ElasticJob特性浅谈及应用
ElasticJob浅谈
1 什么是Elastic-Job
Elastic-Job是当当网开源的一个分布式调度解决方案,基于Quartz二次开发的,由两个相互独立的子项目ElasticJob-Lite和Elastic-Job-Cloud组成。Elastic-Job-Lite,它定位为轻量级无中心化解决方案,使用Jar包的形式提供分布式任务的协调服务,而Elastic-Job-Cloud子项目需要结合 Mesos 以及Docker在云环境下使用。ElasticJob-Lite架构如下:
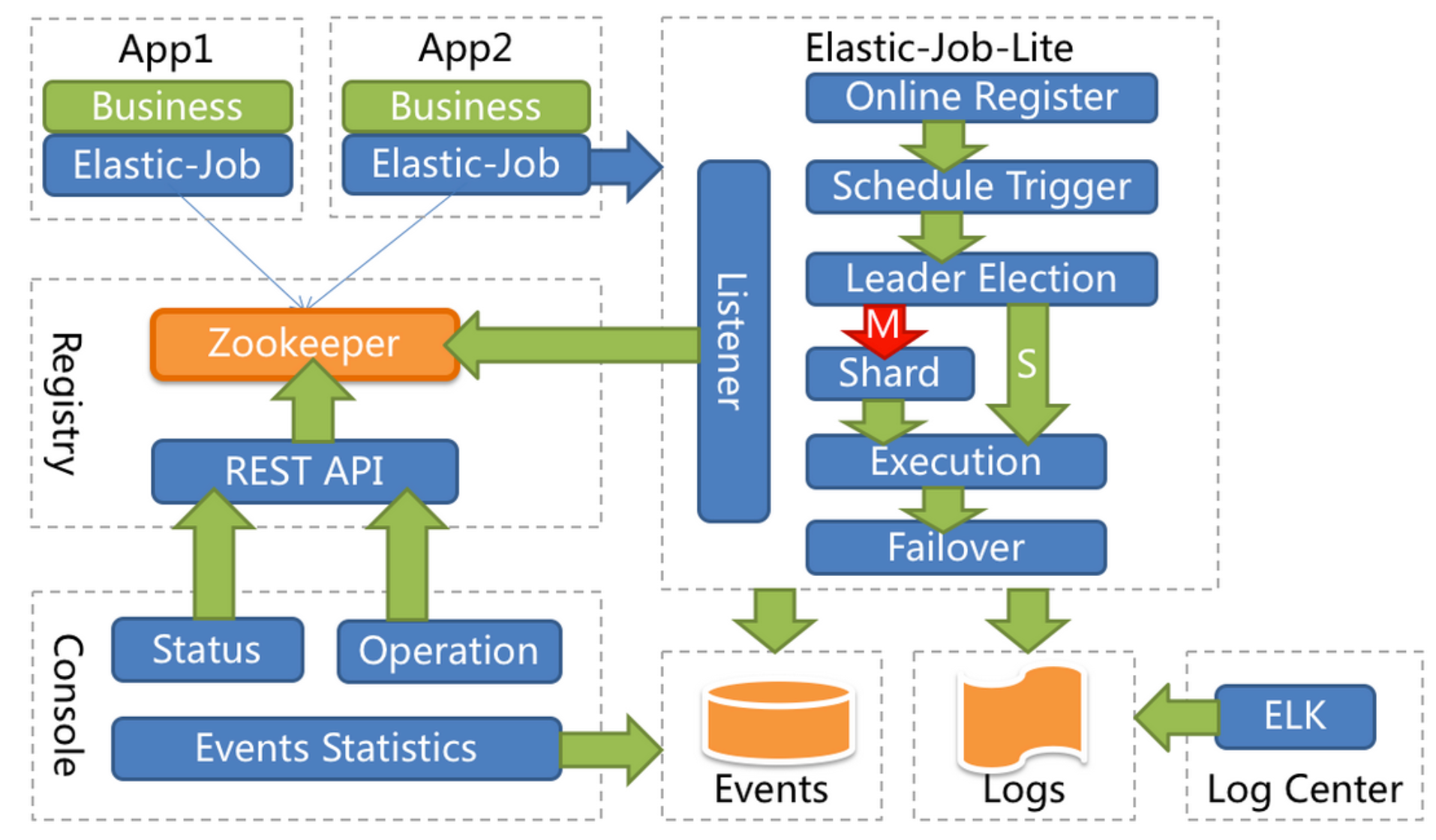
二者的api一样只是部署方式有区别,后者是针对微服务方式部署的
Elastic-Job是基于quartz开发的,并借助zookeeper实现动态扩容缩容,故障转移,分片策略等。
在介绍elastic-job之前首先思考一个问题:为什么要分布式定时任务?单机定时任务有哪些局限性?分布式定时任务解决了什么问题?
单机定时任务:
- 随着服务流量的增加,分布式架构应运而生,如果现在有一个服务需要定时的给用户推送消息,但是打到这个服务上的流量又特别多,导致服务特别容易挂,首先想到的是横向增加节点缓解服务器压力,但是与此同时多个节点也会同时推送多条消息,所以想到把所有定时任务抽离出来,建立一个专门执行定时任务的服务,但是这个服务也不能挂,所以考虑搭建主备架构,但是随着任务的增加,任务量的增重,定时任务节点的能否经得住压力的考验?单机情况下如何做到定时任务不丢不重?
1.1 Elastic-job的主要功能
分布式调度协调:在分布式环境中,任务能够按指定的调度策略执行,并且能够避免同一任务多实例重复执行丰富的调度策略:基于成熟的定时任务作业框架Quartz cron表达式执行定时任务弹性扩容缩容:当集群中增加某一个实例,会重新分片为新实例分配任务;当集群减少一个实例时,它所执行的任务能被转移到别的实例来执行。故障转移:某实例在任务执行失败后,会被转移到其他实例执行错过执行作业重新执行:若因某种原因导致作业错过执行,自动记录错过执行的作业,并在上次作业完成后自动触发。支持并行调度:支持任务分片,任务分片是指将一个任务分为多个小任务项在多个实例同时执行。高可扩展:预留监听器接口和自定义分片策略接口以实现多种的个性化定制功能。丰富的作业类型:支持简单定时任务,流式定时任务,以及脚本类型的定时任务
1.2 弹性伸缩实现
ElasticJob的“elastic”主要体现在其弹性伸缩,其分布式弹性伸缩的实现如下描述:
- 第一台服务器上线触发主服务器选举。主服务器一旦下线,则重新触发选举,选举过程中阻塞,只有主服务器选举完成,才会执行其他任务;
- 某作业服务器上线时会自动将服务器信息注册到注册中心,下线时会自动更新服务器状态;
- 主节点选举,服务器上下线,分片总数变更均更新重新分片标记;
- 定时任务触发时,如需重新分片,则通过主服务器分片,分片过程中阻塞,分片结束后才可执行任务。如分片过程中主服务器下线,则先选举主服务器,再分片;
- 通过上一项说明可知,为了维持作业运行时的稳定性,运行过程中只会标记分片状态,不会重新分片。分片仅可能发生在下次任务触发前;
- 每次分片都会按服务器 IP 排序,保证分片结果不会产生较大波动;
- 实现失效转移功能,在某台服务器执行完毕后主动抓取未分配的分片,并且在某台服务器下线后主动寻找可用的服务器执行任务。
1.3 对比xxl-job
先说一下和xxl-job的相同点和区别:二者都是在基于quartz的基础上二次开发,不同的点在于xxl-job使用quartz基于数据库的分布式功能,服务器超出一定数量会给数据库造成一定的压力(调度中心通过获取DB锁来保证集群中执行任务的唯一性,如果短任务很多,随着调度中心集群数量增加,那么数据库的锁竞争会比较大,性能会随之降低。)
而Elastic-Job是基于zookeeper实现分布式,也就是基于内存的分布式调度,利用zk的临时节点和 watch 机制来实现节点上线下线对应的动作,并且zk底层采用nio、多线程模型,所以它的性能非常高。
2 ElasticJob的功能及应用
elasticjob内置zkclient,采用zk作为分布式协调注册中心,利用zk的全局一致性,以及具备的监听和反向通知的功能,通过在zkServer上写入永久/临时节点,实现定时任务的分片、主节点选举、注册信息等。关于zookeeper的介绍和原理可以参考:zookeeper漫谈,zookeeper源码解读。
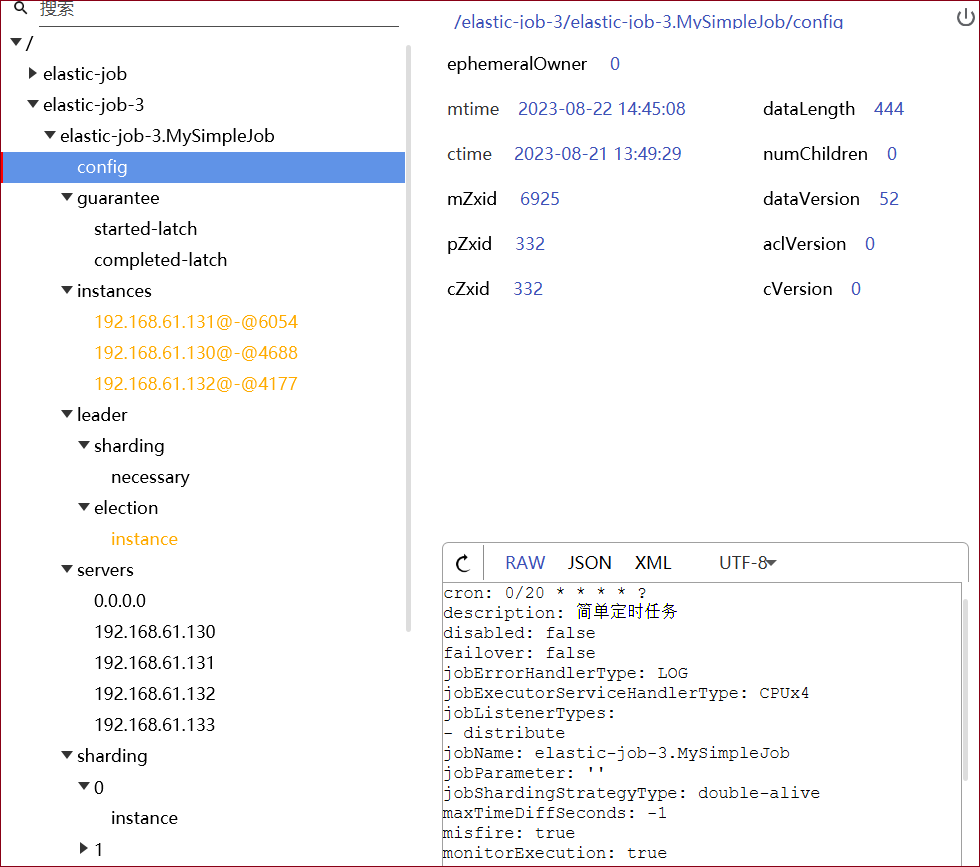
下图为zk客户端显示elasticjob注册3台实例:
2.1 分片
分片是指一个任务可以由多个实例执行。elastic-job自带三种分片策略,分别是平均分片、根据作业名的哈希值奇偶性分片、根据作业名的轮询分片。默认平均分片。提供接口实现自定义分片。
分片可以实现什么?
如果想要将作业分治提高效率,例如2w条数据同步,可以将数据同步任务分为4片,以提高效率增加容错,并且,当你的节点数小于分片数时,任务也不会停止——转而由多线程执行代替节点执行(高可用);如果想要提高某个定时任务的高可用性,那么可以将任务分为1片,并启动多个实例,这样就可以在leader宕机时,重新选举并继续执行任务,节点重新上线时会加入到备用节点。
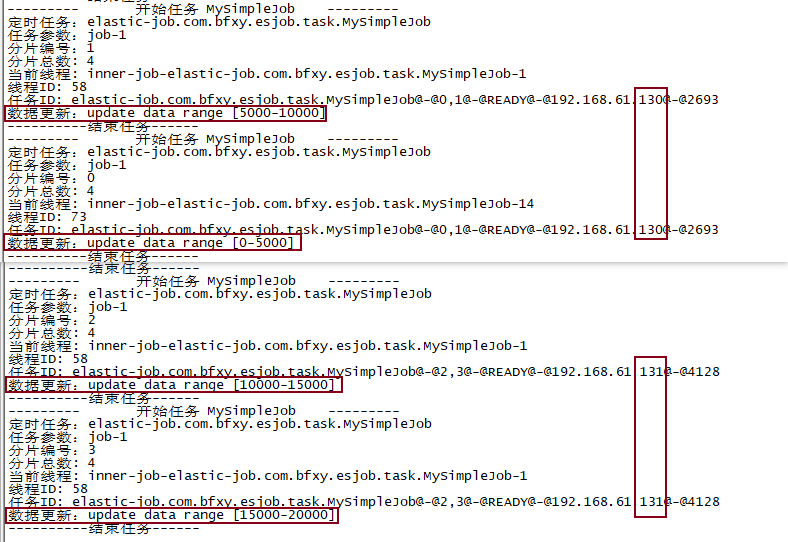
自定义分片可以实现什么?
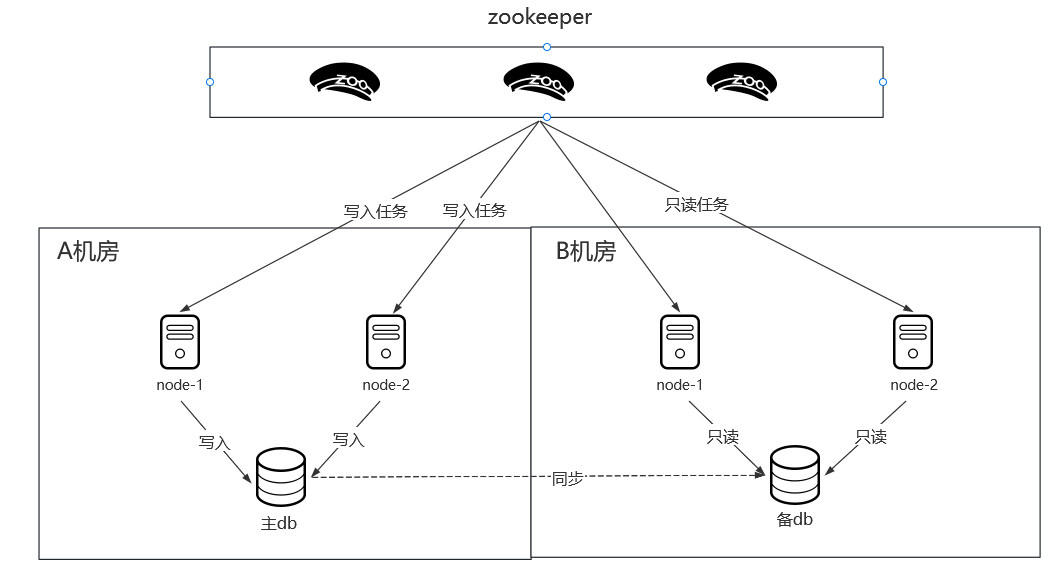
就近调度。假设现在有两个机房,A机房作为主数据源,B机房全部作为备用节点,如果所有任务都在B机房被调度了,那么这些数据都会跨机房写入A机房,这样延迟就大大提升了。自定义分片可以解决:根据主节点ip白名单,分片时写入任务优先分配给主机房执行,当主机房全部宕机启用备用机房执行。
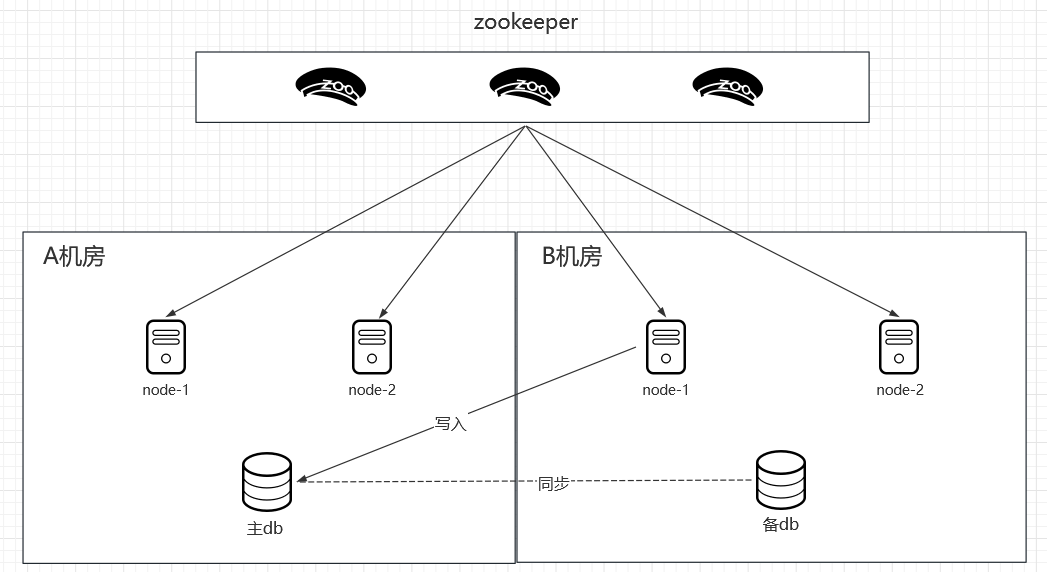
同城双活。双机房的架构进一步实现了高可用——防止机房断电带来的灾难性损失。但是这种模式存在一个问题就是大部分时间B机房都是空闲状态,极大浪费资源的同时,对于B机房可能存在的一些问题我们是不清楚的,例如数据库权限。没有流量的验证,当真正出现容灾问题我们不能保证B机房一定可用。因此在此基础上更进一步地实现同城双活:即在备用机房上承担一部分流量,如分片时根据任务列表把所有只读任务优先分配到备用机房,或是将任务列表末尾的1/10分配给B机房。
2.2 监听器
elastic-job提供监听器接口以实现执行任务前后的预处理和后处理。监听器分为本地监听器和分布式监听器,本地监听器会在每一个分片执行前后都触发;分布式监听器会在所有分片执行前后分别触发。
本地监听器:

分布式监听器:
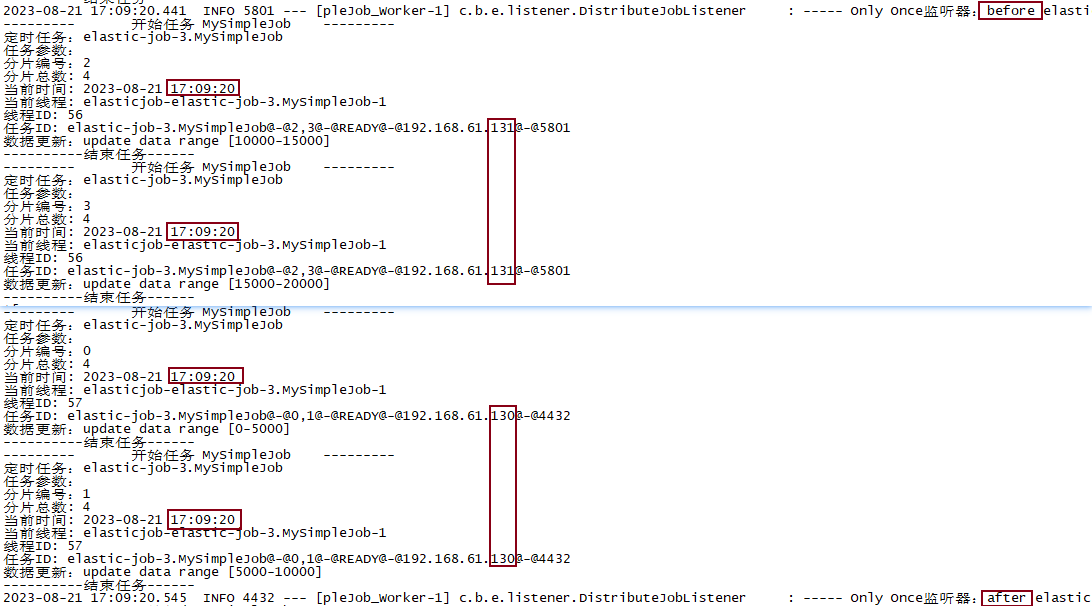
在版本号 <= 2.1.5之前的,此功能会出现分布式执行bug,导致多分片同时触发监听器,并没有达到”只执行一次”的目的,2.1.7的版本解决方案为:
3.0.3解决方案为:先为所有分片创建guarantee节点,当所有节点都标记为启动后,调用leader节点执行doBefore/doAfter,并加上guarantee下的zk锁

2.3 失效转移
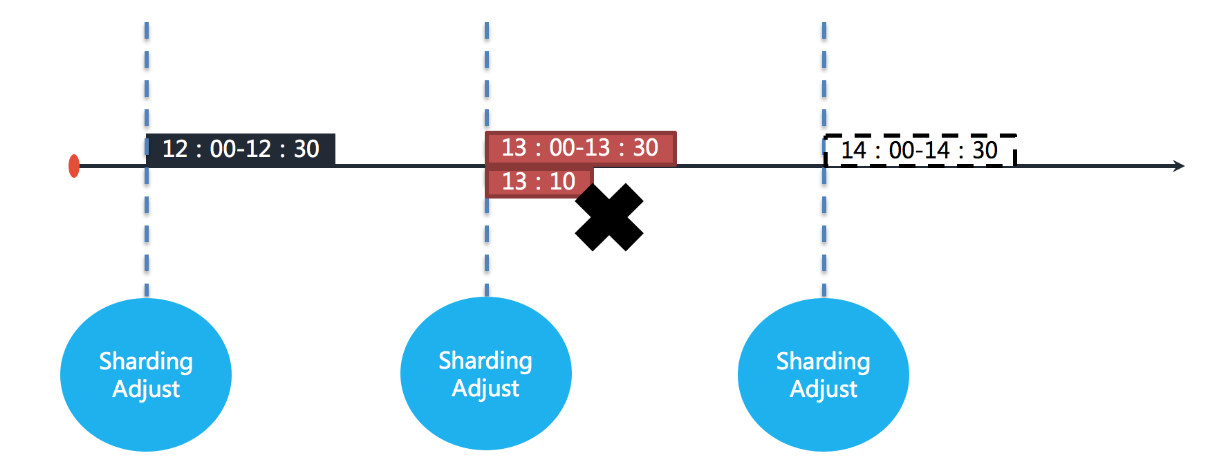
ElasticJob 不会在执行过程中进行重新分片,而是等待下次调度之前才开启重新分片流程。当作业执行过程中服务器宕机,失效转移允许将该次未完成的任务在另一作业节点上补偿执行。例如作业执行间隔1小时,执行时间30分钟:
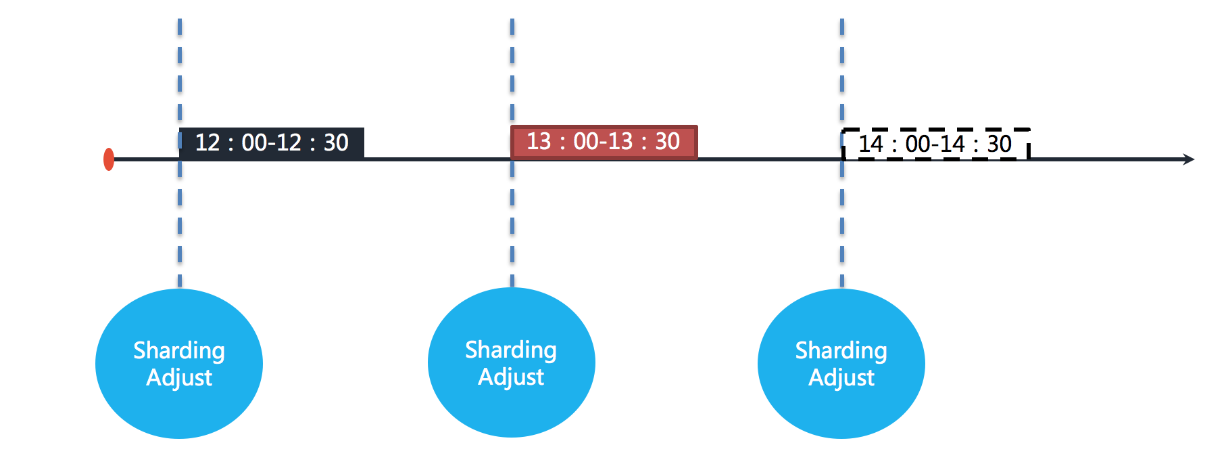
图中表示作业分别于 12:00,13:00 和 14:00 执行。图中显示的当前时间点为 13:00 的作业执行中。
如果作业的其中一个分片服务器在 13:10 的时候宕机,那么剩余的 20 分钟应该处理的业务未得到执行,并且需要在 14:00 时才能再次开始执行下一次作业。也就是说,在不开启失效转移的情况下,位于该分片的作业有 50 分钟空档期。如下如图所示。
在开启失效转移功能之后,ElasticJob 的其他服务器能够在感知到宕机的作业服务器之后,补偿执行该分片作业。如下图所示。
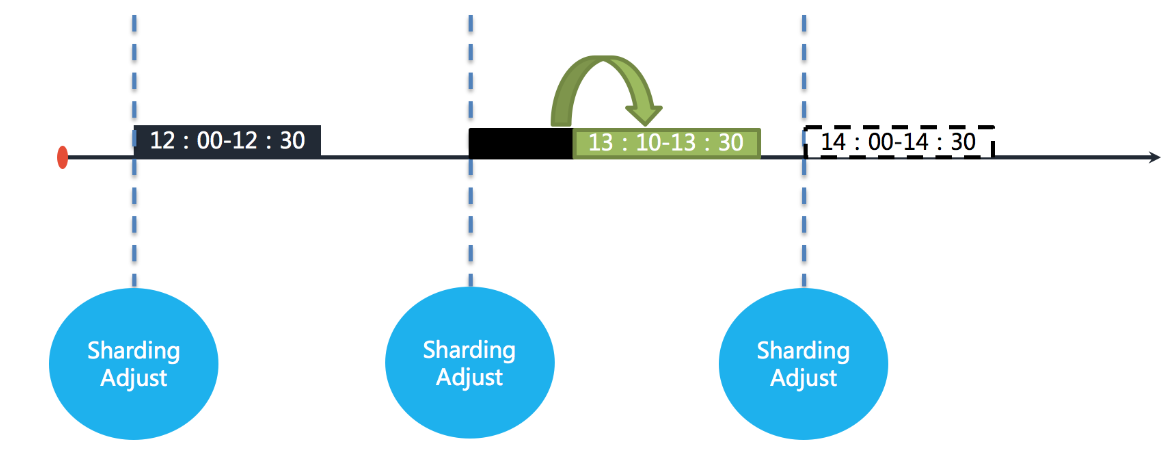
资源充足的情况下,作业仍然能在13:30执行完成。
两种执行机制
-
通知执行
当其他服务器感知到有失效转移的作业需要处理时,且该作业服务器已经完成了本次任务,则会实时的拉取待失效转移的分片项,并开始补偿执行。也称为实时执行。
-
问询执行
作业服务在本次任务执行结束后,会向注册中心问询待执行的失效转移分片项,如果有,则开始补偿执行。也称为异步执行。
适用场景:
开启失效转移功能,ElasticJob 会监控作业每一分片的执行状态,并将其写入注册中心,供其他节点感知。
在一次运行耗时较长且间隔较长的作业场景,失效转移是提升作业运行实时性的有效手段;对于间隔较短的作业,会产生大量与注册中心的网络通信,对集群的性能产生影响。而且间隔较短的作业并未见得关注单次作业的实时性,可以通过下次作业执行的重分片使所有的分片正确执行,因此不建议短间隔作业开启失效转移。
另外需要注意的是,作业本身的幂等性,是保证失效转移正确性的前提。
2.4 错过重触发
是指使逾期未执行的作业在之前作业执行完成之后立即执行。举例说明,若作业以每小时为间隔执行,每次执行耗时 30 分钟。如下如图所示。
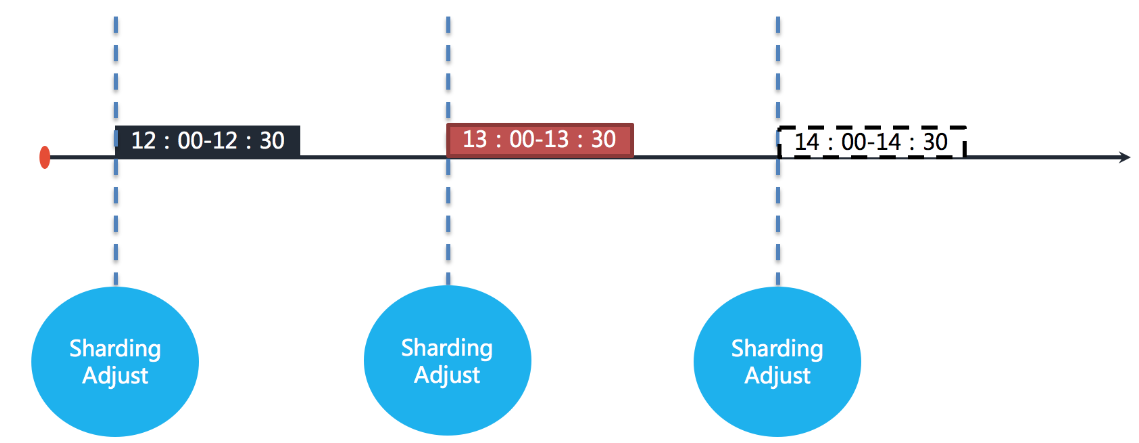
图中表示作业分别于 12:00,13:00 和 14:00 执行。图中显示的当前时间点为 13:00 的作业执行中。
如果 12:00 开始执行的作业在 13:10 才执行完毕,那么本该由 13:00 触发的作业则错过了触发时间,需要等待至 14:00 的下次作业触发。如下图所示。

