HashMap源码解析(以JDK8为例)
1 概述
本篇文章来谈一下经常用到的key-value形式的集合类HashMap,它最早出现于JDK1.2中,底层是基于散列表算法实现,HashMap允许key和value值为空。它是非线程安全的类,如果需要线程安全的HashMap,可以使用ConcurrentHashMap,关于这个在以后的文章中会讨论。
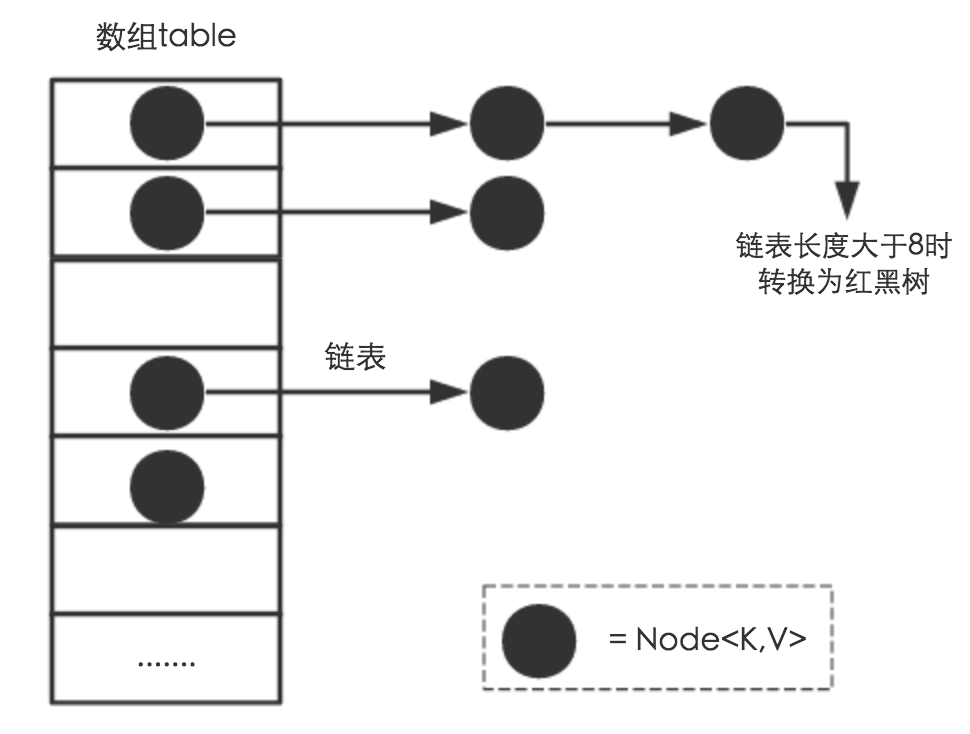
在JDK1.8以前,HashMap使用链定址法解决冲突,但JDK1.8开始,引入了红黑树,具体的是,一个桶中链表长度>8时,且table数组的容量>64时,将链表拆分成红黑树,以降低查找复杂度。
2 源码分析
2.1 基础变量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
最先给出的四个比较重要的基础变量分别是默认的桶的大小、最大数据负载量、负载因子以及桶中树化的阈值。
2.1.1 桶的大小(DEFAULT_INITIAL_CAPACITY )
默认桶的大小选用的是16,并且一直维持大小均为2的幂,桶的大小和负载因子可以通过构造函数指定大小,即使你给的设定的不是2的幂,那么也会自动通过调用tableSizeFor方法将大小变成大于你传入的数的最小2的幂,这个有两个原因,第一,因为当算出某个数据的hash值映射到table数组中时,使用(桶大小-1)&hash值,就能够直接得到映射结果。
这里我们可以假设默认table数组的大小是16,那么其二进制值就是10000,减去1即1111,那么这个数直接和计算出来的hash值做一个与的操作,即取到了计算出hash值的后四位,得到映射在table中的结果。第二个原因是能够在扩容时更好的重新映射冲突元素,这里后面扩容时会讲到。
但实际上使用2的幂来做table数组的大小是一种非常规的做法,常规做法是使用素数,因为采用素数作为哈希表的大小,能够最大程度的避免模数相同的数之间具备公共因子。
具体常规下哈希表大小选择可以参考这里
2.1.2 最大容量(MAXIMUM_CAPACITY)
默认最大数据负载是\(2^{30}\)。
2.1.3 负载因子(DEFAULT_LOAD_FACTOR)
默认负载因子是0.75f,即预示着当表中节点个数>当前table数组大小*0.75时会进行扩容(扩大两倍)操作,即在默认情况下,节点个数>12时会进行扩容操作,但是注意是节点个数,并不是table数组的使用个数,因为存在哈希冲突的情况。
具体这个0.75的大小,源码给出的原因是基于哈希冲突和空间利用率的一种折中选择。这个值是可以通过构造方法进行改变的,但一般不建议改变。另外不同语言中对于哈希表负载因子都不同也能说明这一点,比如Java 是 0.75,Dart 中是0.8,python 中是0.762。另外也可以参考StackOverFlow中基于二项分布的推导结果是接近ln2~0.69时最优。
2.1.4 树化阈值(TREEIFY_THRESHOLD)
当table数组中一条链表的长度>8时,且当前table数组大小大于64时,链表会转换为红黑树,但是当table数组<=64时即使存在大于8的链表长度也会优先考虑扩容,8这个数值的来源源码中有解释
* Because TreeNodes are about twice the size of regular nodes, we
* use them only when bins contain enough nodes to warrant use
* (see TREEIFY_THRESHOLD). And when they become too small (due to
* removal or resizing) they are converted back to plain bins. In
* usages with well-distributed user hashCodes, tree bins are
* rarely used. Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
大致就是因为树化后每个节点要存储两个孩子节点,所以从空间上讲大于链表,所以链表长度短的情况下不需要树化,另外也不能太长,不然查找复杂度过高,而引入红黑树就是为了降低查找的复杂度。
所以这里假设我们在链表长度为k的时候进行树化,理想情况下,使用随机哈希码,table数组中,节点频率分布服从泊松分布,观察对于table数组中某一个桶的即将放入一个节点的概率,考虑放or不放,抽象成一个二项分布,那么对于整个table和要放入节点个数的关系即服从期望E为0.5的泊松分布,概率公式为
则我们需要找到一个出现概率尽可能小的k的值,带入\(E = 0.5\) 以及不同的k值,即可得到上面的结果,即树化阈值为8时,树化的概率小于百万分之一。
所以树化是一个比较极端的情况。
2.2 构造方法
HashMap的构造方法有四个
