

数据库实践
一、操作数据库读书笔记
SQLite是一种嵌入式数据库(发音:se k lai t),它的数据库就是一个文件。由于SQLite本身是C写的,而且体积很小,所以,经常被集成到各种应用程序中,甚至在iOS和Android的App中都可以集成。Python就内置了SQLite3,所以,在Python中使用SQLite,不需要安装任何东西,直接使用。
1、在使用SQLite前,我们先要搞清楚几个概念:
(1)表是数据库中存放关系数据的集合,一个数据库里面通常都包含多个表,表和表之间通过外键关联。
(2)要操作关系数据库,首先需要连接到数据库,一个数据库连接称为Connection;
(3)连接到数据库后,需要打开游标,称之为Cursor,游标提供了一种对从表中检索出的数据进行操作的灵活手段,就本质而言,游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。游标总是与一条SQL 选择语句相关联。因为游标由结果集(可以是零条、一条或由相关的选择语句检索出的多条记录)和结果集中指向特定记录的游标位置组成。当决定对结果集进行处理时,必须声明一个指向该结果集的游标。游标对象有以下的操作:
execute() – 执行sql语句
executemany() – 执行多条sql语句
close() – 关闭游标
fetchone() – 从结果中取一条记录,并将游标指向下一条记录
fetchmany() – 从结果中取多条记录
scroll() – 游标滚动
2、在python下使用SQLite数据库,基本按照下面几步:
(1)用sqlite3.connect创建数据库连接,假设连接对象为conn;
(2)如果该数据库操作不需要返回结果,就直接用conn.execute查询,根据数据库事务隔离级别的不同,可能修改数据库需要conn.commit;
(3)如果需要返回查询结果则用conn.cursor创建游标对象cur, 通过cur.execute查询数据库,用cur.fetchall/cur.fetchone/cur.fetchmany返回查询结果;
(4)关闭cur, conn。
3、实例:
# 导入SQLite数据库模块 import sqlite3 # 连接到SQLite数据库 # 数据库文件是userdata.db,如果文件不存在,会自动在当前目录创建 con = sqlite3.connect("userdata.db") # 创建一个Cursor游标 cur = con.cursor() # 存储数据 cur.execute("insert into userinfo values ('%s','%s','%s');" % (iddata, iddata + '.mat', iddata + '.jpg')) con.commit() #提交事务 # 读取数据 cur.execute("select * from userinfo;") #从表中查找 results = cur.fetchall() #获得查询结果集 # 删除数据 cur = con.cursor() cur.execute("delete from userinfo where id = '%s';" % (iddata)) con.commit() #提交事务 # 关闭游标 cur.close() # 关闭数据库连接 con.close()
二、爬取中国大学排名
1、代码:
import sqlite3 from pandas import DataFrame import re class SQL_method: ''' function: 可以实现对数据库的基本操作 ''' def __init__(self, dbName, tableName, data, columns, COLUMNS, Read_All=True): ''' function: 初始化参数 dbName: 数据库文件名 tableName: 数据库中表的名称 data: 从csv文件中读取且经过处理的数据 columns: 用于创建数据库,为表的第一行 COLUMNS: 用于数据的格式化输出,为输出的表头 Read_All: 创建表之后是否读取出所有数据 ''' self.dbName = dbName self.tableName = tableName self.data = data self.columns = columns self.COLUMNS = COLUMNS self.Read_All = Read_All def creatTable(self): ''' function: 创建数据库文件及相关的表 ''' # 连接数据库 connect = sqlite3.connect(self.dbName) # 创建表 connect.execute("CREATE TABLE {}({})".format(self.tableName, self.columns)) # 提交事务 connect.commit() # 断开连接 connect.close() def destroyTable(self): ''' function: 删除数据库文件中的表 ''' # 连接数据库 connect = sqlite3.connect(self.dbName) # 删除表 connect.execute("DROP TABLE {}".format(self.tableName)) # 提交事务 connect.commit() # 断开连接 connect.close() def