一致性哈希
1 需求与问题
在分布式存储系统中,随着数据量的增加,单机难以顶住压力,不得不上多台机器构成集群。所以在分布式的存储系统中,要将数据存储到具体的节点上(或者说哈希槽位),我们可以使用哈希算法,如果采用普通的hash算法进行映射,将数据映射到具体的节点上,如key%N,key是数据的key,N是机器节点数,此时倘若需要对系统进行扩展,在集群中加入机器,或者减少机器,在大多数情况下几乎要对所有的槽位数据进行重新映射,此带来的效率低下是不可预估的。
所以此时就需要一致性哈希来解决问题。
2 一致性哈希
2.1 原理
在分布式存储中普通Hash算法存在伸缩性差的问题,对于此1997年麻省理工学院的Karger等人的一篇文章《Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web》
提出了一种一致性哈希算法,这个概念还被应用于分布式散列表(DHT)的设计。DHT使用一致哈希来划分分布式系统的节点。所有关键字都可以通过一个连接所有节点的覆盖网络高效地定位到某个节点。
该算法具体的,通过构建环状的 Hash 空间替线性 Hash 空间的方法解决了普通哈希伸缩性差的问题,整个 Hash 空间被构建成一个首位相接的环。
每个对象映射到圆环边上的一个点,系统再将可用的节点机器映射到圆环的不同位置。查找某个对象对应的机器时,需要用一致哈希算法计算得到对象对应圆环边上位置,沿着圆环边上查找直到遇到某个节点机器,这台机器即为对象应该保存的位置。 当删除一台节点机器时,这台机器上保存的所有对象都要移动到下一台机器。添加一台机器到圆环边上某个点时,这个点的下一台机器需要将这个节点前对应的对象移动到新机器上。 更改对象在节点机器上的分布可以通过调整节点机器的位置来实现。
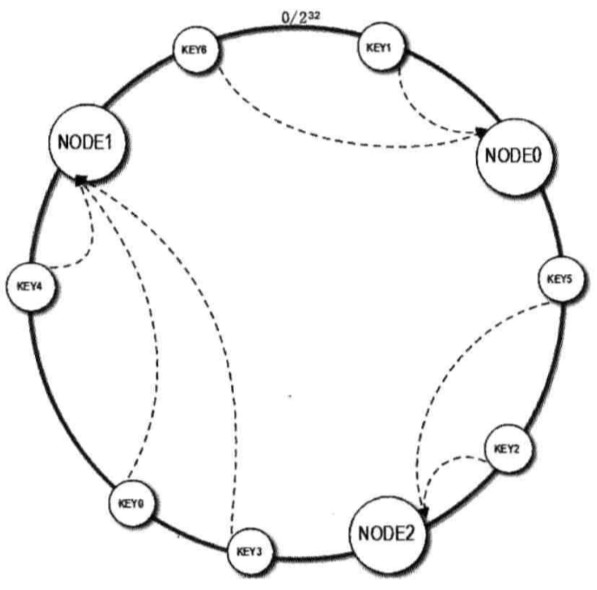
所以具体构造过程大概就是分为三步:
- 先构造一个长度为 大小的环状空间。
- 计算每个缓存服务器的 Hash 值,并记录,这就是它们在 Hash 环上的位置
- 对于每个需要存储的key,先根据 key 的 hashcode 得到它在 Hash 环上的位置,然后在 Hash 环上顺时针查找距离这个 Key 的 Hash 值最近的缓存服务器节点,这就是该图片所要存储的缓存服务器。
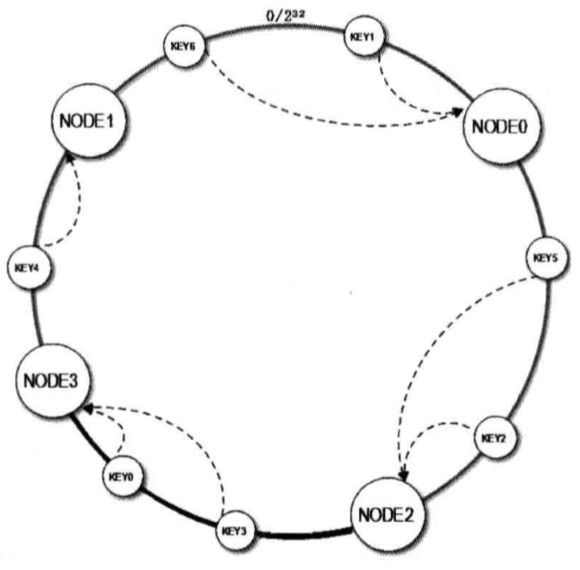
当缓存服务器需要扩容的时候,只需要将新加入缓存服务器的 Hash 值放入一致性 Hash 环中,由于 Key 是顺时针查找距离其最近的节点,因此新加入的几点只影响整个环中的一小段。加入新节点 NODE3 后,原来的 Key 大部分还能继续计算到原来的节点,只有 Key3、Key0 从原来的 NODE1 重新计算到 NODE3,这样就能保证大部分被缓存数据还可以命中。当节点被删除时,其他节点在环上的映射不会发生改变,只是原来打在对应节点的 key 现在会转移到顺时针方向的下一个节点上。
2.2 虚拟节点
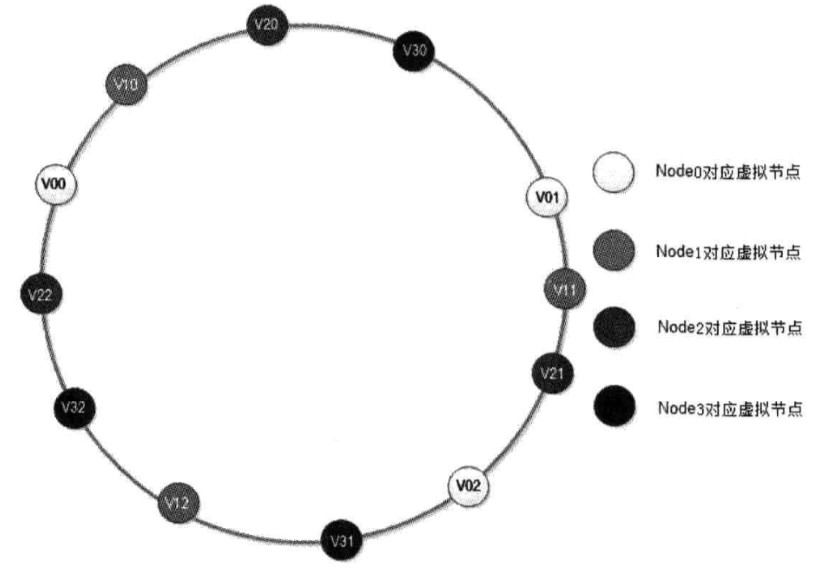
当新加入的节点 NODE3时,其只影响了原来的节点 NODE1,也就是说一部分原来需要访问 NODE1 的缓存数据现在需要访问 NODE3(概率上是 50%)但是原来的节点 NODE0 和 NODE2 不受影响,这就意味着 NODE0 和 NODE2 缓存数据量和负载压力是 NODE1 与 NODE3 的两倍。这种现象称之为数据倾斜,为了解决这个问题就引入了虚拟节点。
具体的就是扩展整个环上的节点数量,可以将每台物理缓存服务器虚拟为一组虚拟缓存服务器,使得 Hash 环在空间上的分割更加均匀。这样只是将虚拟节点的 Hash 值放置在 Hash 环上,在查找时,首先根据 Key 值找到环上的虚拟节点,然后再根据虚拟节点找到真实额缓存服务器。虚拟节点的数目足够多,就会使得节点在 Hash 环上的分布更加随机化,也就是增加或者删除一台缓存服务器时,都会较为均匀的影响原来集群中已经存在的缓存服务器。
2.3 应用
Redis
很多时候提到一致性哈希,都会以Redis为例,实际上Redis集群并没有使用一致性哈希算法,但是redis集群是3.0版本才出现的,出现的比较晚,在集群模式出现之前,很多公司都做了自己的redis集群了。这些自研的redis集群的实现方式有多种,比如在redis的jedis客户端jar包就是实现了一致性hash算法。
而Redis Cluster采用HashSlot来实现Key值的均匀分布和实例的增删管理,事实上和一致性哈希思想类似,只不过其并不形成一个闭合的环,更加具体的可以参考Redis的高可用实现——复制哨兵集群。
Memcached
与Redis相对的,Memcached作为缓存数据库,服务器端本身不提供分布式cache的一致性,一般在客户端使用一致性哈希算法来保证分布式存储的数据分布问题。
3 实现
提供一种简易实现,存储节点采用二叉查找树(Java中TreeMap是基于二叉查找树的一种——红黑树实现的),采用md5哈希方法。
public class ConsistencyHash {
private TreeMap<Long,Object> nodes = null;
//真实服务器节点信息
private List<Object> shards = new ArrayList();
//设置虚拟节点数目
private int VIRTUAL_NUM = 4;
/**
* 初始化一致环
*/
public void init() {
shards.add("192.168.0.0-服务器0");
shards.add("192.168.0.1-服务器1");
shards.add("192.168.0.2-服务器2");
shards.add("192.168.0.3-服务器3");
shards.add("192.168.0.4-服务器4");
nodes = new TreeMap<Long,Object>();
for(int i=0; i<shards.size(); i++) {
Object shardInfo = shards.get(i);
for(int j=0; j<VIRTUAL_NUM; j++) {
nodes.put(hash(computeMd5("SHARD-" + i + "-NODE-" + j),j), shardInfo);
}
}
}
/**
* 根据key的hash值取得服务器节点信息
* @param hash
* @return
*/
public Object getShardInfo(long hash) {
Long key = hash;
SortedMap<Long, Object> tailMap=nodes.tailMap(key);
if(tailMap.isEmpty()) {
key = nodes.firstKey();
} else {
key = tailMap.firstKey();
}
return nodes.get(key);
}
/**
* 打印圆环节点数据
*/
public void printMap() {
System.out.println(nodes);
}
/**
* 根据2^32把节点分布到圆环上面。
* @param digest
* @param nTime
* @return
*/
public long hash(byte[] digest, int nTime) {
long rv = ((long) (digest[3+nTime*4] & 0xFF) << 24)
| ((long) (digest[2+nTime*4] & 0xFF) << 16)
| ((long) (digest[1+nTime*4] & 0xFF) << 8)
| (digest[0+nTime*4] & 0xFF);
return rv & 0xffffffffL; /* Truncate to 32-bits */
}
/**
* Get the md5 of the given key.
* 计算MD5值
*/
public byte[] computeMd5(String k) {
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("MD5 not supported", e);
}
md5.reset();
byte[] keyBytes = null;
try {
keyBytes = k.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException("Unknown string :" + k, e);
}
md5.update(keyBytes);
return md5.digest();
}
public static void main(String[] args) {
Random ran = new Random();
ConsistencyHash hash = new ConsistencyHash();
hash.init();
hash.printMap();
//循环50次,是为了取50个数来测试效果,当然也可以用其他任何的数据来测试
for(int i=0; i<50; i++) {
System.out.println(hash.getShardInfo(hash.hash(hash.computeMd5(String.valueOf(i)),ran.nextInt(hash.VIRTUAL_NUM))));
}
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!