

1、memcache基本简介
memcached是高性能的分布式内存缓存服务器。一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、提高可扩展性。
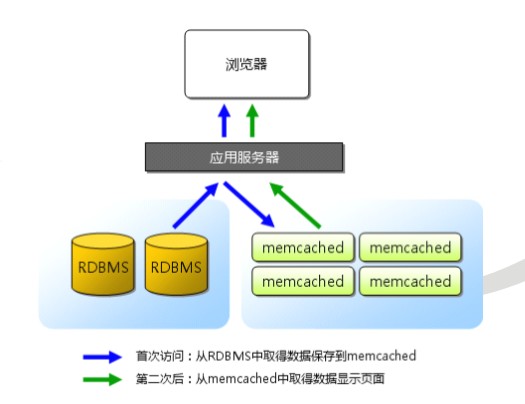
Memcache的运行图:
Memcache的特征
memcached作为高速运行的分布式缓存服务器,具有以下的特点。
1、基于C/S架构协议简单
memcached的服务器客户端通信并不使用复杂的XML等格式,而使用简单的基于文本行的协议。 因此,通过telnet也能在memcached上保存数据、取得数据。
2、基于libevent的事件处理
libevent是个程序库,它将Linux的epoll、BSD类操作系统的kqueue等事件处理功能封装成统一的接口。即使对服务器的连接数增加,也能发挥O(1)的性能。memcached使用这个libevent库,因此 能在Linux、BSD、Solaris等操作系统上发挥其高性能。
3、内置内存存储方式
为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重启memcached、重启操作系统会导致全部数据消失。另外,内容容量达到指值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。memcached本身是为缓存 而设计的服务器,因此并没有过多考虑数据的永久性问题。
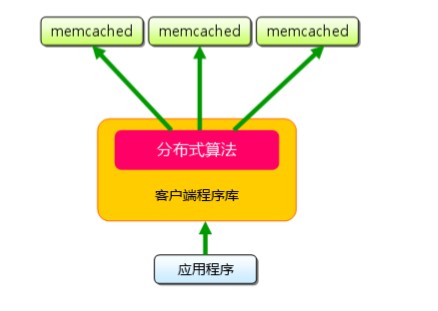
4、memcached不互相通信的分布式
memcached尽管是“分布式”缓存服务器,但服务器端并没有分布式功能。各个memcached不会互 相通信以共享信息。那么,怎样进行分布式呢?这完全取决于客户端的实现。(如下图所示)
2、理解memcache的内存存储
2.1、存储机制
Memcache采用的是Slab Allocator方式进行存储数据。这一机制可以很好的整理内存,以便重复利用,从而解决了内存碎片的问题。在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached进程本身还慢。
2.2、Slab Allocator基本原理
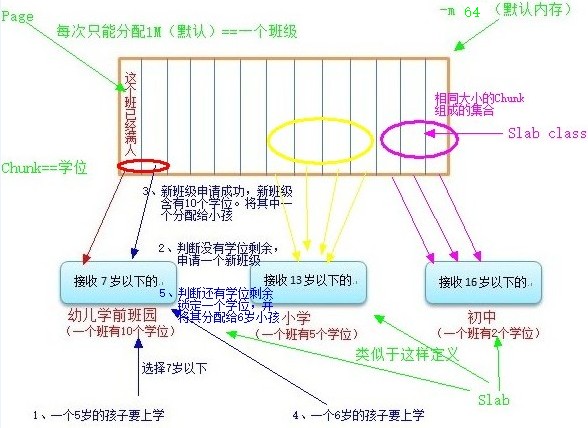
1、按照预先规定的大小,将分配的内存以page(默认每个page为1M)为单位分为特定的块(chunk),并且把相同大小的chunk分成组(chunk的集合);
2、存储数据时,将会寻找与value大小相近的chunk区域进行存储;
3、内存一旦以page的形式分配出去,在重启前不会被回收或者重新分配,以解决内存碎片问题。(分配的内存不会释放,而是重复利用)
2.3、理解四个名词
【可参考下面的形象解析图进行理解】
Slab
用于表示存储的最大size数据,仅仅只是用于定义(通俗的讲就是表示可以存储数据大小的范围)。默认情况下,前后两个slab表示存储的size以1.25倍进行增长。例如slab1为96字节,slab2为120字节
Page