insertDataS(self): ''' function: 向数据库文件中的表插入多条数据 ''' # 连接数据库 connect = sqlite3.connect(self.dbName) # 插入多条数据 connect.executemany("INSERT INTO {} VALUES(?,?,?,?,?,?,?,?,?,?,?,?,?)".format(self.tableName), self.data) #for i in range(len(self.data)): # connect.execute("INSERT INTO university VALUES(?,?,?,?,?,?,?,?,?,?,?,?,?)", data[i]) # 提交事务 connect.commit() # 断开连接 connect.close() def getAllData(self): ''' function: 得到数据库文件中的所有数据 ''' # 连接数据库 connect = sqlite3.connect(self.dbName) # 创建游标对象 cursor = connect.cursor() # 读取数据 cursor.execute("SELECT * FROM {}".format(self.tableName)) dataList = cursor.fetchall() # 断开连接 connect.close() return dataList def searchData(self, conditions, IfPrint=True): ''' function: 查找特定的数据 ''' # 连接数据库 connect = sqlite3.connect(self.dbName) # 创建游标 cursor = connect.cursor() # 查找数据 cursor.execute("SELECT * FROM {} WHERE {}".format(self.tableName, conditions)) data = cursor.fetchall() # 关闭游标 cursor.close() # 断开数据库连接 connect.close() if IfPrint: self.printData(data) return data def deleteData(self, conditions): ''' function: 删除数据库中的数据 ''' # 连接数据库 connect = sqlite3.connect(self.dbName) # 插入多条数据 connect.execute("DELETE FROM {} WHERE {}".format(self.tableName, conditions)) # 提交事务 connect.commit() # 断开连接 connect.close() def printData(self, data): print("{1:{0}^3}{2:{0}<11}{3:{0}<4}{4:{0}<4}{5:{0}<5}{6:{0}<5}{7:{0}^5}{8:{0}^5}{9:{0}^5}{10:{0}^5}{11:{0}^5}{12:{0}^6}{13:{0}^5}".format(chr(12288), *self.COLUMNS)) for i in range(len(data)): print("{1:{0}<4.0f}{2:{0}<10}{3:{0}<5}{4:{0}<6}{5:{0}<7}{6:{0}<8}{7:{0}<7.0f}{8:{0}<8}{9:{0}<7.0f}{10:{0}<6.0f}{11:{0}<9.0f}{12:{0}<6.0f}{13:{0}<6.0f}".format(chr(12288), *data[i])) def run(self): try: # 创建数据库文件 self.creatTable() print(">>> 数据库创建成功!") # 保存数据到数据库 self.insertDataS() print(">>> 表创建、数据插入成功!") except: print(">>> 数据库已创建!") # 读取所有数据 if self.Read_All: self.printData(self.getAllData()) def get_data(fileName): ''' function: 读取获得大学排名的数据 并 将结果返回 ''' data = [] # 打开文件 f = open(fileName, 'r', encoding='utf-8') # 按行读取文件 for line in f.readlines(): # 替换掉其中的换行符和百分号 替换百分号是为了方便之后的排序和运算 line = line.replace('\n', '') line = line.replace('%','') # 将字符串按照 ',' 分割为列表 line = line.split(',') for i in range(len(line)): # 使用 异常处理 避开 出现中文无法转换 的错误 try: # 将空值填充为 0 if line[i] == '': line[i] = '0' # 将数字转换为数值 line[i] = eval(line[i]) except: continue data.append(tuple(line)) # EN_columns、CH_columns 分别为 用于数据库创建、数据的格式化输出 EN_columns = "Rank real, University