The target's name in the kerberos database. Default: hostname
gss_auth(布尔类型):是否使用GSS-API认证
ss_kex=False(布尔类型):是否将GSS-API key和用户认证交换
gss_deleg_creds(布尔类型):是否代表包含GSS-API 客户端的凭据
exec_command方法:
远程执行命令方法,该命令的输入与输入流为标准输入(stdin)、输出(stdout)、错误(stderr)
load_system_host_keys方法
load_host_keys(self, filename)
加载本地总要校验文件,默认为~/.ssh/known_hosts,非默认另需要手工指定。
参数:
filename(str类型)指定远程主机公钥记录文件
set_missing_host_key_policy方法:
set_missing_host_key_policy(self, policy)
设置连接的远程主机没有本地主机秘钥或HostKeys对象时的策略,目前支持三种,分别是:AutoAddPolicy、RejectPolicy(默认)、WarningPolicy,三者的含义如下:
AutoAddPolicy:自动添加主机名及主机秘钥到本地HostKeys对象,并将其保存,不依赖load_system_host_keys()的配置,即使~/.ssh/known_hosts不存在也不产生影响
RejectPolicy:自动拒绝位置的主机名和秘钥,依赖load_system_host_keys()的配置
WarningPolicy:用于记录一个位置的主机秘钥的python警告,并接受它,功能上与AutoAddPolicy相似,但未知主机会有警告
b. SFTPClient类
SFTPClient根据SSH传输协议的sftp命令会话,实现远程文件操作:文件的上传、下载、权限、状态等操作。
from_transport方法:
from_transport(cls, t, window_size=None, max_packet_size=None)
参数说明:
t:一个已经通过验证的传输对象
例子:
1 transport = paramiko.Transport(('192.168.1.23',22)) 2 transport.connect(username="root",password="123456") 3 sftp = paramiko.SFTPClient.from_transport(transport)
put方法:
长传本地文件到远程SFTP服务端
put(self, localpath, remotepath, callback=None, confirm=True)
参数说明:
localpath(str类型):需要上传的本地文件(源文件)
remotepath(str类型):远程路径(目标文件)
callback(function(init,init)):获取已接收的字节数及总传输字节数,以便回调函数调用,默认为None
confirm(bool类型):文件长传完毕后是否调用start()方法,以便确认文件的大小
get方法
get(self, remotepath, localpath, callback=None)
从远程SFTP服务端下载本地
参数说明:
remotepath(str类型):需要下载的远程文件
localpath(str类型):本地路径
callback(function(init,init)): 获取已接收的字节数及总传输字节数,以便回调函数调用,默认为None
其他方法:
SFTPClient类其他常用方法:
Mkdir:在SFTP服务端创建目录
remove:删除SFTP服务端指定目录
rename:重命名SFTP服务端文件或目录
stat:获取远程SFTP服务端指定文件的信息
listdir:获取远程SFTP服务端指定目录列表,以Python的列表形式返回
下面是实际的代码例子:
基于账户名和密码的上传和下载文件
#AUTHOR:FAN
import paramiko
#t就相当于创建通道
t = paramiko.Transport(("192.168.1.23",22))
t.connect(username="root",password="123456")
#这里表示sftp通过t这个通道传输数据
sftp = paramiko.SFTPClient.from_transport(t)
#sftp.put("ssh例子.py","/tmp/aaa.py")
sftp.get("/tmp/aaa.py","sss")
sftp.close()
同样的也可以通过基于公钥的上传和下载文件
进程与线程
1、 线程:是操作系统能够进行运算的调度的最小单位,它被包含在进程中,是进程中实际的运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程可以并发多个线程,每条线程并行执行不同的任务。
线程是一串指令的集合
2、 进程:程序要以一个整体的形式暴露给操作系统管理,里面包含对各种资源的调用,内存的管理,网络接口的调用等….即对各种资源的集合。
进程要操作cpu,必须要先创建一个线程
所有在同一个进程里的线程是共享同一块内存空间的
线程共享内存空间,进程的内存是独立的
同一个进程的线程之间可以直接交流,两个进程想要通信,必须通过一个中间代理来实现
创建新线程很简单,创建新进程需要对其父进程进行一次克隆
一个线程可以控制和操作同一个进程里的其他线程,但是进程只能操作子进程
一个最简单的多线程的代码例子:
1 import threading,time 2 def run(n): 3 print("task",n) 4 time.sleep(2) 5 6 t1 = threading.Thread(target=run,args=("t1",)) 7 t2 = threading.Thread(target=run,args=("t2",)) 8 t1.start() 9 t2.start()
下面是一个对多线程的一个处理方法:(需要理解):
1 import threading 2 import time 3 def run(n): 4 print("task:",n) 5 time.sleep(2) 6 print("task done:",n) 7 8 start_time = time.time() 9 for i in range(10): 10 t = threading.Thread(target=run,args=(i,)) 11 t.start() 12 print("cost:",time.time()-start_time)