在开启错过任务重执行功能之后,ElasticJob 将会在上次作业执行完毕后,立刻触发执行错过的作业。在 13:00 和 14:00 之间错过的作业将会重新执行。如下图所示。

适用场景:在一次运行耗时较长且间隔较长的作业场景,错过任务重执行是提升作业运行实时性的有效手段;对于未见得关注单次作业的实时性的短间隔的作业来说,开启错过任务重执行并无必要。
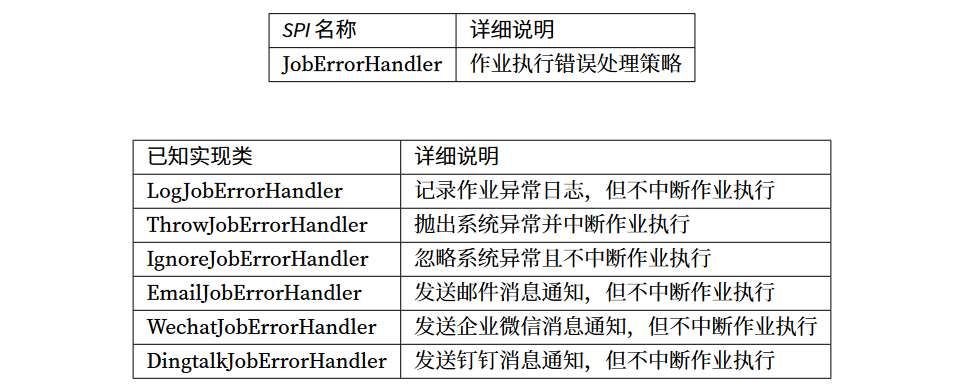
2.5 错误处理策略
提供了一些第三方接入的错误报警的接口:企微、钉钉、邮件
2.6 线程池策略
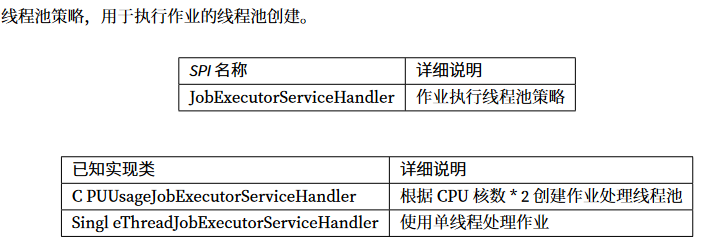
此策略可能导致的问题:
-
问题:
项目分片分了4片,但是测试起来之后只有两片在运行。
-
原因:
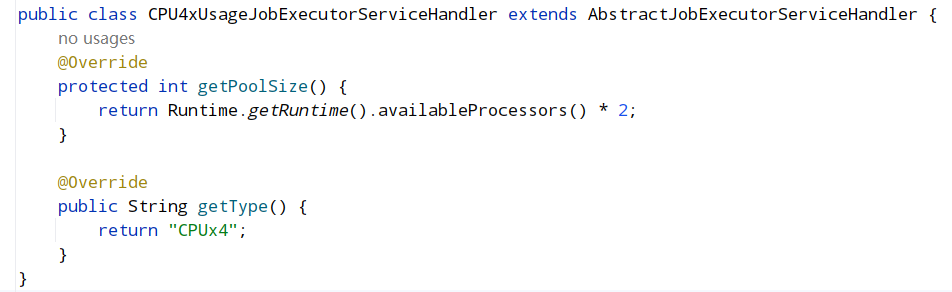
由于项目是在容器中运行的,在分配的时候只分配了一个虚拟CPU,在配置每个任务的时候是有一个配置是jobExecutorServiceHandlerType来配置每个任务的线程池处理策略,默认就是CPU的处理策略(对应实现类就是CPUUsageJobExecutorServiceHandler),每个任务是在线程池中运行的,线程池的分配又是根据CPU的核心数来决定(处理器数量的2倍),所以实际上容器中运行的时候拿的是虚拟的处理器数量,只有一个,线程池初始和最大的容量就是2,但是分片有4片,而且还在运行,所以剩余两片一直等待,没有运行导致的问题。
-
解决:
扩展SPI,文件名就是源码中接口的引用
![image-20230821132050463]()
![image-20230821133452634]()
![image-20230821133649999]()
![image-20230821133754321]()



2.7 事件追踪
ElasticJob 提供了事件追踪功能,可通过事件订阅的方式处理调度过程的重要事件,用于查询、统计和监控。目前提供了基于关系型数据库的事件订阅方式记录事件,开发者也可以通过 SPI 自行扩展。
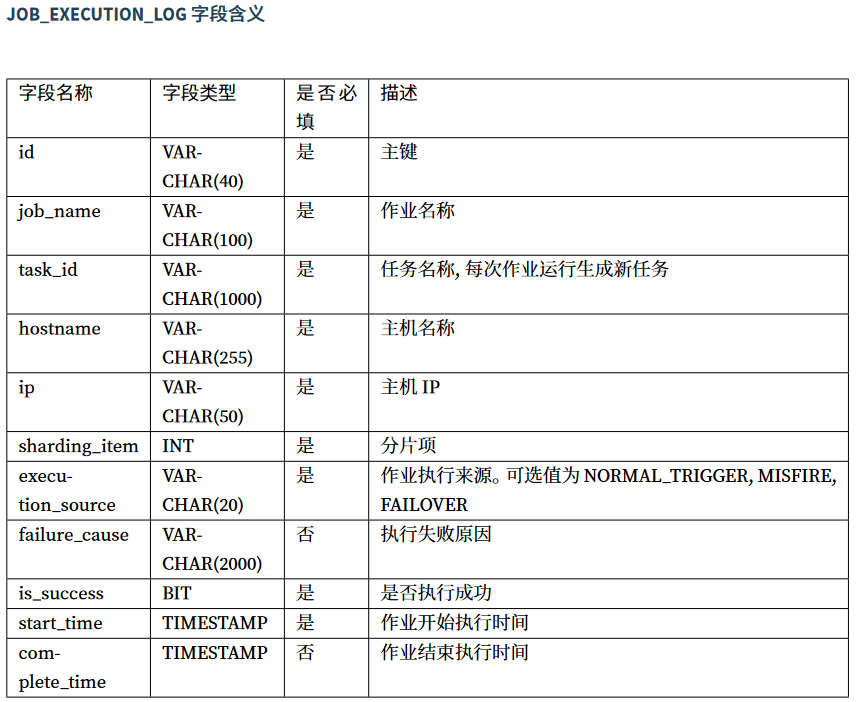
JOB_EXECUTION_LOG 记录每次作业的执行历史。分为两个步骤:
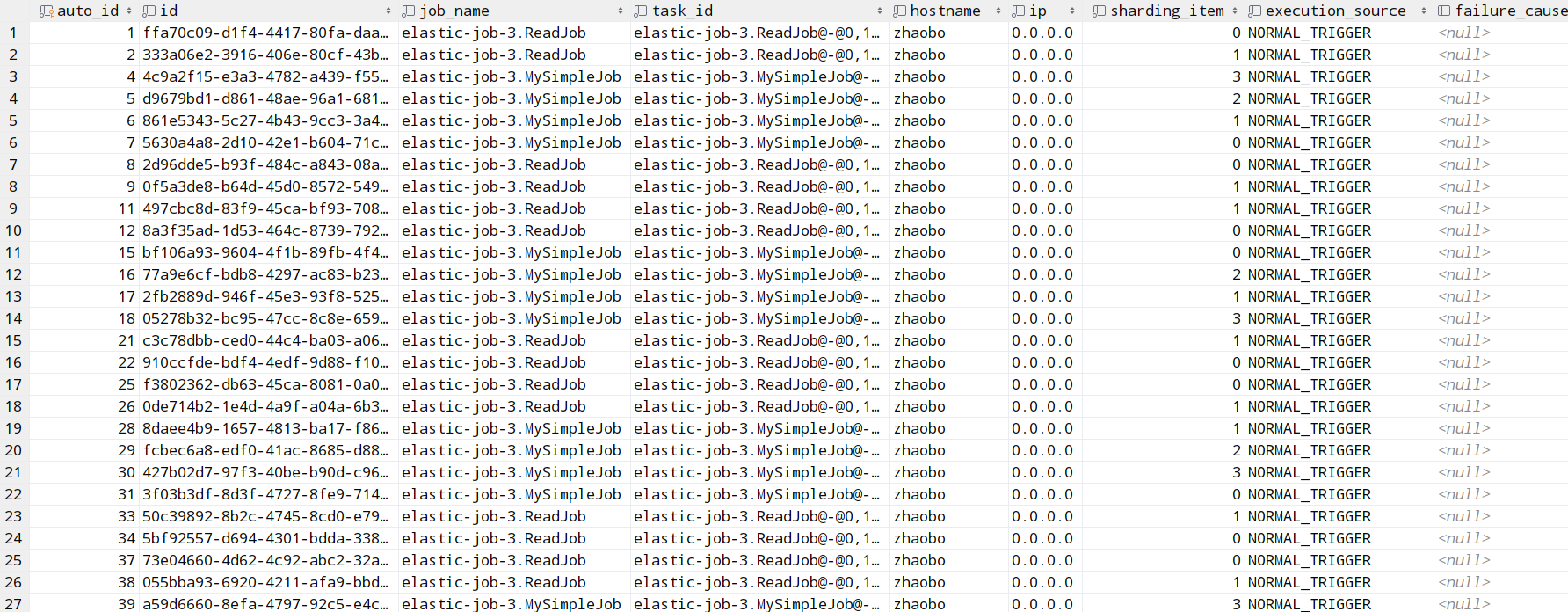
- 作业开始执行时向数据库插入数据,除 failure_cause 和 complete_time 外的其他字段均不为空。
- 作业完成执行时向数据库更新数据,更新 is_success, complete_time 和 failure_cause(如果作业执行失败)。

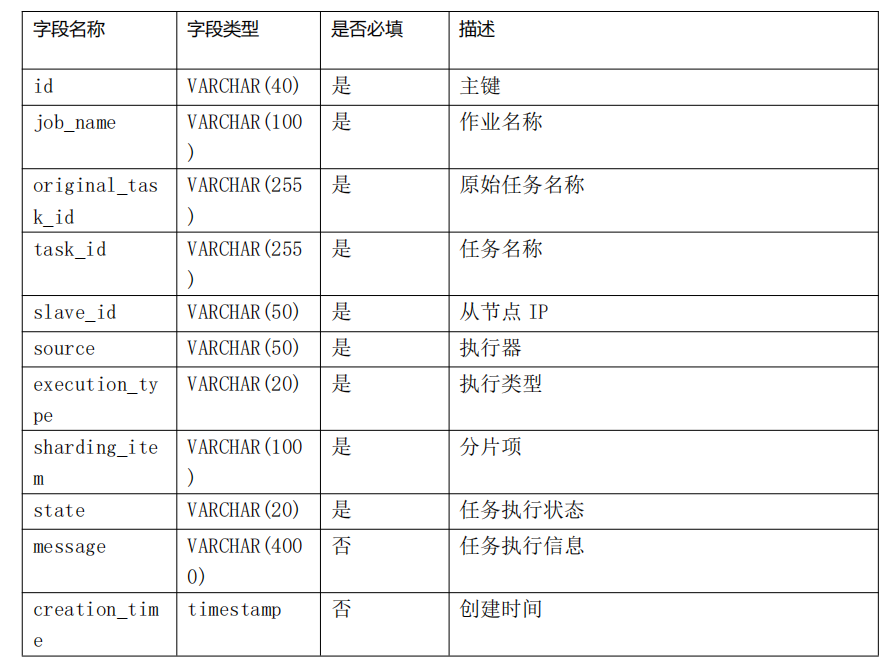
JOB_EXECUTION_LOG表:
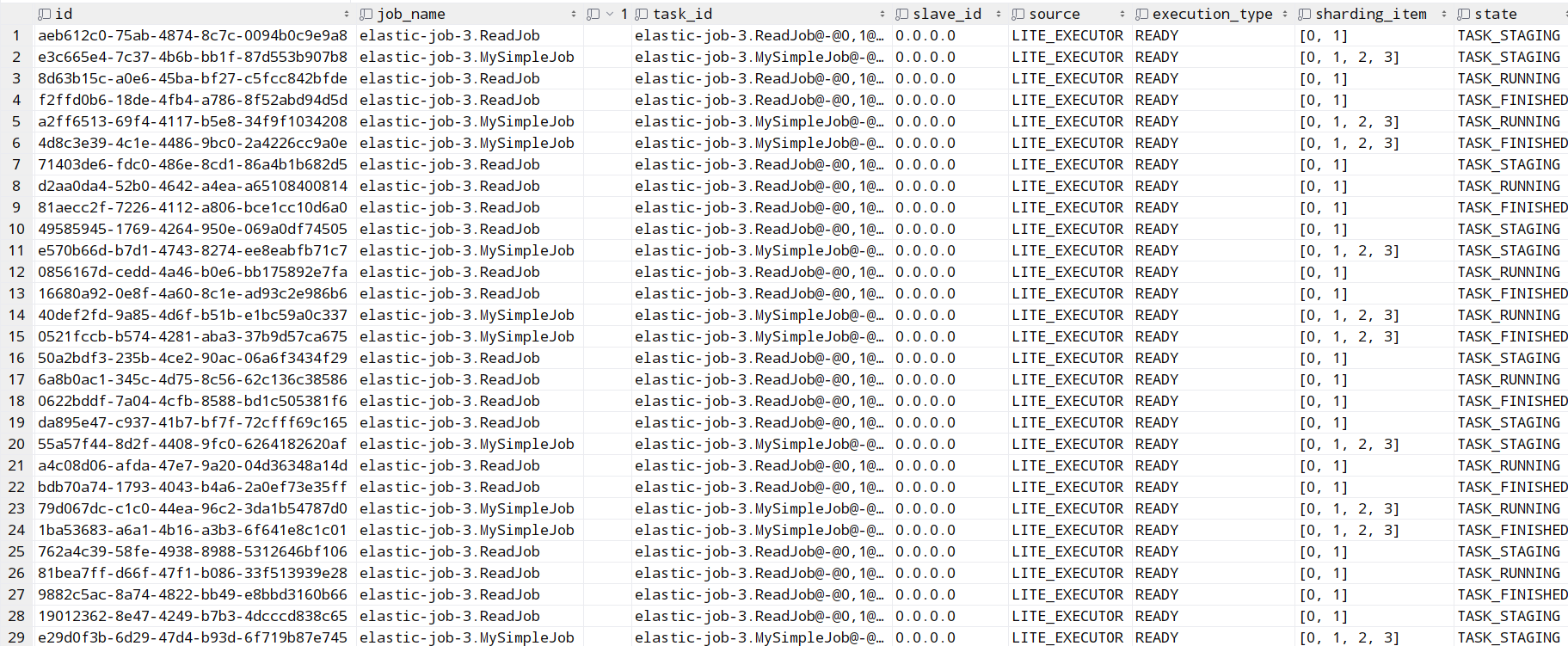
JOB_STATUS_TRACE_LOG表:
2.8 可操作API
