python中常用的模块的总结
1、 模块和包
a.定义:
模块用来从逻辑上组织python代码(变量,函数,类,逻辑:实现一个功能),本质就是.py结尾的python文件。(例如:文件名:test.py,对应的模块名:test)
包:用来从逻辑上组织模块的,本质就是一个目录(必须带有一个__init__.py的文件)
b.导入方法
import module_name
import module_1的本质:是将module_1解释了一遍
也就是将module_1中的所有代码复制给了module_1
from module_name1 import name
本质是将module_name1中的name变量放到当前程序中运行一遍
所以调用的时候直接print(name)就可以打印出name变量的值
代码例子:自己写的模块,其他程序调用,如下所示:
模块module_1.py代码:
1 name = "dean" 2 def say_hello(): 3 print("hello %s" %name)
调用模块的python程序main代码如下:(切记调用模块的时候只需要import模块名不需要加.py)
import module_1
#调用变量
print(module_1.name)
#调用模块中的方法
module_1.say_hello()
这样运行main程序后的结果如下:
1 D:\python35\python.exe D:/python培训/s14/day5/module_test/main.py 2 dean 3 hello dean 4 5 Process finished with exit code 0
import module_name1,module_name2
from module_name import *(这种方法不建议使用)
from module_name import logger as log(别名的方法)
c.导入模块的本质就是把python文件解释一遍
import module_name---->module_name.py---->module_name.py的路径---->sys.path
导入包的本质就是执行该包下面的__init__.py
关于导入包的一个代码例子:
新建一个package_test包,并在该包下面建立一个test1.py的python程序,在package包的同级目录建立一个p_test.py的程序

test1的代码如下:
1 def test(): 2 print("int the test1")
package_test包下的__init__.py的代码如下:
1 #import test1 (理论上这样就可以但是在pycharm下测试必须用下面from .import test1) 2 from . import test1 3 print("in the init")
p_test的代码如下:
1 import package_test #执行__init__.py 2 package_test.test1.test()
这样运行p_test的结果:
1 D:\python35\python.exe D:/python培训/s14/day5/p_test.py 2 in the init 3 int the test1 4 5 Process finished with exit code 0
从上述的例子中也可以看出:导入包的时候其实是执行包下的__init__.py程序,所以如果想要调用包下面的python程序需要在包下的__init__.py导入包下面的程序
2、模块的分类
a. 标准库
b. 开源模块
c. 自动以模块
3、时间模块
time与datetime
python中常见的时间表示方法:
a. 时间戳
时间戳:从1970年1月1日00:00:00到现在为止一共的时间数(单位为秒)
>>> time.time()
1472016249.393169
>>>
b. 格式化的时间字符串
c. struct_time(元组)
相互之间的转换关系如下:
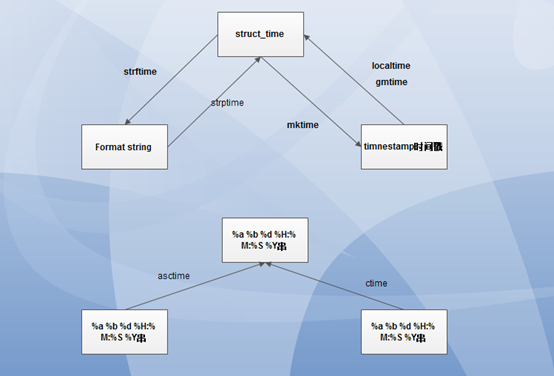
1) time.localtime()将时间戳转换为当前时间的元组
>>> time.localtime()
time.struct_time(tm_year=2016, tm_mon=8, tm_mday=24, tm_hour=13, tm_min=27, tm_sec=55, tm_wday=2, tm_yday=237, tm_isdst=0)
>>>
2) time.gmtime()将时间戳转换为当前时间utc时间的元组
>>> time.gmtime()
time.struct_time(tm_year=2016, tm_mon=8, tm_mday=24, tm_hour=5, tm_min=35, tm_sec=43, tm_wday=2, tm_yday=237, tm_isdst=0)
>>>
3) time.mktime()可以将struct_time转换成时间戳
>>> x = time.localtime()
>>> x
time.struct_time(tm_year=2016, tm_mon=8, tm_mday=24, tm_hour=13, tm_min=39, tm_sec=42, tm_wday=2, tm_yday=237, tm_isdst=0)
>>> time.mktime(x)
1472017182.0
>>>
4) 将struct_time装换成格式化的时间字符串
>>> x
time.struct_time(tm_year=2016, tm_mon=8, tm_mday=24, tm_hour=13, tm_min=39, tm_sec=42, tm_wday=2, tm_yday=237, tm_isdst=0)
>>> time.strftime("%Y-%m-%d %H:%M:%S",x)
'2016-08-24 13:39:42'
>>>
5) 可以将格式化的时间字符串转换为struct_time
>>> time.strptime("2016-08-24 14:05:32","%Y-%m-%d %H:%M:%S")
time.struct_time(tm_year=2016, tm_mon=8, tm_mday=24, tm_hour=14, tm_min=5, tm_sec=32, tm_wday=2, tm_yday=237, tm_isdst=-1)
>>>
6)将struct_time转换成Wed Aug 24 14:22:47 2016这种格式