text, Province text, Grade real, SourseQuality real, TrainingResult real, ResearchScale real, \ ReserchQuality real, TopResult real, TopTalent real, TechnologyService real, Cooperation real, TransformationResults real" CH_columns = ["排名", "学校名称", "省市", "总分", "生涯质量", "培养结果(%)", "科研规模", "科研质量", "顶尖成果", "顶尖人才", "科技服务", "产学研合作", "成果转化"] return data[1:], EN_columns, CH_columns if __name__ == "__main__": # =================== 设置和得到基本数据 =================== fileName = "E:/python实验/中国大学排名.csv" data, EN_columns, CH_columns = get_data(fileName) dbName = "university.db" tableName = "university" # ================= 创建一个SQL_method对象 ================== SQL = SQL_method(dbName, tableName, data, EN_columns, CH_columns, False) # =================== 创建数据库并保存数据 =================== SQL.run() # =================== 在数据库中查找数据项 =================== # 查找记录并输出结果 print(">>> 查找数据项(University = '广东技术师范大学') :") SQL.searchData("University = '广东技术师范大学'", True) # ================= 在数据库中筛选数据项并排序 ================== # 将选取广东省的数据 并 对科研规模大小排序 print("\n>>> 筛选数据项并按照科研规模排序(Province = '广东省') :") SQL.searchData("Province = '广东省' ORDER BY ResearchScale", True) # =============== 对数据库中的数据进行重新排序操作 ================ # 定义权值 Weight = [0.3, 0.15, 0.1, 0.1, 0.1, 0.1, 0.05, 0.05, 0.05] value, sum = [], 0 # 获取 Province = '广东省' 的所有数据 sample = SQL.searchData("Province = '广东省'", False) # 按照权值求出各个大学的总得分 for i in range(len(sample)): for j in range(len(Weight)): sum += sample[i][4+j] * Weight[j] value.append(sum) sum = 0 # 将结果通过 pandas 的 DataFrame 方法组成一个二维序列 university = [university[1] for university in sample] uv, tmp = [], [] for i in range(len(university)): tmp.append(university[i]) tmp.append(value[i]) uv.append(tmp) tmp = [] df = DataFrame(uv, columns=list(("大学", "总分"))) df = df.sort_values('总分') df.index = [i for i in range(1, len(uv)+1)] # 输出结果 print("\n>>> 筛选【广东省】的大学并通过权值运算后重排名的结果:\n", df) # ===================== 在数据库中删除数据项 ===================== SQL.deleteData("Province = '北京市'") SQL.deleteData("Province = '广东省'") SQL.deleteData("Province = '山东省'") SQL.deleteData("Province = '山西省'") SQL.deleteData("Province = '江西省'") SQL.deleteData("Province = '河南省'") print("\n>>> 数据删除成功!") SQL.printData(SQL.getAllData()) # ====================== 在数据库中删除表 ======================== SQL.destroyTable() print(">>> 表删除成功!")
2、结果
(1)我们学校的排名(没排名!很尴尬@-@,应排在爬取的数量太少了

(2)广东省大学排名
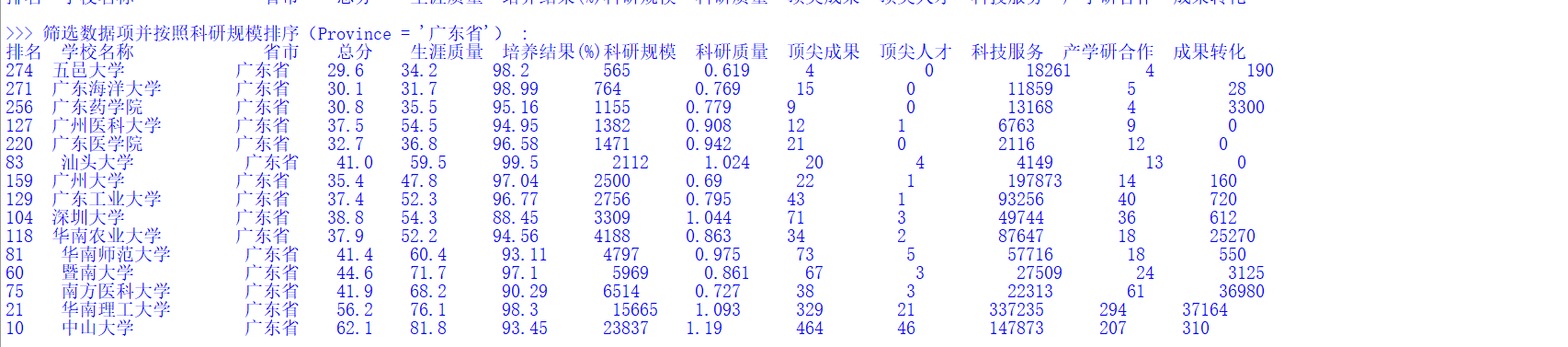
(3)广东省大学并通过权值运算后重排名的结果:

