Python+Selenium学习(三)-Xpath的使用
今天学习了几个关于自动化的概念。
元素,网页元素(web element)。在页面上面的文本输入框、按钮、多选、单选、标签、和文字都叫元素,总之,凡是能在页面显示的对象都可以作文页面元素对象。
元素定位,有时候也叫Locator,一个HTML页面元素,可以用很多方法描述这样元素的位置。网页元素有自己的位置,可以通过一些手段或者表达式去描述这个元素的页面对应位置。
XPath,XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中寻找节点的能力,Xpath很快的被开发者采用来作为小型查询语言。
Selenium一共有八种元素定位方法,其中,在实际开发自动化脚本过程中,XPath的使用是最多的一种方法。
一、Try Xpath的安装
在Selenium中准确定位到要操作的网页元素是首要事情,之前在火狐中一直使用的是Firebug和Firepath,通过这两个插件验证Xpath和CSS Selector表达式。
但是火狐在更新到57版本之后,对这些使用旧技术实现的插件都不在支持。所以我安装使用的是Try Xpath。这个插件也可以帮助我们验证Xpath以及CSS Selenium能不能定位到预期的网页元素,并且可以提供表达式具体定位到多少个元素的准确信息。
安装步骤:
1.打开火狐浏览器FireFox57以上的版本;
2.在火狐菜单中选择【附加组件管理器】;
3.在寻找更多扩展里面搜索【Try Xpath】;
4.点击安装Try Xpath;
5.点击后,用户会进入到Try Xpath这个插件页面,点击页面上的“添加到Firefox”按钮;
6.在要求获取权限的提示中,点击“添加”;
7.这样就可以看到Try Xpath添加成功的提示信息;
8.在火狐右上角就可以看到一个TX的蓝色图标,说明安装成功了!!
二、Try Xpath的使用
1.点击右上角的TX蓝色图标
2.在way这个下拉框下有很多选项,要验证Xpath的话,要选择“Xpath ANY_TYPE”
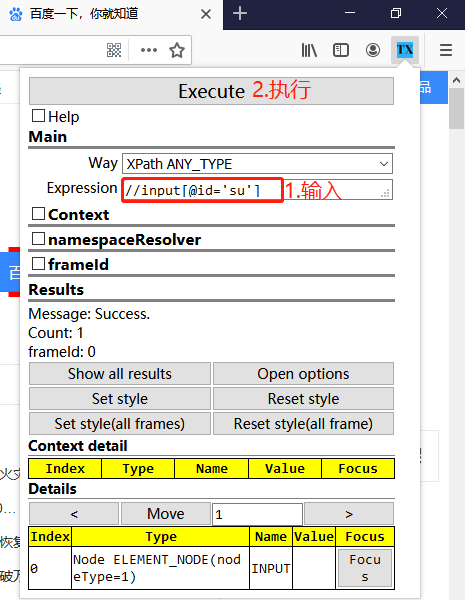
3.如果Xpath表达式唯一定位到了预期元素,Try Xpath会用红色虚线框吧元素框起来,并且在Result部分的Count中会显示计数为1;
4.当表达式定位到多个元素时,TryXpath会把所有元素都使用红色虚线框起来,并且在Result Count中显示准确的数量,这个时候可以使用Details下面的focus按钮来定位你要定位的元素,但是最好能够再优化下表达式,让表达式精确的唯一的定位到你要操作的网页元素,否则脚本在运行时会不稳定容易报错;
三、Xpath定位之text()方法
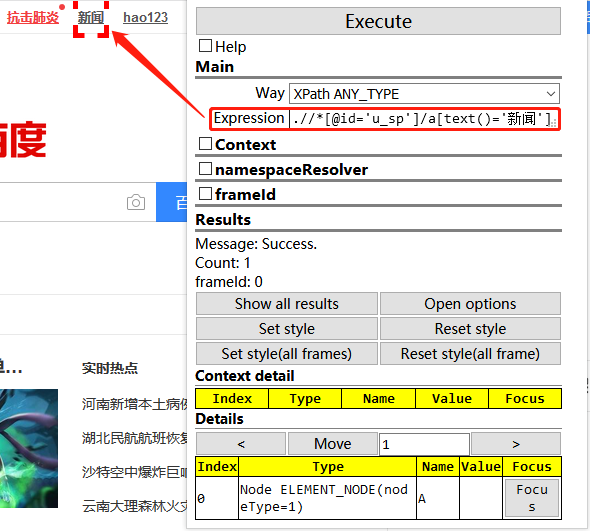
例:百度首页右上角“新闻”
 五、Xpath定位之contains()方法
五、Xpath定位之contains()方法
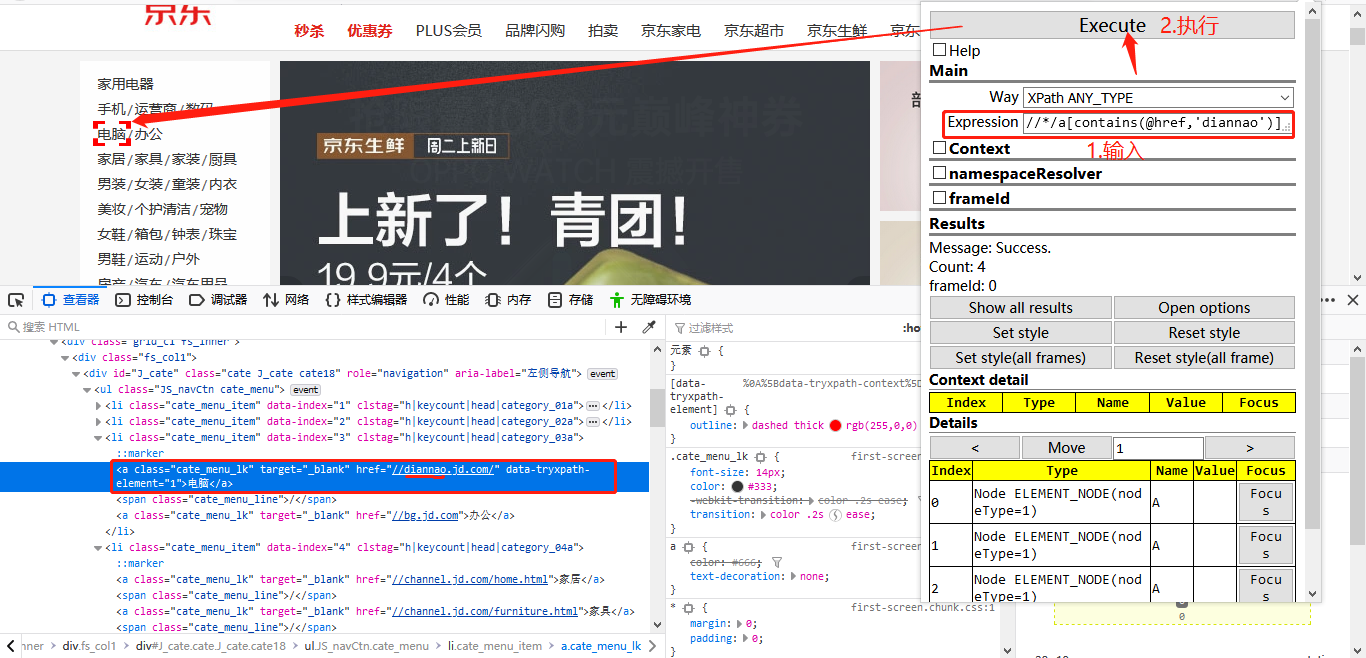
有时候,我们不喜欢写很长的XPath表达式,而且节点信息里面,有些信息是动态的,每次都获取都不一样,这个时候contains()方法就很好用。
例:JD首页左侧电脑菜单
六、Xpath定位之相对Xpath路径
有时目标元素的节点信息很少,不足够用来精确定位到目标元素,这个时候,我们就需要考虑,利用目标元素上下附件节点,通过确定附件的节点从而确定目标元素,这种方式叫相对路径。
A.直接定位标签
//input #//标识定位到某一个标签,//*则代表所有标签,//input则定位所有input标签