>>> x
time.struct_time(tm_year=2016, tm_mon=8, tm_mday=24, tm_hour=14, tm_min=22, tm_sec=47, tm_wday=2, tm_yday=237, tm_isdst=0)
>>> time.asctime(x)
'Wed Aug 24 14:22:47 2016'
>>>
7)将时间戳装换成Wed Aug 24 14:22:47 2016格式
>>> x = time.time()
>>> x
1472019984.958831
>>> time.ctime(x)
'Wed Aug 24 14:26:24 2016'
>>>
1 %a 本地(locale)简化星期名称 2 %A 本地完整星期名称 3 %b 本地简化月份名称 4 %B 本地完整月份名称 5 %c 本地相应的日期和时间表示 6 %d 一个月中的第几天(01 - 31) 7 %H 一天中的第几个小时(24小时制,00 - 23) 8 %I 第几个小时(12小时制,01 - 12) 9 %j 一年中的第几天(001 - 366) 10 %m 月份(01 - 12) 11 %M 分钟数(00 - 59) 12 %p 本地am或者pm的相应符 13 %S 秒(01 - 61) 14 %U 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 15 %w 一个星期中的第几天(0 - 6,0是星期天) 16 %W 和%U基本相同,不同的是%W以星期一为一个星期的开始。 17 %x 本地相应日期 18 %X 本地相应时间 19 %y 去掉世纪的年份(00 - 99) 20 %Y 完整的年份 21 %Z 时区的名字(如果不存在为空字符) 22 %% ‘%’字符
datetime
当前时间:datetime.datetime.now()
1、 随机模块random
random.randint(1,3)则可以取出随机1-3
random.randrange(1,3)随机从范围内所及
random.choice()传递的参数是序列包括字符串列表等
>>> random.choice("hello")
'l'
>>> random.choice("hello")
'o'
>>> random.choice("hello")
'e'
>>>
>>> random.choice(["我","爱","你"])
'我'
>>> random.choice(["我","爱","你"])
'你'
>>> random.choice(["我","爱","你"])
'你'
>>> random.choice(["我","爱","你"])
'爱'
>>>
random.sample()随机从前面的序列取出两位
>>> random.sample("hello",2)
['l', 'o']
>>> random.sample("hello",2)
['h', 'l']
>>> random.sample("hello",2)
['h', 'o']
>>>
random的洗牌功能:
>>> a=[1,2,3,4,5,6,7,8,9]
>>> random.shuffle(a)
>>> a
[6, 3, 7, 4, 1, 8, 9, 2, 5]
>>>
生成随机验证码的例子:
1 import string 2 import random 3 a = "".join(random.sample(string.ascii_lowercase,4)) 4 print(a) 5 b = "".join(random.sample(string.ascii_lowercase+string.digits,5)) 6 print(b) 7 8 c = "".join(random.sample(string.ascii_uppercase+string.digits+string.ascii_lowercase,4)) 9 print(c) 10 d ="".join(random.sample(string.ascii_letters+string.digits,4)) 11 print(d)
运行结果如下:
1 D:\python35\python.exe D:/python培训/s14/day5/验证码2.py 2 tbdy 3 6te4b 4 Z2UA 5 v8He 6 7 Process finished with exit code 0
5、os模块
1 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 2 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd 3 os.curdir 返回当前目录: ('.') 4 os.pardir 获取当前目录的父目录字符串名:('..') 5 os.makedirs('dirname1/dirname2') 可生成多层递归目录 6 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 7 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname 8 os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 9 os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 10 os.remove() 删除一个文件 11 os.rename("oldname","newname") 重命名文件/目录 12 os.stat('path/filename') 获取文件/目录信息 13 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" 14 os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" 15 os.pathsep 输出用于分割文件路径的字符串 16 os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' 17 os.system("bash command") 运行shell命令,直接显示 18 os.environ 获取系统环境变量 19 os.path.abspath(path) 返回path规范化的绝对路径 20 os.path.split(path) 将path分割成目录和文件名二元组返回 21 