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(Map<!--? extends K, ? extends V--> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
可以很明显的看出,前两个构造方法可以设置初始化的容量和负载因子大小(一般情况下推荐使用默认的构造方法),第三个构造方法就是常用的,一切值都选择默认大小,比如负载因子默认大小0.75,table数组默认大小16。
第四个是传入一个别的map参数,将传入的map复制到当前map。
2.3 Get方法
public V get(Object key) {
Node<k,v> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<k,v> getNode(int hash, Object key) {
Node<k,v>[] tab; Node<k,v> first, e; int n; K k;
//根据哈希值找到table中相应的桶位置,关键点在于(n - 1) & hash
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//如果第一个节点即为key,则返回key所对应的value
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//如果第一个节点不是所求,则从所在桶的后续节点查找
if ((e = first.next) != null) {
//如果所在的桶已经转换成红黑树,则调用红黑树的方法查找
if (first instanceof TreeNode)
return ((TreeNode<k,v>)first).getTreeNode(hash, key);
//如果是链表则依次遍历查找
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
上面是get方法的源码,重要部分已经做了必要的中文注释,总结一下整个查找元素的步骤。
- 根据计算出的hash值,计算(n - 1) & hash即可得到将要查找的key值在桶中的映射。
- 如果第一个节点即为所求则返回。
- 如果不是则判断是否为红黑树结构,是红黑树调用红黑树的查找方法。
- 如果不是红黑树则映射到的桶中为链表结构,依次遍历寻找符合要求的值。
重点看一下(n - 1) & hash是如何通过取模将key值映射到桶中的。
假设n为初始大小,则n的二进制值为10000,所以n-1即为1111,但这里注意一点,实际上n是一个int型数值,所以他是占32位的,所以n-1实际上是0000 0000 0000 0000 0000 0000 0000 1111,所以对于任意一个数值和n-1做与运算,实际上就是取了hash值的低四位。
这也解释了为什么桶的大小需要是2的幂,因为可以更好的进行取模运算。
2.4 Put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<k,v>[] tab; Node<k,v> p; int n, i;
//如果当前hashmap为空则通过resize()初始化,默认大小16,负载因子0.75
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//计算映射结果,若为空,则新建一个node插入参数中的key和value
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//若不为空
else {
Node<k,v> e; K k;
//判断第一个节点是否为将要插入的节点,如果是,直接覆盖
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果当前映射的桶是红黑树结构,则调用红黑树方法插入
else if (p instanceof TreeNode)
e = ((TreeNode<k,v>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果是链表结构则依次遍历
for (int binCount = 0; ; ++binCount)
//找到链表结尾插入
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果当前链表长度大于树化阈值则转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果发现了已经存在的key则break,并在后面进行覆盖操作
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//接上面,覆盖value值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//记录更新次数
++modCount;
//如果大于阈值,则扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
因为插入操作需要判断的条件比较多,所以看起来比较复杂。但大致可以归为一下几个步骤
- 判空,是则初始化。
- 通过(n - 1) & hash取模计算映射的桶的位置,如果位置为空,则直接插入转6,如果不为空则继续3
- 判断第一个节点是否是将要插入的key,如果是,则直接覆盖value值,如果不是则接4
- 判断当前桶的节点是否处于红黑树结构中如果是则使用红黑树插入方法进行插入并转6,否则是链表转5
- 依次遍历若整个链表不存在将要插入的key,则在链表结尾插入新的节点,并判断是否超过树化阈值,是则转换为红黑树,若存在将要插入的key则结束链表的遍历,进行覆盖操作,转6。
- 记录更新次数,如果当前节点个数大于扩容阈值(负载因子*桶的大小)则扩容。
另外可以很显然的看出插入操作不是线程安全的,因为存在多种例如++等非原子操作,所以在多线程环境下应该使用ConcurrentHashMap。
2.5 扩容
Initializes or doubles table size. If null, allocates in accord with initial capacity target held in field threshold.Otherwise, because we are using power-of-two expansion, the elements from each bin must either stay at same index, or move with a power of two offset in the new table.
先看一下jdk1.8中对于resize()函数的描述,如果当前table数组为空则根据默认值初始化,否则就对table数组的容量扩容,具体扩容方法就是变成原来的两倍,相当于table大小n往左移一位变成2*n。那么接下来,相应元素在扩容后的新的map中要么位置不变,要么移动n位。
举个例子解释上面这句话,还是用上面get函数中的栗子,假设n为初始大小16,则n的二进制值为10000,所以n-1即为1111,但这里注意一点,实际上n是一个int型数值,所以他是占32位的,所以n-1实际上是0000 0000 0000 0000 0000 0000 0000 1111,对于任意一个hash值和n-1做与运算,实际上就是取了hash值的低四位。
比如hash计算出结果为2333,其二进制为0000 0000 0000 0000 0000 1001 0001 1101,那么在容量为n的情况下,我们使用(n - 1) & hash进行计算得到的是其低四位1101。即hash值为2333的key,应该在容量为n的table数组的第13个位置 ,而扩容后,容量变为2*n,则(2n - 1)的二进制变成了11111,所以(2n - 1) & hash操作取的是hash值得低五位,得到映射结果11101,那么在新的table数组中,他的位置是第21个位置,相当于发生了原table数组大小n的偏移。
final Node<k,v>[] resize() {
Node<k,v>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
//扩容
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//设置阈值
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<k,v>[] newTab = (Node<k,v>[])new Node[newCap];
table = newTab;
//第三部分:旧数据保存在新数组里面
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<k,v> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//只有一个节点,通过索引位置直接映射
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//如果是红黑树,需要进行树拆分然后映射
else if (e instanceof TreeNode)
((TreeNode<k,v>)e).split(this, newTab, j, oldCap);
else {
//如果是多个节点的链表,将原链表拆分为两个链表
Node<k,v> loHead = null, loTail = null;
Node<k,v> hiHead = null, hiTail = null;
Node<k,v> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//链表1存原索引
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//链表2存原索引加上原hash桶长度的偏移量
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}

