一 Hive安装及初体验
一 .Hive安装及初体验
1 .hive简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
1.1直接使用hadoop面临的问题
人员学习成本太高
项目周期要求太短
MapReduce实现复杂查询逻辑开发难度太大
1.2为什么要使用hive
操作接口采用类SQL语法,提供快速开发的能力。
避免了去写MapReduce,减少开发人员的学习成本。
扩展功能很方便。
1.3hive的特点
可扩展->Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
延展性->Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
容错->良好的容错性,节点出现问题SQL仍可完成执行。
2.hive安装
hive只在集群中一个节点安装即可
2.1 安装mysql数据库
2.2 在apache 下载 hive安装包,并解压。
2.3配置hive
2.3.1 配置HIVE HOME环境变量
vi conf/hive-env.sh 配置其中的$hadoop_home
2.3.2 配置元数据信息 vi hive-site.xml


<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password to use against metastore database</description> </property> </configuration>
2.3.3 上传mysql驱动jar包至hive lib目录
2.3.4 启动报错问题
Jline包版本不一致的问题,需要拷贝hive的lib目录中jline.2.12.jar的jar包替换掉hadoop中的 /home/hadoop/app/hadoop-2.6.4/share/hadoop/yarn/lib/jline-0.9.94.jar
2.3.5 启动hive
bin/hive
3.hive使用
使用hive操作hadoop有两种方式。
3.1使用bin/hive
[hadoop@hadoop1 hive]$ bin/hive Logging initialized using configuration in jar:file:/home/hadoop/apps/hive/lib/hive-common-1.2.1.jar!/hive-log4j.properties hive>
3.2使用beeline hive自带
先启动hiveserver2然后使用beeline进行连接
[hadoop@hadoop1 bin]$ ./beeline Beeline version 1.2.1 by Apache Hive beeline> !connect jdbc:hive2://localhost:10000 Connecting to jdbc:hive2://localhost:10000 Enter username for jdbc:hive2://localhost:10000: hadoop(默认使用当前用户作为用户名) Enter password for jdbc:hive2://localhost:10000: (密码默认没有设置为空) Connected to: Apache Hive (version 1.2.1) Driver: Hive JDBC (version 1.2.1) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://localhost:10000>
3.3初步操作
3.3.1创建数据库
0: jdbc:hive2://localhost:10000> create database shizhan01;
3.3.2创建表
0: jdbc:hive2://localhost:10000> create table t_shizhan01(id int ,name string) 0: jdbc:hive2://localhost:10000> row format delimited 0: jdbc:hive2://localhost:10000> fields terminated by ',';
row format delimited:按行读取
fields terminated by ',':字段分隔符使用','分隔
执行完后再hdfs上会生成 /user/hive/warehouse/shizhan01.db/t_shizhan01目录,然后将和表关联的数据放在该目录,然后就可以使用hql操作该数据。
3.3.3将数据上传至/user/hive/warehouse/shizhan01.db/t_shizhan01目录
数据为一个文本文档 格式如下:
1000,zhangsan 2000,lisi 3000,wangwu 4000,baip 5000,lhe
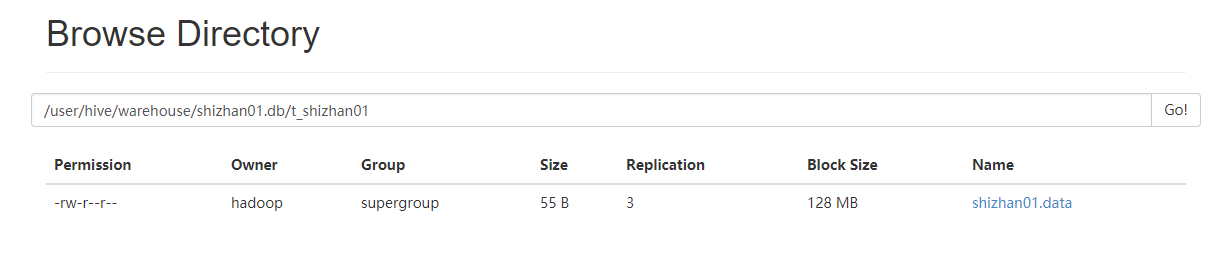
3.3.4上传成功后执行查询
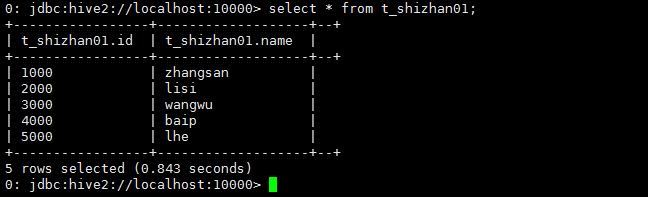
至此 hive初步使用已完成!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号