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 22 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 23 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False 24 os.path.isabs(path) 如果path是绝对路径,返回True 25 os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False 26 os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False 27 os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 28 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 29 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
6、 sys模块
1 sys.argv 命令行参数List,第一个元素是程序本身路径 2 sys.exit(n) 退出程序,正常退出时exit(0) 3 sys.version 获取Python解释程序的版本信息 4 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 5 sys.platform 返回操作系统平台名称 6 sys.stdout.write('please:')
7、shutil模块
1 import shutil 2 3 a = open("a.txt","r",encoding="utf-8") 4 b = open("b.txt","w",encoding="utf-8") 5 6 shutil.copyfileobj(a,b)
运行够会复制一个文件b,将a文件中的内容复制到b文件中
shutil.copyfile("b.txt","c.txt")直接复制b.txt到c.txt
shutil.copymode(src,dst) 仅拷贝权限。内容,组,用户均不变
shutil.copystat(src,dst)拷贝状态的信息
shutil.copytree(src,dst,symlinks=false,ignore=none) 递归拷贝文件
shutil.rmtree(path[,ignore_errors[,onerror]])
shutil.move(sr,dst)
递归移动文件
8、用于序列化的两个模块json&pickle
json,用于字符串 和 python数据类型间进行转换
pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
9、 关于shelve模块
代码例子:
1 #AUTHOR:FAN 2 import shelve 3 import datetime 4 5 d = shelve.open("shelve_test") 6 7 info = {"name":"dean","job":"it","age":23} 8 9 d["name"]=info["name"] 10 d["job"]=info["job"] 11 d["date"]=datetime.datetime.now() 12 d.close()
运行结果,会生成如下三个文件

取出上述存的数据的代码如下:
1 d = shelve.open("shelve_test") 2 print(d.get("name")) 3 print(d.get("job")) 4 print(d.get("date"))
运行结果如下:
1 D:\python35\python.exe D:/python培训/s14/day5/shelve模块/shelve_test.py 2 dean 3 it 4 2016-08-24 16:04:13.325482 5 6 Process finished with exit code 0
10、正则re模块
1 '.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 2 '^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE) 3 '$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以 4 '*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a'] 5 '+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb'] 6 '?' 匹配前一个字符1次或0次 7 '{m}' 匹配前一个字符m次 8 '{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb'] 9 '|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC' 10 '(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c 11 12 13 '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的 14 '\Z' 匹配字符结尾,同$ 15 '\d' 匹配数字0-9 16 '\D' 匹配非数字 17 '\w' 匹配[A-Za-z0-9] 18 '\W' 匹配非[A-Za-z0-9] 19 's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
r代表取消引号里面特殊字符的意义
最常用的匹配语法:
re.match从头开始匹配
re.search匹配包含
re.findall把所有匹配到的字符放到以列表中的元素返回
re.splitall以匹配到的字符当做列表分隔符
re.sub匹配字符并替换
下面是关于正则的例子帮助理解:
1 >>> re.match("^zhao","zhaofan123") 2 <_sre.SRE_Match object; span=(0, 4), match='zhao'> 3 >>> re.match("^ww","zhaofan123") 4 >>> 5 从这里也可以看出,如果有返回则表示匹配到了,否则则是没有匹配到 6 >>> res = re.match("^zhao","zhaofan123") 7 >>> res 8 <_sre.SRE_Match object; span=(0, 4), match='zhao'> 9 >>> res.group() #如果想要查看匹配的内容.group() 10 'zhao' 11 >>> 12 匹配zhao后面以及数字 13 >>> res = re.match("^zhao\d","zhao2323fan123") 14 >>> res.group() 15 'zhao2' 16 匹配多个数字 17 >>> res = re.match("^zhao\d+","zhao2323fan123") 18 >>> res.group() 19 'zhao2323' 20 >>> 21 22 查找特定字符 23 >>> re.search("f.+n","zhao2323fan123") 24 <_sre.SRE_Match object; span=(8, 11), match='fan'> 25 >>> 26 >>> re.search("f.+n","zhao2323fan123n") 27 <_sre.SRE_Match object; span=(8, 15), match='fan123n'> 28 >>> 29 30 >>> re.search("f[a-z]+n","zhao2323fan123n") 31 <_sre.SRE_Match object; span=(8, 11), match='fan'> 32 >>> 33 $是匹配到字符串的最后 34 >>> re.search("#.+#","1234#hello#") 35 <_sre.SRE_Match object; span=(4, 11), match='#hello#'> 36 >>> 37 >>> re.search("aa?","zhaaaofan") 38 <_sre.SRE_Match object; span=(2, 4), match='aa'> 39 >>> re.search("aaa?","zhaaaofan") 40 <_sre.SRE_Match object; span=(2, 5), match='aaa'> 41 >>> 42 >>> re.search("aaa?","zhaaofan") 43 <_sre.SRE_Match object; span=(2, 4), match='aa'> 44 >>> 45 46 <_sre.SRE_Match object; span=(2, 5), match='aaa'> 47 >>> re.search("aaa?","zhaaofaaan") 48 <_sre.SRE_Match object; span=(2, 4), match='aa'> 49 >>> re.search("aaa?","zhaofaaan") 50 <_sre.SRE_Match object; span=(5, 8), match='aaa'> 51 >>> re.search("aaa?","zhaaofaaan") 52 <_sre.SRE_Match object; span=(2, 4), match='aa'> 53 从上面可以很好的理解?是匹配前一个字符0次或者1次 54 通俗的说就是aa后面有1个或者没有a都可以匹配到 55 >>> re.search("[0-9]{3}","aaax234sdfaass22s") 56 <_sre.SRE_Match object; span=(4, 7), match='234'> 57 >>> 58 匹配数字3次 59 >>> re.search("[0-9]{3}","aaax234sdfaass22s") 60 <_sre.SRE_Match object; span=(4, 7), match='234'> 61 >>> 62 匹配数字1次到3次 63 >>> re.search("[0-9]{1,3}","aaa23sdfsdf2323ss") 64 <_sre.SRE_Match object; span=(3, 5), match='23'> 65 >>> 66 找到所有的数字 67 >>> re.findall("[0-9]{1,3}","sss23sdf2223ss11") 68 ['23', '222', '3', '11'] 69 >>> 70 71 >>> re.search("abc|ABC","ABCabCD").group() 72 'ABC' 73 >>> re.findall("abc|ABC","ABCabcCD") 74 ['ABC', 'abc'] 75 >>> 76 >>> re.search("abc{2}","zhaofanabccc") 77 <_sre.SRE_Match object; span=(7, 11), match='abcc'> 78 >>> 79 >>> re.search("(abc){2}","zhaofanabcabc") 80 <_sre.SRE_Match object; span=(7, 13), match='abcabc'> 81 高级用法: 82 >>> re.search("(?P<id>[0-9]+)","abc12345daf#s22") 83 <_sre.SRE_Match object; span=(3, 8), match='12345'> 84 >>> re.search("(?P<id>[0-9]+)","abc12345daf#s22").group() 85 '12345' 86 >>> re.search("(?P<id>[0-9]+)","abc12345daf#s22").groupdict() 87 {'id': '12345'} 88 >>> 89 90 91 split的用法: 92 >>> re.split("[0-9]+","acb23sdf2d22ss") 93 ['acb', 'sdf', 'd', 'ss'] 94 >>> 95 sub替换的用法 96 >>> re.sub("[0-9]+","#","234ssdfsdf23sdf22ss3s") 97 '#ssdfsdf#sdf#ss#s' 98 >>> 99 100 >>> re.sub("[0-9]+","#","234ssdfsdf23sdf22ss3s",count=2) 101 '#ssdfsdf#sdf22ss3s' 102 >>>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号