B.标签+属性匹配
//input[@id='kw'] 或者//input[@type='text'] #由一个标签+某一个属性的组合 ,其中@代表匹配属性名称,相当于匹配所有的input标签并匹配属性id=kw的元素
C.标签和多个属性
//input[@id='kw' and @type='text'] #由一个标签+多个属性的组合,相当于匹配了所有的input标签并匹配属性id=kw且属性type=text的元素
//input[@id='kw' or @type='text'] #由一个标签+多个属性的组合,相当于匹配了所有的input标签,并匹配属性id=kw或者属性type=text的元素
D.父子定位
//form[@id="form"]/input #相当于先定位到了父节点,再找到对应的子节点,常用语当前元素不易定位而父节点较易定位的情况
E.contains
//input[contains(@id,'w')] #相当于匹配了所有的input标签且id属性包含字符串"w"的元素 (模糊定位)
//a[contains(text(),'新闻')] #相当于匹配了所有的input标签且文本包含"新闻" (模糊定位)
F.start-with和ends-with
//input[starts-with(@id,'k')] #相当于匹配了所有的input标签且属性id以字母k开头的元素 (模糊定位)
//input[ends-with(@id,'w')] #相当于匹配了所有的input标签且属性id以字母w结尾的元素 (模糊定位)
G.文本定位
//a[text()='新闻'] #精准定位到本文属性,contains则是模糊定位
H.关系定位方式(通过子节点找父节点、爷节点;兄弟节点或者堂兄弟等等)

1.子节点找父节点
//input[@id="kw"]/.. #相当于我们精确定位到了查询输入框,然后找他的父节点,往回走一层(根据层级关系)
//input[@id="kw"]/parent::span
2.兄弟节点
//input[@id="kw"]/../span #相当于找到了父节点再往下找子节点(兄弟节点)
//input[@id="kw"]/following-sibling::a #往下找兄弟节点,也可以写//input[@id="kw"]/following-sibling::a[1],定位到后面的第几个a标签
//input[@id="kw"]/preceding-sibling::span #往上找兄弟节点,也可以写//input[@id="kw"]/preceding-sibling::span[1],定位到前面的第几个span标签
同理可以找到相关的爷爷节点,堂兄弟节点等等
七、使用Try Xpath验证CSS Selector
验证CSS Selector和验证Xpath的使用方式基本一样
1.在Way中选择“querySelectorAll”选项;
2.在Expression中输入的是要验证CSS Selector表达式,点击Execute按钮;
Try Xpath 同样会把匹配到的元素使用红色虚线框出来。
参考文章:https://blog.csdn.net/yoyocat915/article/details/80167671
参考文章:https://www.cnblogs.com/xiaopeng4Python/p/10595086.html
参考文章:https://blog.csdn.net/u011541946/article/details/67639423

 浙公网安备 33010602011771号
浙公网安备 33010602011771号