Elasticjob提供了JavaAPI,可以通过直接对注册中心进行操作的方式控制作业在分布式环境下的生命周期。根据功能和职责的不同,这些api又分为了配置类API、操作类API、操作分片的API、作业统计API、服务器状态展示API和作业分片状态展示API,这些类都在org.apache.shardingsphere.elasticjob.lite.lifecycle.api这个包下,便于开发人员扩展,我们可以将这些API暴露出来,抽成RESTful接口便于我们在作业执行时动态的控制它的生命周期和修改它的运行参数。

更多api不再列举,详情可以查阅官方文档。
2.9 可视化
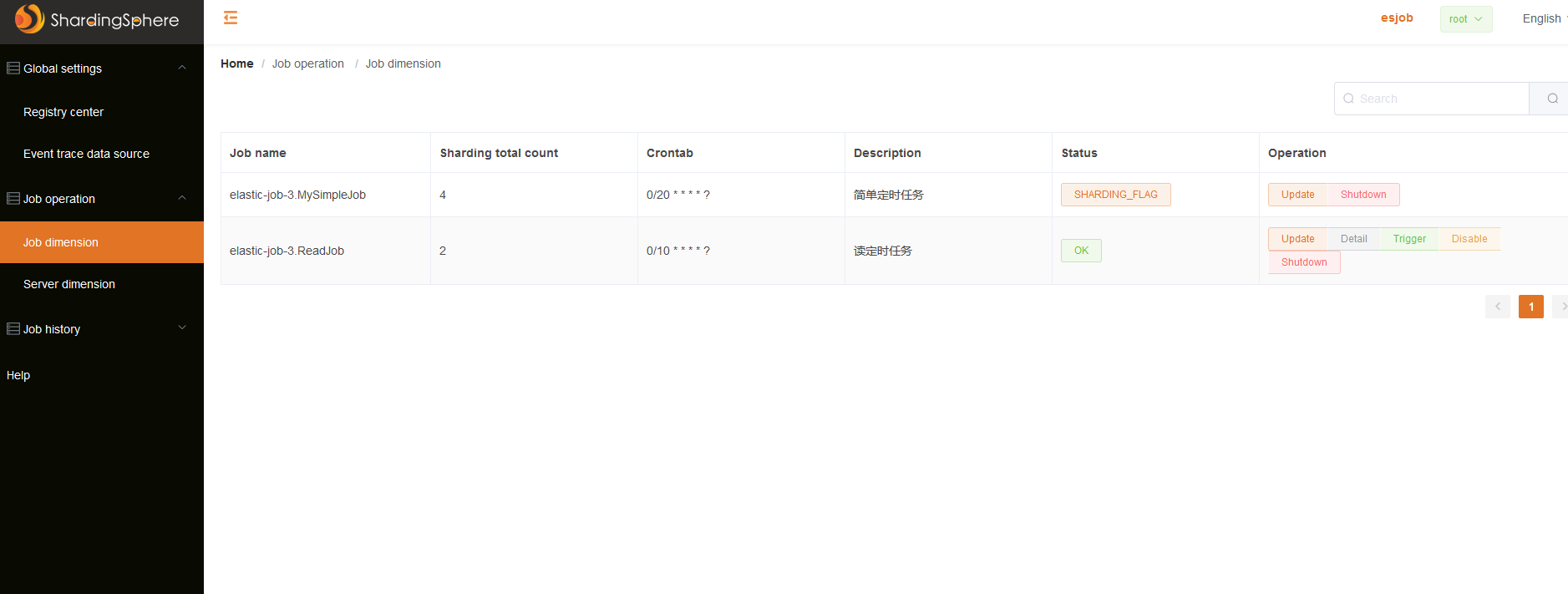
elastic-job提供可视化UI,可以修改作业、操作节点、监控全局连接、轨迹追踪等。
作业维度:在作业维度可以对单个作业手动触发、禁止、下线、修改作业配置。
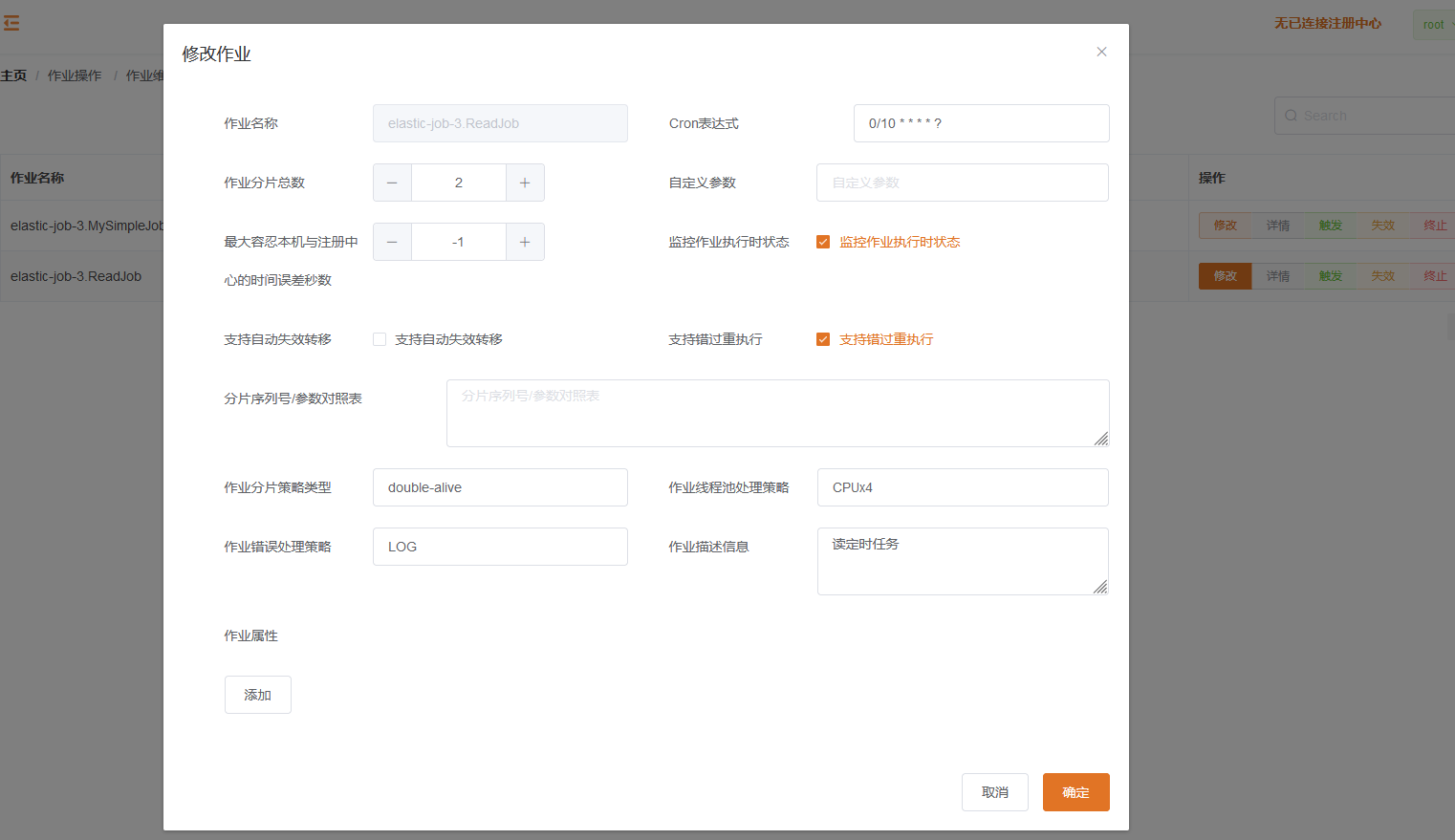
修改作业:
服务维度:在服务可以针对某个节点禁止或是下线

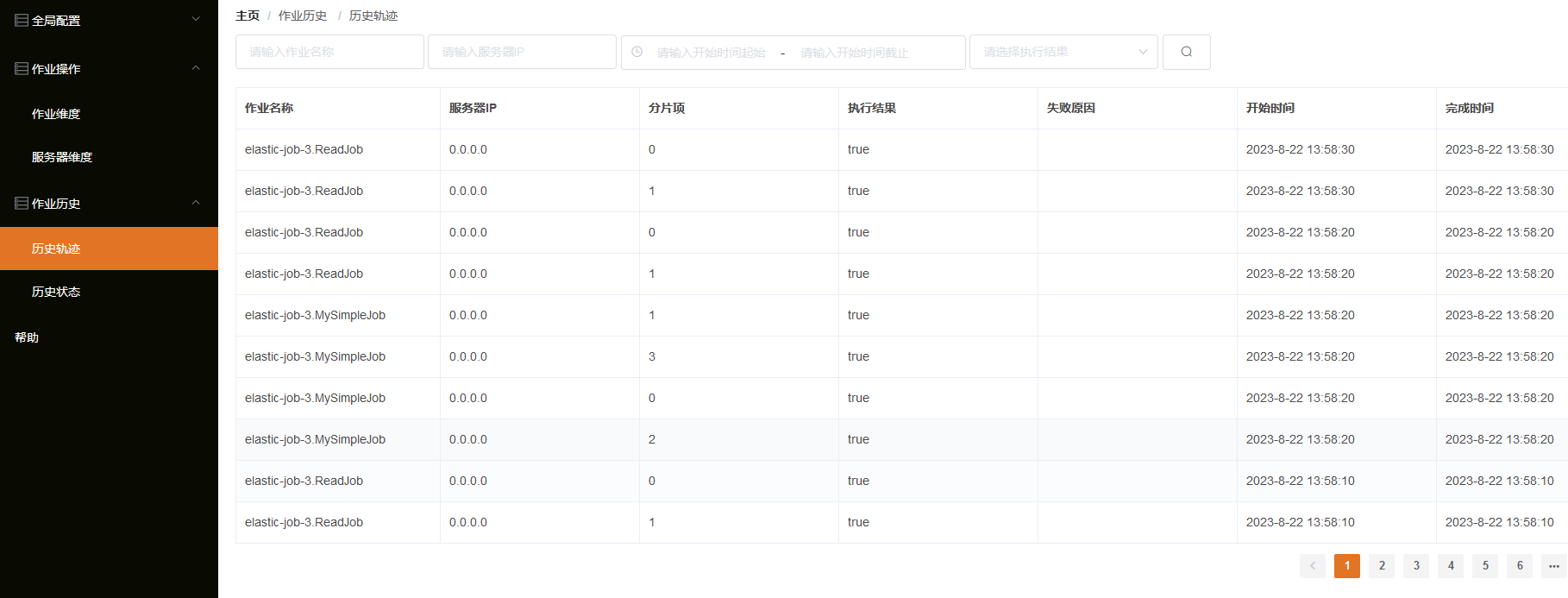
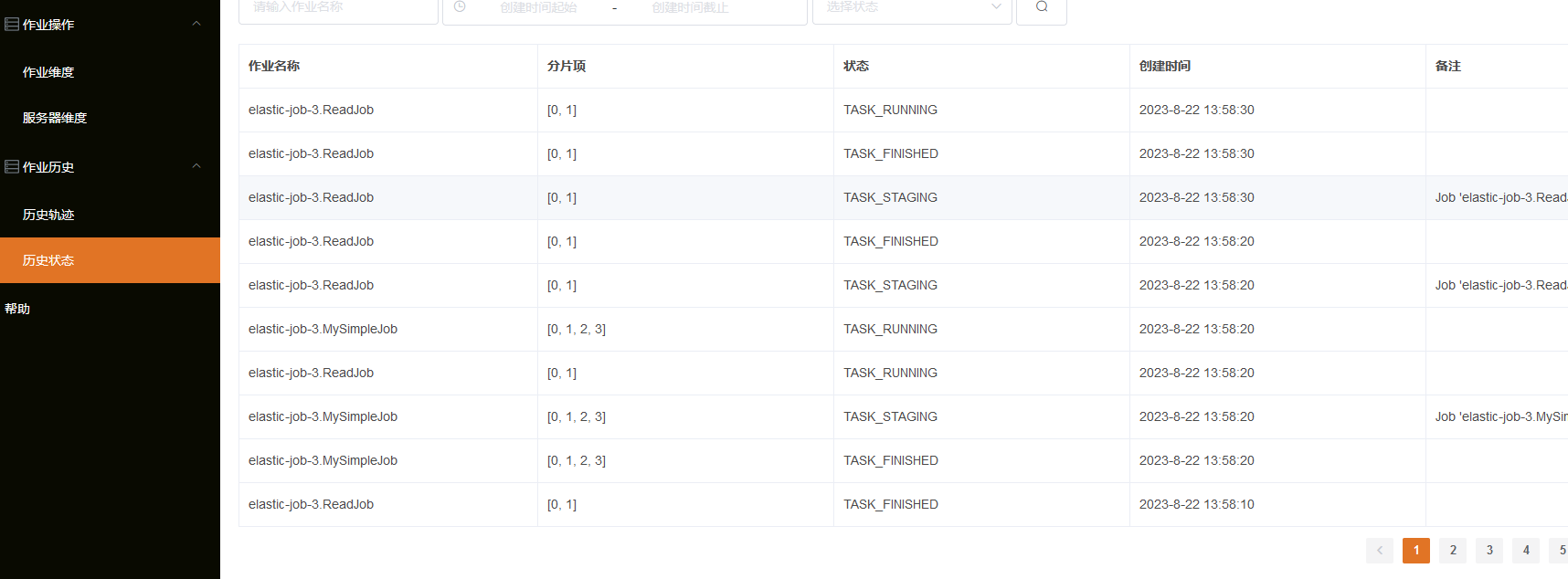
轨迹追踪:可以连接事件追踪的数据库,展示历史轨迹和历史状态信息
参考文献:
本博客内容仅供个人学习使用,禁止用于商业用途。转载需注明出处并链接至原文。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号