分配给Slab的内存空间,默认为1MB。分给Slab后将会根据slab的大小切割成chunk
Chunk
用于缓存记录的内存空间
Slab calss
特定大小的Chunk集合
2.4、Slab的内存分配具体过程
Memcached在启动时通过-m参数指定最大使用内存,但是这个不会一启动就占用完,而是逐步分配给各slab的。如果一个新的数据要被存放,首先选择一个合适的slab,然后查看该slab是否还有空闲的chunk,如果有则直接存放进去;如果没有则要进行申请,slab申请内存时以page为单位,无论大小为多少,都会有1M大小的page被分配给该slab(该page不会被回收或者重新分配,永远都属于该slab)。申请到page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个chunk的数组,再从这个chunk数组中选择一个用于存储数据。若没有空闲的page的时候,则会对改slab进行LRU,而不是对整个memcache进行LRU。
形象解析图:(这图凑合凑合就好了哈,不是很专业2333)
2.5、Memcache存储具体过程
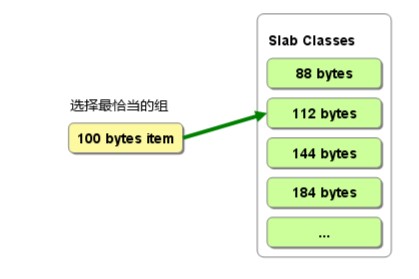
Memcached并不是将所有大小的数据都放在一起的,而是预先将数据空间划分为一系列slabs,每个slab只负责一定范围内的数据存储。memcached根据收到的数据的大小,选择最适合数据大小的slab。假若这个slab仍有空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中;若无则申请page(1M)【可以参考上面我画的形象图23333】
具体分析:从上面我们了解到slab的作用。Slab的增长因子默认以1.25倍进行增长。那为什么会导致有些不是1.25倍呢?答案是受小数的影响,你可以使用-f int测试个整数增长因子看看效果。【后面具体讲解】
以下图进行分析,例如slab中112字节,表示可以存储大于88字节且小于或等于112字节的value。
2.6、Slab Allocator缺点
Slab Allocator解决了当初的内存碎片问题,但新的机制也给memcached带来了新的问题。
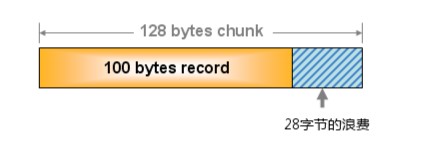
这个问题就是,由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如,将100字节 的数据缓存到128字节的chunk中,剩余的28字节就浪费了(如下图所示)。
2.7、使用-f增长因子进行调优
增长因子就是相邻两个chunk之间的增长倍数。这个参数memcache默认是1.25,但是我们先采用整数2来测试一下,看看效果。
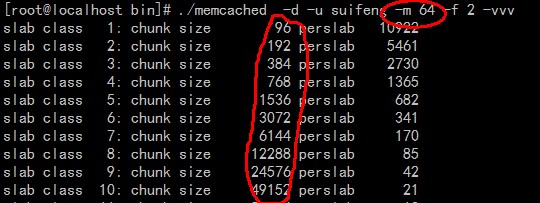
由图中我们可以看到chunk size的增长是2倍的。
我们再来看看-f 1.25的效果
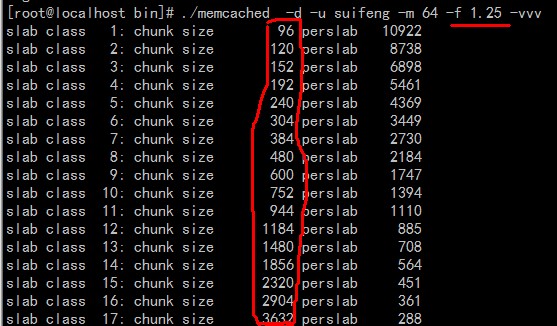
为什么1.25倍增长因子就不能保证全部相邻的chunk size是1.25倍增长呢?