运行结果如下:
1 D:\python35\python.exe D:/python培训/s14/day9/threading_ex2.py 2 task: 0 3 task: 1 4 task: 2 5 task: 3 6 task: 4 7 task: 5 8 task: 6 9 task: 7 10 task: 8 11 task: 9 12 cost: 0.0010001659393310547 13 task done: 1 14 task done: 2 15 task done: 4 16 task done: 0 17 task done: 5 18 task done: 9 19 task done: 8 20 task done: 6 21 task done: 3 22 task done: 7 23 24 Process finished with exit code 0 25 下图是对上述程序的理解,这个非常重要,之前自己一直迷糊在这个地方
下图是对上述程序的理解,这个非常重要,之前自己一直迷糊在这个地方
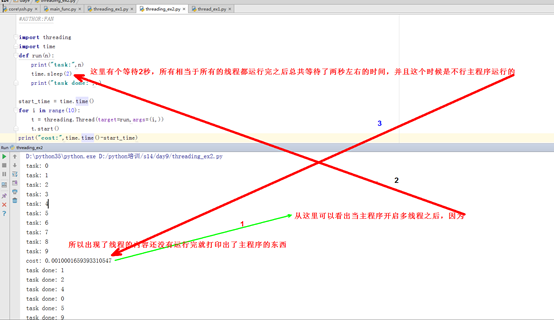
但是现在有个问题,我们需要计算所有线程的执行时间,并且让所有线程运行之后再运行主程序
这里就需要用到线程里的一个方法join()意思其实就是等待的意思代码如下:
1 import threading 2 import time 3 def run(n): 4 print("task:",n) 5 time.sleep(2) 6 print("task done:",n) 7 8 start_time = time.time() 9 t_obj = [] 10 for i in range(10): 11 t = threading.Thread(target=run,args=(i,)) 12 t.start() 13 t_obj.append(t) 14 for i in t_obj: 15 i.join() 16 17 print("all thread is done") 18 print("cost:",time.time()-start_time)
threading.current_thread() 表示当前线程
threading.active_count() 表示当前活跃线程数
关于守护线程
如果将线程设置为守护线程,则主程序不会管线程是否执行完,只有主程序执行完毕之后,就会结束
代码例子如下:
1 #AUTHOR:FAN 2 3 import threading 4 import time 5 def run(n): 6 print("task:",n) 7 time.sleep(2) 8 print("task done:",n) 9 10 start_time = time.time() 11 for i in range(10): 12 t = threading.Thread(target=run,args=(i,)) 13 t.setDaemon(True) 14 t.start() 15 16 print("all thread is done",threading.current_thread(),threading.active_count()) 17 print("cost:",time.time()-start_time)
运行结果如下:
1 D:\python35\python.exe D:/python培训/s14/day9/threading_ex2.py 2 task: 0 3 task: 1 4 task: 2 5 task: 3 6 task: 4 7 task: 5 8 task: 6 9 task: 7 10 task: 8 11 task: 9 12 all thread is done <_MainThread(MainThread, started 5908)> 11 13 cost: 0.007000446319580078 14 15 Process finished with exit code 0
GIL 全局解释器锁
无论你启多少个线程,你有多少个cpu, Python在执行的时候会淡定的在同一时刻只允许一个线程运行
线程锁(互斥锁)
一个进程下可以启动多个线程,多个线程共享父进程的内存空间,这样每个线程可以访问同一份数据,此时如果多个线程同时修改一份数据,就会出现问题。
但是经过测试在3.0上不存在这个问题
递归锁
也就是锁中包含锁,代码例子:
1 import threading,time 2 3 def run1(): 4 print("grab the first part data") 5 lock.acquire() 6 global num 7 num +=1 8 lock.release() 9 return num 10 def run2(): 11 print("grab the second part data") 12 lock.acquire() 13 global num2 14 num2+=1 15 lock.release() 16 return num2 17 def run3(): 18 lock.acquire() 19 res = run1() 20 print('--------between run1 and run2-----') 21 res2 = run2() 22 lock.release() 23 print(res,res2) 24 25 26 if __name__ == '__main__': 27 28 num,num2 = 0,0 29 lock = threading.RLock() 30 for i in range(10): 31 t = threading.Thread(target=run3) 32 t.start() 33 34 while threading.active_count() != 1: 35 print(threading.active_count()) 36 else: 37 print('----all threads done---') 38 print(num,num2)
信号量semaphore
互斥锁同时只允许一个线程更改数据,而信号量可以同时允许一定数量的线程更改数据
待续,还没有整理完

 浙公网安备 33010602011771号
浙公网安备 33010602011771号