因为这些误差是为了保持字节数的对齐而故意设置的。
两图一对比,可见,因子为1.25组间差距比因子为2时小得多,更适合缓存几百字节的记录。
因此,使用memcached时,最好是重新计算一下数据的预期平均长度,调整growth factor,以获得最恰当的设置。
3、memcache删除机制
从上面我们知道,已经分配出去的内存是不会被释放回收的,记录超时后,客户端就无法看到该记录,其存储空间即可重复使用。
3.1、Lazy Expiration
memcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。这种技术被称为lazy(惰性)expiration。因此,memcached不会在过期监视上耗费CPU时间。
3.2、LRU删除
memcached会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不足的情况, 此时就要使用名为Least Recently Used(LRU)机制来分配空间。顾名思义,这是删除“最近最少 使用”的记录的机制。因此,当memcached的内存空间不足时(无法从slab class获取到新的空间时),就从最近未被使用的记录中搜索,并将其空间分配给新的记录。从缓存的实用角度来看,该模型十分理想。
不过,有些情况下LRU机制反倒会造成麻烦。memcached启动时通过“M”参数可以禁止LRU。

启动时必须注意的是,小写的“m”选项是用来指定最大内存大小的。不指定具体数值则使用默认 值64MB。
指定“M”参数启动后,内存用尽时memcached会返回错误。话说回来,memcached毕竟不是存储器,而是缓存,所以推荐使用LRU。
4、启动memcache参数
【黑体字的参数较为常用】
|
-p<num> |
监听的TCP端口(默认:11211) |
|
-U<num> |
UDP监听端口(默认:11211 0关闭) |
|
-d |
以守护进程方式运行 |
|
-u<username> |
指定用户运行 |
|
-m<num>. |
最大内存使用,单位MB。默认64MB |
|
-c<num> |
最大同时连接数,默认是1024 |
|
-v |
输出警告和错误消息 |
|
-vv |
打印客户端的请求和返回信息 |
|
-h |
帮助信息 |
|
-l<ip> |
绑定地址(默认任何ip地址都可以访问) |
|
-P<file> |
将PID保存在file文件 |
|
-i |
打印memcached和libevent版权信息 |
|
-M |
禁止LRU策略,内存耗尽时返回错误 |
|
-f<factor> |
增长因子,默认1.25 |
|
-n<bytes> |
初始chunk=key+suffix+value+32结构体,默认48字节 |
|
-L |
启用大内存页,可以降低内存浪费,改进性能 |
|
-l |
调整分配slab页的大小,默认1M,最小1k到128M |
|
-t<num> |
线程数,默认4。由于memcached采用NIO,所以更多线程没有太多作用 |
|
-R |
每个event连接最大并发数,默认20 |
|
-C |
禁用CAS命令(可以禁止版本计数,减少开销) |
|
-b |
Set the backlog queue limit (default: 1024) |
|
-B |
Binding protocol-one of ascii, binary or auto (default) |
|
-s<file> |
UNIX socket |
|
-a<mask> |
access mask for UNIX socket, in octal (default: 0700) |
5、Memcache指令汇总
|
指令 |
描述 |
例子 |
|
get key |
#返回对应的value |
get mykey |
|
set key 标识符 有效时间 长度 |
key不存在添加,存在更新 |
set mykey 0 60 5 |
|
add key标识符 有效时间 长度 |
#添加key-value值,返回stored/not_stored |
add mykey 0 60 5 |
|
replace key标识符 有效时间 长度 |
#替换key中的value,key存在成功返回stored,key不存在失败返回not_stored |
replace mykey 0 60 5 |
|
append key标识符 有效时间 长度 |
#追加key中的value值,成功返回stored,失败返回not_stored |
append mykey 0 60 5 |
|
prepend key标识符 有效时间 长度 |
#前置追加key中的value值,成功返回stored,失败返回not_stored
|
prepend mykey 0 60 5 |
|
incr key num |
#给key中的value增加num。若key中不是数字,则将使用num替换value值。返回增加后的value |
Incre mykey 1 |
|
decr |
#同上 |
同上 |
|
delete key [key2…] |
删除一个或者多个key-value。成功删除返回deleted,不存在失败则返回not_found |
delete mykey |
|
flush_all [timeount] |
#清除所有[timeout时间内的]键值,但不会删除items,所以memcache依旧占用内存 |
flush_all 20 |
|
version |
#返回版本号 |
version |
|
verbosity |
#日志级别 |
verbosity |
|
quit |
#关闭连接 |
quit |
|
stats |
#返回Memcache通用统计信息 |
stats |
|
stats slabs |
#返回Memcache运行期间创建的每个slab的信息 |
stats slabs |
|
stats items |
#返回各个slab中item的个数,和最老的item秒数 |
stats items |
|
stats malloc |
#显示内存分配数据 |
stats malloc |
|
stats detail [on|off|dump] |
#on:打开详细操作记录、off:关闭详细操作记录、dump显示详细操作记录(每一个键的get、set、hit、del的次数) |
stats detail on stats detail off stats detail dump |
|
stats cachedump slab_id limit_num |
#显示slab_id中前limit_num个key |
stats cachedump 1 2 |
|
stats reset |
#清空统计数据 |
stats reset |
|
stats settings |
#查看配置设置 |
stats settings |
|
stats sizes |
#展示了固定chunk大小中的items的数量 |
Stats sizes |
注意:标识符:一个十六进制无符号的整数(以十进制来表示),需和数据一起存储,get的时候一起返回
ps:最近老是思考以后的方向,感觉有点迷茫,都不能好好学习了。要尽快调整好心态,切勿浮躁,欲速则不达。
参考资料:
1、Memcached原理与使用详解 作者:heiyeluren(黑夜路人)
http://blog.csdn.net/heiyeshuwu
2 、memcached 全面剖析 作者:长野雅广、前坂徹 charlee 译
3、Memcache 内存分配策略和性能(使用)状态检查 作者:jyzhou

